我们生活在一个数据以不可预测的方式增长的世界中,我们需要以有效的方式存储这些数据,无论是结构化数据还是非结构化数据。 分布式计算系统提供了优于集中式计算系统的广泛的优点。 这里,数据以分布式方式存储,其中几个节点作为服务器。

GlusterFS存储
在分布式文件系统中不再需要元数据服务器的概念。 在分布式文件系统中,它提供了在不同服务器之间分离的所有文件的公共视点。 这些存储服务器上的文件/目录以正常方式访问。
例如,文件/目录的权限可以设置为通常的系统权限模型,即所有者,组和其他。 对文件系统的访问基本上取决于特定协议如何被设计为工作在相同的。
什么是GlusterFS?
GlusterFS是定义在用户空间中使用的分布式文件系统,在用户空间即文件系统(FUSE)。 它是一个基于软件的文件系统,它考虑到自己的灵活性功能。
看看下图,它示意性地表示了分层模型中GlusterFS的位置。 默认情况下,GlusterFS将使用TCP协议。
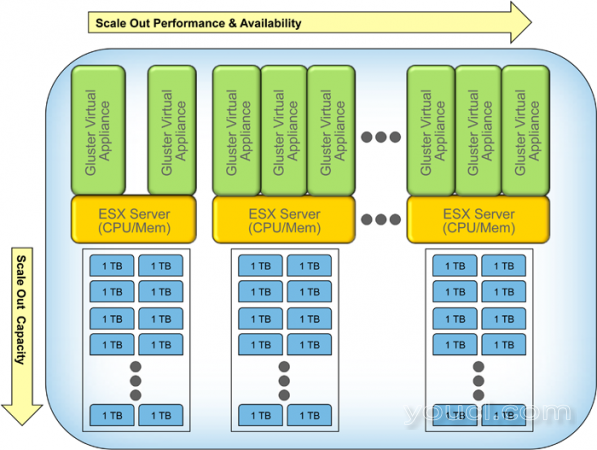
GlusterFS设计
GlusterFS的优点
- 创新 -它消除了元数据,并能dramtically提高性能,这将有助于我们统一的数据和对象。
- 弹性 -适应于经济增长和减少数据的大小。
- 线性扩展 -它具有可用性高数量和超越。
- 简单 -在用户空间运行时,它易于管理和独立于内核。
什么使Gluster在其他分布式文件系统中脱颖而出?
- 出售 -缺乏一个元数据服务器提供了一个更快的文件系统。
- 实惠的 -它可以部署在商品硬件。
- 灵活的 -正如我刚才所说,GlusterFS是一个纯软件的文件系统。 这里的数据存储在本地文件系统,如ext4,xfs等。
- 开源 -目前GlusterFS是由红帽公司是一家十亿美元的开源公司,作为维护红帽存储的一部分。
GlusterFS中的存储概念
- 砖 -砖基本上是指的是值得信赖的存储池之间共享任何目录。
- 值得信赖的存储池 -为这些共享文件/目录,这是基于对设计方案的集合。
- 块存储 -它们是通过该数据跨系统中的块的形式被移动设备。
- 集群 -在红帽存储,两个群集和值得信赖的存储池传达的基础上定义的协议存储服务器协作的含义相同。
- 分布式文件系统 -的文件系统,其中数据被分布在,用户可以在不知道该文件的实际位置访问该文件不同的节点。 用户没有体验到远程访问的感觉。
- FUSE -这是一个可加载的内核模块,它允许用户在不涉及任何内核代码创建上面的内核文件系统。
- glusterd - glusterd是GlusterFS管理守护这是将在整个时间每当服务器处于活动状态运行文件系统的骨干。
- POSIX -便携式操作系统接口(POSIX)是由IEEE作为在应用程序可编程接口(API)的形式的解决方案,以Unix的变体之间的相容性定义的标准的家庭。
- RAID -独立磁盘(RAID)冗余阵列是给通过冗余提高存储可靠性的技术。
- 亚体 -在同一译者由至少处理后砖。
- 译者 -译者是一段代码,它执行从安装点的用户启动的基本动作。 它连接一个或多个子卷。
- 音量 -一个体积是砖的逻辑集合。 所有操作都基于用户创建的不同类型的卷。
不同类型的卷
还允许在这些基本卷类型中表示不同类型的卷和组合,如下所示。
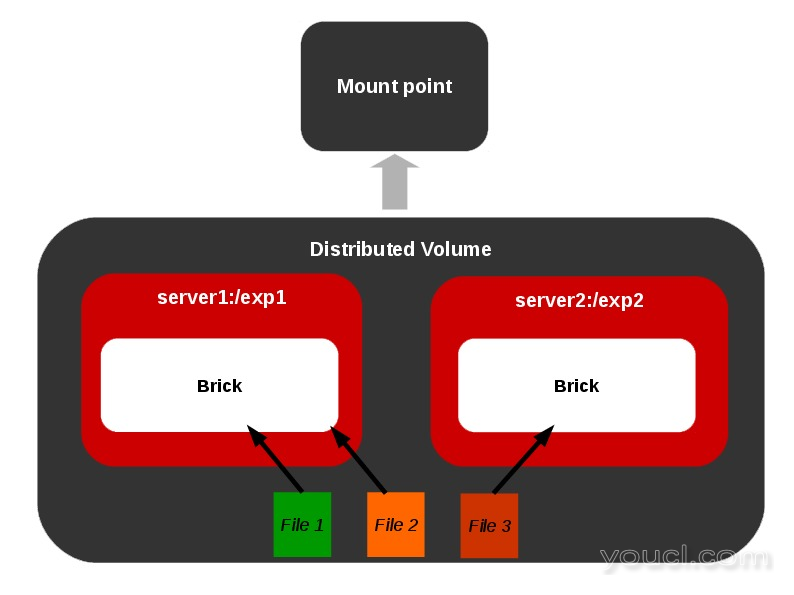
分布式卷
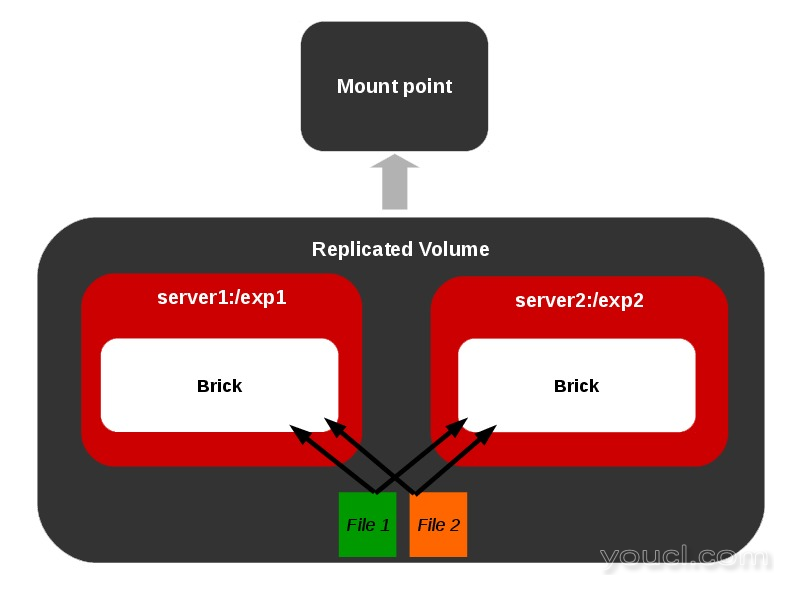
复制卷
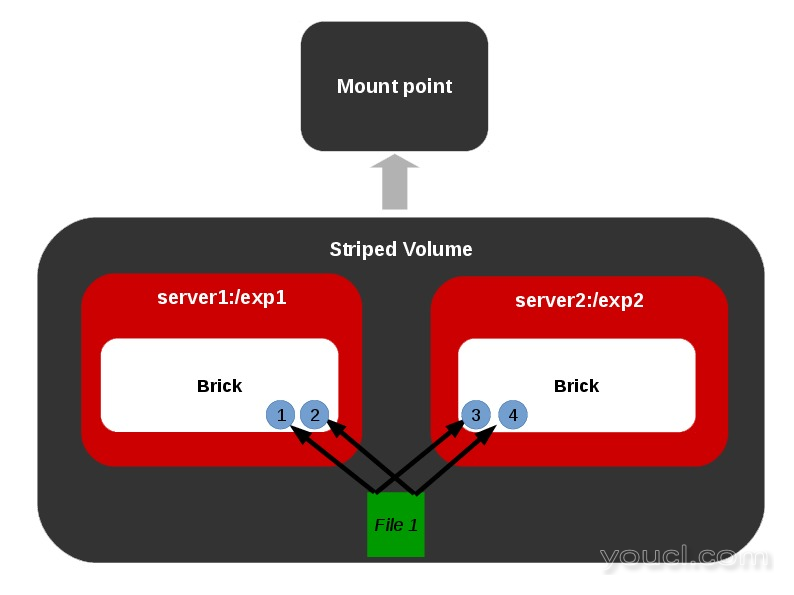
条纹卷
分布式复制卷
分布式复制卷的表示。
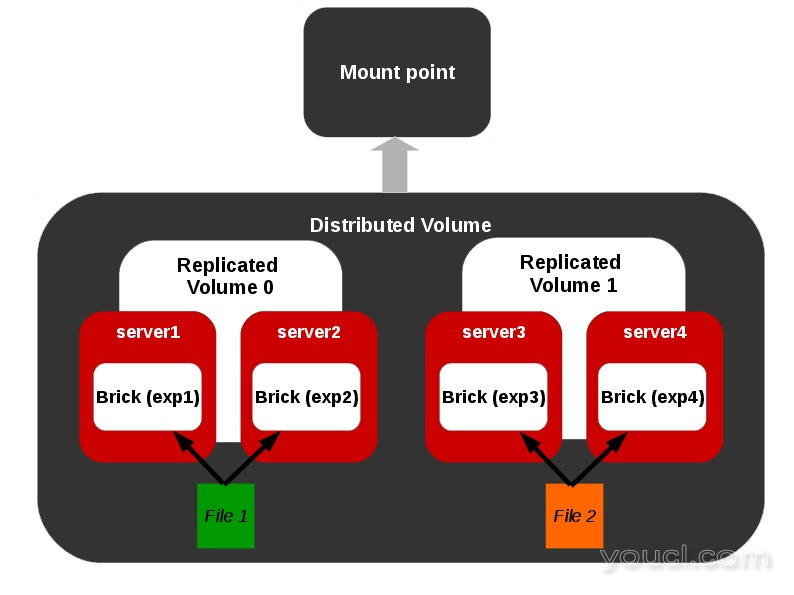
分布式复制卷
在RHEL / CentOS和Fedora中安装GlusterFS
在本文中,我们将首次安装和配置GlusterFS以实现高可用性存储。 为此,我们使用两台服务器来创建卷并在它们之间复制数据。
步骤:1至少有两个节点
- 在两个节点安装CentOS 6.5(或任何其他操作系统)。
- 设置主机名命名为“ 服务器1”和“ 服务器2”。
- 工作网络连接。
- 名为“/数据/砖 ”两个节点上存储磁盘。
第2步:启用EPEL和GlusterFS存储库
上都安装GlusterFS服务器之前,我们需要启用EPEL和GlusterFS存储库,以满足外部依赖性。 使用以下链接在两个系统下安装和启用epel存储库。
接下来,我们需要在两台服务器上启用GlusterFs存储库。
# wget -P /etc/yum.repos.d http://download.gluster.org/pub/gluster/glusterfs/LATEST/EPEL.repo/glusterfs-epel.repo
第3步:安装GlusterFS
在两台服务器上安装软件。
# yum install glusterfs-server
启动GlusterFS管理守护程序。
# service glusterd start
现在检查守护程序的状态。
# service glusterd status
示例输出
service glusterd start service glusterd status glusterd.service - LSB: glusterfs server Loaded: loaded (/etc/rc.d/init.d/glusterd) Active: active (running) since Mon, 13 Aug 2012 13:02:11 -0700; 2s ago Process: 19254 ExecStart=/etc/rc.d/init.d/glusterd start (code=exited, status=0/SUCCESS) CGroup: name=systemd:/system/glusterd.service ├ 19260 /usr/sbin/glusterd -p /run/glusterd.pid ├ 19304 /usr/sbin/glusterfsd --xlator-option georep-server.listen-port=24009 -s localhost... └ 19309 /usr/sbin/glusterfs -f /var/lib/glusterd/nfs/nfs-server.vol -p /var/lib/glusterd/...
第4步:配置SELinux和iptables
打开“ 的/ etc / sysconfig中/ SELinux的 ”,并更改了SELinux要么在服务器上既“ 宽松 ”或“ 已禁用 ”模式。 保存并关闭文件。
# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targeted
接下来,清除两个节点中的iptables,或者需要允许通过iptables访问其他节点。
# iptables -F
第5步:配置信任的池
运行在“ 服务器1”下面的命令。
gluster peer probe server2
运行“ 服务器2”以下命令。
gluster peer probe server1
注意 :当池已连接,只有受信任的用户可能会探索新的服务器到这个池中。
第6步:设置GlusterFS卷
在这两个server1和server2。
# mkdir /data/brick/gv0
创建卷在任何单个服务器上并启动卷。 在这里,我已经采取了“ 服务器1”。
# gluster volume create gv0 replica 2 server1:/data/brick1/gv0 server2:/data/brick1/gv0 # gluster volume start gv0
接下来,确认音量的状态。
# gluster volume info
注意 :如果在情况卷未启动时,错误消息被下'/无功/日志/ glusterfs'登录的一个或两个服务器。
第7步:验证GlusterFS卷
安装卷下“ 到/ mnt”的目录。
# mount -t glusterfs server1:/gv0 /mnt
现在,您可以在安装点上创建,编辑文件作为文件系统的单个视图。
GlusterFS的特点
- 自我修复 -如果任何一个复制卷砖的下降和用户修改其他砖内的文件,自动自我修复守护进程会尽快砖接下来的时间到了进入行动,并在发生交易停机时间相应地同步。
- 平衡 -如果我们添加新砖到现有的卷,其中,大量的数据被先前居住,我们可以执行重新平衡操作向所有砖块包括新增加的砖之间的数据分发。
- 地理复制 -它提供的数据后备用于灾难恢复。 这里有主和从卷的概念。 所以如果主机是下来整体的数据可以通过从机访问。 此功能用于在地理上分隔的服务器之间同步数据。 初始化地理复制会话需要一系列gluster命令。
这里,是以下屏幕抓取显示地理复制模块。
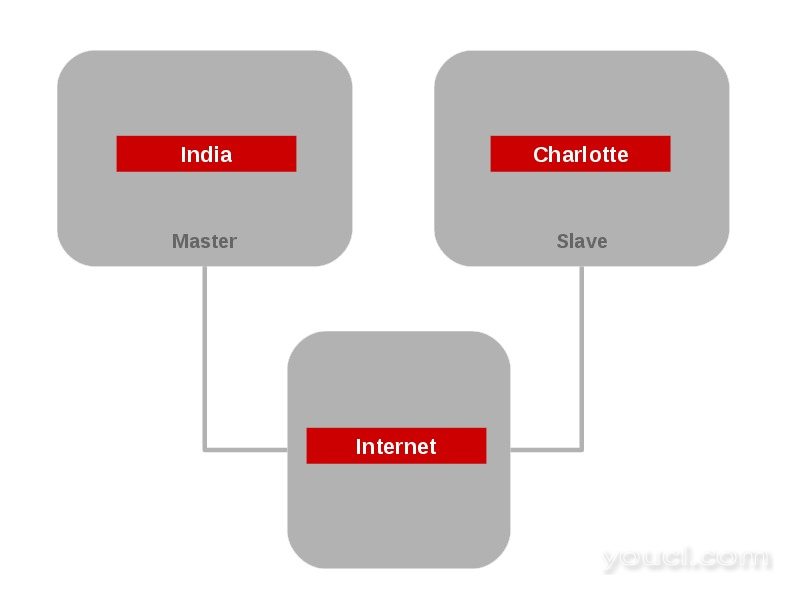
地理复制
参考链接
这就是现在! 保持更新的像特性的详细描述自我修复和重新平衡 ,地域复制等在我即将到来的文章。







