介绍
备份在任何种类的生产或开发环境中都非常重要。 不可预见的情况可能需要几天或几个月的生产力。 如果您尚未备份文件,则可能会丢失整个项目。
虽然有很多备份重要数据的方法,但也有一种方法可通过DigitalOcean控制面板和API:快照。
快照复制整个VPS的映像,并将其存储在DigitalOcean服务器上。 它们与“备份”功能不同,后者提供自动备份,可以通过勾选备份框进行选择。 您可以根据快照重新部署服务器或旋转新的Droplet。 从2016年10月开始,快照每月每GB的价格为0.05美元,基于文件系统中的利用空间量。
在本文中,我们将讨论如何使用DigitalOcean快照作为备份您的环境的方法。 我们将简要介绍对服务器进行快照的手动方式,然后通过API和cron作业以自动方式快速完成此操作。
如何使用手动快照
使用DigitalOcean控制面板可以轻松地为服务器创建快速一次性备份。
从命令行关闭Droplet开始。 虽然可以对实时系统进行快照,但关闭电源可以确保文件系统处于一致状态。 你可以通过在连接到Droplet时在终端中键入这样的命令来安全地执行此操作:
sudo poweroff
这比使用控制面板中的“电源循环”选项更安全,因为该选项更像是硬复位。
接下来,在主要的“Droplets”页面中点击你的Droplet的名称:

在下一个屏幕中,单击顶部标有“快照”的选项卡。 输入快照的名称,然后按“拍摄快照”按钮以启动快照:
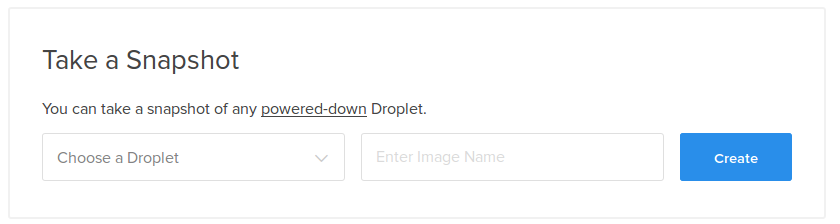
您的快照将启动。 快照过程完成后,您的服务器将重新启动。
如何通过API快照
DigitalOcean提供了一个API ,使您可以通过命令行或编程接口访问控制面板的电源。
在本节中,我们将演示的基本理念用curl ,这是一个简单的命令行实用程序访问网站。
创建API密钥
在开始之前,您必须设置对您的帐户的API访问权限。 您必须在控制面板中执行此操作。 点击顶部导航栏的“API”部分:

你将被带到一般的API接口。 在这里,您可以生成API令牌,注册开发人员应用程序,查看授权的应用程序,并阅读API文档。
点击页面顶部的“生成新令牌”:
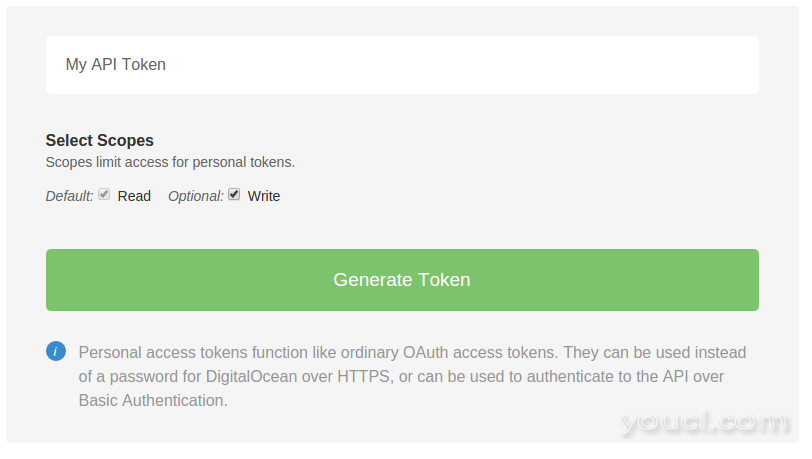
为令牌提供一个名称,并确定其对您帐户的访问权限级别。 对于本教程,您将需要具有读取和写入访问权限:
您现在可以使用API令牌:

复制和API令牌粘贴到一个安全的位置,因为它不会再显示给你。 如果丢失此密钥,则必须重新创建另一个令牌,并使用前一个令牌调整任何脚本或应用程序的值。
您将需要通过API访问您的帐户的API令牌。
现在你有了这条信息,你已经准备好了我们的第一个测试。
测试API访问
操作所需的一般语法curl ,我们将使用本指南是:
curl -X HTTP_METHOD "requested_url"
我们将使用的方法是“GET”,如API文档中所示。 我们要求的网址会有一些变化:
https://api.digitalocean.com/v2/command
让我们使用AAABBB作为这些下一个命令的示例客户端ID的示例API令牌。
因此,查看API文档,如果您想要请求“/ drops”,它会返回您帐户中的所有活动Droplet,您可以形成如下所示的URL:
https://api.digitalocean.com/v2/droplets
由于我们试图从命令行执行此操作,我们将使用上面指定的格式的curl。 我们还必须在授权头中包含API令牌。 该命令变为:
curl -X GET -H "Content-Type: application/json" \
-H "Authorization: Bearer AAABBB" \
"https://api.digitalocean.com/droplets"
{"droplets":[{"id":123456,"name":"irssi","memory":1024,"vcpus":1,"disk":30,"locked":false,"status":"active","kernel":{"id":1221,"name":"Ubuntu 14.04 x64 vmlinuz-3.13.0-24-generic (1221)","version":"3.13.0-24-generic"},"created_at":"2014-04-20T23:47:21Z","features":["backups","private_networking","virtio"],"backup_ids":[8000333,8185675,8381528,8589151,8739369],"snapshot_ids":[],"image":{"id":3240036,"name":"Ubuntu 14.04 x64","distribution":"Ubuntu","slug":null,"public":false,"regions":["nyc1","ams1","sfo1","nyc2","ams2","sgp1","lon1","nyc2"],"created_at":"2014-04-18T15:59:36Z","min_disk_size":20},"size_slug":"1gb","networks":{"v4":[{"ip_address":"XX.XXX.XXX.XXX","netmask":"255.255.0.0","gateway":"10.128.1.1","type":"private"},{"ip_address":"XX.XXX.XXX.XXX","netmask":"255.255.240.0","gateway":"107.170.96.1","type":"public"}],"v6":[]},"region":{"name":"New York 2","slug":"nyc2","sizes":[],"features":["virtio","private_networking","backups"],"available":null}},
. . .
我们可以通过其DropletID识别单个Droplet。 它保存在每个Droplet返回的JSON字符串的“id”字段中。 它也可以在控制面板的Droplet页面上的URL的末尾使用:

为了获得关于单个Droplet的信息,我们可以发出这样的命令。 我们将假设DropletID是123456:
curl -X GET -H "Content-Type: application/json" \
-H "Authorization: Bearer AAABBB" \
"https://api.digitalocean.com/v2/droplets/123456"
{"droplets":[{"id":123456,"name":"irssi","memory":1024,"vcpus":1,"disk":30,"locked":false,"status":"active","kernel":{"id":1221,"name":"Ubuntu 14.04 x64 vmlinuz-3.13.0-24-generic (1221)","version":"3.13.0-24-generic"},"created_at":"2014-04-20T23:47:21Z","features":["backups","private_networking","virtio"],"backup_ids":[8000333,8185675,8381528,8589151,8739369],"snapshot_ids":[],"image":{"id":3240036,"name":"Ubuntu 14.04 x64","distribution":"Ubuntu","slug":null,"public":false,"regions":["nyc1","ams1","sfo1","nyc2","ams2","sgp1","lon1","nyc2"],"created_at":"2014-04-18T15:59:36Z","min_disk_size":20},"size_slug":"1gb","networks":{"v4":[{"ip_address":"XX.XXX.XXX.XXX","netmask":"255.255.0.0","gateway":"10.128.1.1","type":"private"},{"ip_address":"XX.XXX.XXX.XXX","netmask":"255.255.240.0","gateway":"107.170.96.1","type":"public"}],"v6":[]},"region":{"name":"New York 2","slug":"nyc2","sizes":[],"features":["virtio","private_networking","backups"],"available":null}}}
然后我们可以通过发出命令到那个特定的Droplet进一步。 假设我们已经从服务器内安全地关闭Droplet,我们可以发出snapshot命令,如下所示:
curl -X POST -H 'Content-Type: application/json' \
-H 'Authorization: Bearer AAABBB' \
-d '{"type":"snapshot","name":"Name for New Snapshot"}' \
"https://api.digitalocean.com/v2/droplets/123456/actions"
{"action": {"id": 99999999, "status": "in-progress", "type": "snapshot", "started_at": "2014-11-14T16:34:39Z", "completed_at": null, "resource_id": 332233, "resource_type": "droplet", "region": "nyc3"}}
这将返回一个JSON字符串,其中包含您刚刚请求的快照的事件ID。 我们可以使用它来使用“events /”请求来查询事件是否已成功完成:
curl -X GET -H "Content-Type: application/json" \
-H "Authorization: Bearer $AAABBB" \
"https://api.digitalocean.com/v2/actions/123456"
{"action":{"id":99999999,"status":"completed","type":"snapshot","started_at":"2014-12-08T21:03:01Z","completed_at":"2014-12-08T21:05:32Z","resource_id":332233,"resource_type":"droplet","region":"nyc3"}}
如您所见,此活动被标记为“已完成”。 我们刚刚从命令行创建了第一个快照!
使用脚本自动执行快照备份
正如你在最后一节中看到的,可以使用API从命令行控制很多。 但是,手动执行此操作不仅有点麻烦,它不能解决我们自动化快照的问题。 事实上,使用这些方法需要更多的工作,而不是在界面中点击和点击。
然而,能够通过API访问数据的好处在于我们可以将这个功能添加到脚本中。 脚本是有利的,不仅因为它加速了所有的手动查询和输入,而且还因为我们可以将其设置为从命令行自动运行。
在这个设置中,我们将创建一个简单的Ruby脚本来备份我们的Droplet。 然后,我们将通过添加一个cronjob来自动化脚本,以预定的间隔快照我们的服务器。
您可以设置脚本和cronjob在本地机器上运行,假设您可以访问Ruby解释器和cron,或从另一个Droplet。 我们将使用一个Ubuntu 12.04Droplet快照我们的其他服务器。 创建一个普通用户 ,如果你还没有这样做的话。
创建脚本
首先,如果我们的系统上没有安装Ruby,我们需要下载Ruby。 我们可以很容易地通过安装Ruby版本管理器并告诉它给我们最新的稳定版本:
\curl -sSL https://get.rvm.io | bash -s stable --ruby
我们将被要求我们的sudo密码来安装必要的辅助工具并设置一些系统属性。 这将安装rvm和最新的稳定版本的Ruby。
安装后,我们可以通过运行以下命令来获取rvm脚本:
source ~/.rvm/scripts/rvm
接下来,我们需要创建一个名为snapshot.rb在你喜欢的文本编辑器:
cd ~
nano snapshot.rb
在里面,您可以粘贴以下脚本文件:
#!/usr/bin/env ruby
require 'rest_client'
require 'json'
$api_token = ENV['DO_TOKEN']
$baseUrl = "https://api.digitalocean.com/v2/"
$headers = {:content_type => :json, "Authorization" => "Bearer #{$api_token}"}
class ResponseError < StandardError; end
def droplet_on?(droplet_id)
url = $baseUrl + "droplets/#{droplet_id}"
droplet = get(url)['droplet']
droplet['status'] == 'active'
end
def power_off(droplet_id)
url = $baseUrl + "droplets/#{droplet_id}/actions"
params = {'type' => 'power_off'}
post(url, params)
end
def snapshot(droplet_id)
url = $baseUrl + "droplets/#{droplet_id}/actions"
params = {'type' => 'snapshot', 'name' => "Droplet #{droplet_id} " + Time.now.strftime("%Y-%m-1")}
post(url, params)
end
def get(url)
response = RestClient.get(url, $headers){|response, request, result| response }
puts response.code
if response.code == 200
JSON.parse(response)
else
raise ResponseError, JSON.parse(response)["message"]
end
end
def post(url, params)
response = RestClient.post(url, params.to_json, $headers){|response, request, result| response }
if response.code == 201
JSON.parse(response)
else
raise ResponseError, JSON.parse(response)["message"]
end
end
droplets = ARGV
droplets.each do |droplet_id|
puts "Attempting #{droplet_id}"
begin
if droplet_on?(droplet_id)
power_off(droplet_id)
while droplet_on?(droplet_id) do
sleep 10
end
puts "Powered Off #{droplet_id}"
sleep 10
end
snapshot(droplet_id)
puts "Snapshotted #{droplet_id}"
rescue ResponseError => e
puts "Error Snapshotting #{droplet_id} - #{e.message}"
end
end
保存并在完成后关闭文件。
现在我们可以通过输入以下命令使此文件可执行:
chmod 755 snapshot.rb
这个脚本的工作原理是分配我们的客户ID和API密钥称为环境变量DO_CLIENT_ID和DO_API_KEY分别。 然后,我们通过脚本列出DropletID号。 然后,脚本将运行ID列表,关闭所有活动的Droplet,并快照它们。
假设我们使用了以前使用的相同设置,我们可以通过键入以下命令来运行此命令:
DO_TOKEN="AAABBB" ./snapshot.rb 123456
这将快照只有一Droplet。 可以在第一个之后添加更多DropletID,用空格分隔:
DO_TOKEN="AAABBB" ./snapshot.rb 123456 111111 222222 333333
使用Cron自动化脚本
现在我们有我们的脚本文件在工作顺序,我们可以设置它自动运行通过使用cron实用程序。
因为我们的API调用和脚本不需要root权限,我们应该在本地用户的crontab中进行设置。 不要使用位于系统crontab文件/etc ,因为你可以改变的cron是否收到更新被消灭。
首先,我们应该看看我们的用户是否已经有一个crontab:
crontab -l
如果crontab被打印出来,我们应该备份它,以防我们以后要恢复我们的更改:
cd
crontab -l > crontab.bak
现在我们已经备份了crontab,让我们看看rvm在哪里安装了我们的Ruby。 Cron没有一个环境的概念,所以我们需要给它完整的路径,我们的脚本和ruby本身:
which ruby
/home/your_user/.rvm/rubies/ruby-2.1.0/bin/ruby
您的可能略有不同。 保存此路径,以便可以将其输入到crontab中。
现在是编辑crontab的时候了。 输入:
crontab -e
如果这是您第一次以此用户身份运行crontab,系统将提示您选择编辑器。 如果您没有其他列出的选项之一,nano是一个安全的选择。
然后,您将被删除到编辑会话,并且该文件将预加载解释如何格式化cron命令的注释。
Cron命令按以下方式格式化:
minute hour day_of_month month day_of_week command_to_run
您可以在任何不想指定的间隔位置放置“*”。 Cron将这个字段的所有值读取。 所以如果我们想在每天早上3:10运行一个命令,我们可以添加一个条目:
10 03 * * * command
如果我们想在每个月的第一天中午运行一个命令,我们可以改为键入:
00 12 1 * * command
为了我们的目的,我们将假设我们要在每个星期日和星期四上午3:30运行快照备份。
我们可以通过在crontab中键入一行来实现这一点,如下所示:
30 03 * * 0,4 DO_TOKEN="AAABBB" /home/your_user/.rvm/rubies/ruby-2.1.0/bin/ruby /home/your_user/snapshot.rb drop_id1 drop_id2 ... drop_idx
通常,通过将命令设置为从现在起几分钟,然后查看命令是否成功运行,检查该命令是否有效。 例如,如果现在是下午6点10分,我们可以添加一条看起来像这样的行来检查命令:
14 18 * * * DO_TOKEN="AAABBB" /home/your_user/.rvm/rubies/ruby-2.1.0/bin/ruby /home/your_user/snapshot.rb drop_id1 drop_id2 ... drop_idx
这将在4分钟后运行命令。 一旦验证命令运行成功(创建快照),您可以将其编辑回您希望保留的计划。
结论
有多种备份方式,并且分层您的备份策略将提供在发生问题的最佳覆盖。 使用DigitalOcean快照是提供图像级备份的一种简单方法。
如果您自动执行此过程,则重要的是管理保存到您的帐户的快照数量。 如果您不定期检查帐户并删除陈旧的快照,则可以快速堆叠相当多的帐户中不需要的图片。 请尽量在较新的工作快照到位时删除旧快照。







