介绍
MongoDB是一个NoSQL文档数据库系统,可以横向扩展,并通过键值系统实现数据存储。 MongoDB是Web应用程序和网站的常用选择,易于实现和编程访问。
MongoDB通过称为“分片”的技术实现缩放。 分片是跨不同服务器写入数据以分散读取和写入负载和数据存储要求的过程。
在前面的教程中,我们讨论了如何在一个Ubuntu 12.04安装VPS的MongoDB 。 我们将使用它作为跳转点来讨论如何在多个不同的节点上实现分片。
MongoDB Sharding拓扑
分片通过三个单独的组件来实现。 每个部分执行特定的功能:
- 配置服务器 :每生产分片实施必须正好包含三个配置服务器。 这是为了确保冗余和高可用性。
配置服务器用于存储将请求的数据与包含它的分片链接的元数据。 它组织数据,以便可以可靠和一致地检索信息。
- 查询路由器 :查询路由器是您的应用程序实际连接到机器。 这些机器负责与配置服务器通信,以确定请求的数据存储在哪里。 然后它访问并返回来自适当分片的数据。
每个查询路由器运行“mongos”命令。
- 碎片服务器 :碎片是负责实际的数据存储操作。 在生产环境中,单个分片通常由副本集而不是单个机器组成。 这是为了确保在主分片服务器脱机的情况下仍可访问数据。
实现复制集不在本教程的范围之内,因此我们将我们的分片配置为单机而不是副本集。 您可以轻松地修改这个,如果你想配置副本集为自己的配置。
初始设置
如果你在上面关注,你可能注意到这个配置需要相当多的机器。 在本教程中,我们将配置一个示例分片集群,其中包含:
- 3配置服务器(在生产环境中需要)
- 2查询路由器(最少1个)
- 4碎片服务器(最少2个必需)
这意味着您将需要九个VPS实例来跟随。 实际上,这些功能中的一些可以重叠(例如,您可以在与配置服务器相同的VPS上运行查询路由器),您只需要一个查询路由器和至少两个分片服务器。
我们将超过这个最小值,以演示添加每个类型的多个组件。 为了清晰和简单,我们还将所有这些组件视为离散机器。
设置初始基本图像
上手, 安装并在Ubuntu配置初始的MongoDB服务器使用本指南。 我们将使用它来引导我们的其余分片组件。
为第一个服务器完成该教程后,请使用以下命令关闭实例:
sudo shutdown -h now
现在,我们将拍摄这个配置的Droplet的快照,并使用它来旋转我们的其他VPS实例。 虽然可以拍摄正在运行的系统的快照,但关闭电源可确保文件系统处于一致状态。 快照每月每GB费用为0.05美元,基于文件系统中使用的空间量,因此最好在完成后删除快照。
在DigitalOcean控制面板中,选择Droplet。 点击“快照”选项卡。 输入快照名称,然后单击“拍摄快照”:
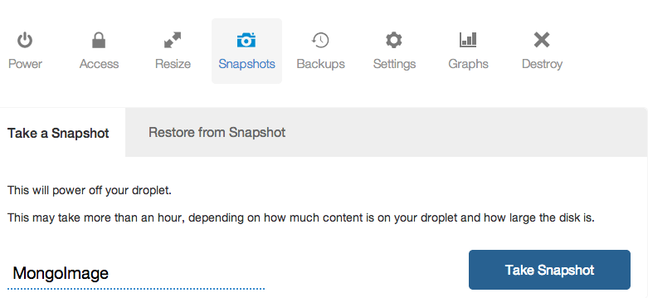
将拍摄您的快照,并重新启动初始服务器。
基于快照启动VPS实例
现在我们有一个通过快照过程保存的图像,我们可以使用它作为其余的MongoDB组件的基础。
从控制面板,单击“创建”按钮。 输入一个名称,描述您的Droplet在分片配置中将具有的目的:
选择Droplet尺寸和区域。 最好为所有组件选择相同的区域。
在“选择图像”部分下,单击“我的图像”选项卡,然后选择您刚刚创建的MongoDB快照。
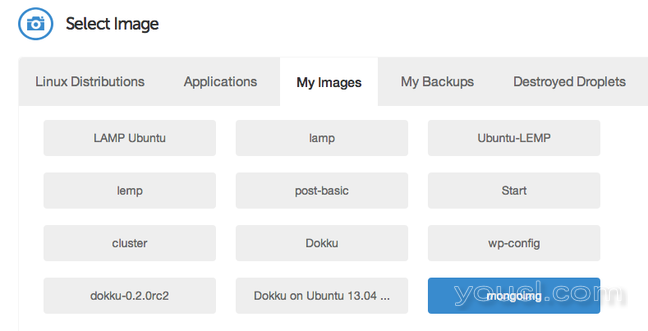
添加所需的任何SSH密钥,然后选择要使用的设置。 单击“创建Droplet”以启动您的新VPS实例。
对每个分片组件重复此步骤。 记住,要完全遵循本教程(不必要,但演示),您需要3个配置服务器,2个查询服务器和4个分片服务器。
配置每个组件的DNS子域条目(可选)
MongoDB文档建议您使用DNS可解析名称而不是特定IP地址来引用所有组件。 这很重要,因为它允许您更改服务器或重新部署某些组件,而不必重新启动与其关联的每个服务器。
为了易于使用,我建议您给每个服务器自己的子域在您想要使用的域。 您可以使用本指南以了解如何使用DigitalOcean的控制面板设置DNS子域 。
为了本教程的目的,我们将组件称为可在这些子域访问:
配置服务器
- config0.example.com
- config1.example.com
- config2.example.com
查询路由器
- query0.example.com
- query1.example.com
碎片服务器
- shard0.example.com
- shard1.example.com
- shard2.example.com
- shard3.example.com
如果您没有设置子域名,您仍然可以跟进,但您的配置不会那么强大。 如果你想走这条路线,只需用你的Droplet的IP地址替换子域规范。
初始化配置服务器
必须设置的第一个组件是配置服务器。 在配置查询路由器或分片之前,这些必须处于在线和可操作状态。
以root身份登录到第一个配置服务器。
我们需要做的第一件事是创建一个数据目录,这是配置服务器将存储关联位置和内容的元数据的地方:
mkdir /mongo-metadata
现在,我们只需要使用适当的参数启动配置服务器。 提供的配置服务器的服务被称为mongod 。 此组件的默认端口号是27019 。
我们可以使用以下命令启动配置服务器:
mongod --configsvr --dbpath /mongo-metadata --port 27019
服务器将开始输出信息,并将开始侦听来自其他组件的连接。
在其他两个配置服务器上完全重复此过程。 所有三个服务器的端口号应该相同。
配置查询路由器实例
此时,您应该让所有三个配置服务器都运行并侦听连接。 它们必须在继续操作之前运行。
以root身份登录到您的第一个查询路由器。
我们需要做的第一件事是停止mongodb在这种情况下如果进程已经运行。 查询路由器使用与主MongoDB进程冲突的数据锁:
service mongodb stop
接下来,我们需要使用特定的配置字符串来启动查询路由器服务。 配置的每个查询路由器的配置字符串必须完全相同(包括参数的顺序)。 它由每个配置服务器的地址和其操作的端口号组成,用逗号分隔。
他们查询路由器服务被称为mongos 。 这个过程的默认端口号码是27017 (但在配置的端口号是指配置服务器的端口号,这是27019默认情况下)。
最终结果是查询路由器服务以如下字符串启动:
mongos --configdb config0.example.com:27019,config1.example.com:27019,config2.example.com:27019
您的第一个查询路由器应该开始连接到三个配置服务器。 在其他查询路由器上重复这些步骤。 请记住, mongodb服务之前,必须在命令中输入停止。
另外,请记住, 相同的指令必须用于启动每个查询的路由器。 否则将导致错误。
向群集添加碎片
现在我们配置了配置服务器和查询路由器,我们可以开始向集群添加实际的分片服务器。 这些分片将保存总数据的一部分。
以root用户身份登录到其中一个分片服务器。
正如我们开始提到的,在本指南中,我们将只使用单个机器分片而不是副本集。 这是为了简洁和简单的示范。 在生产环境中,强烈建议使用副本集,以确保数据的完整性和可用性。 要在MongoDB中配置副本集 ,请按照本指南。
要实际将碎片添加到集群,我们将需要通过查询路由器,现在配置为作为我们与集群的接口。 我们可以通过连接到任何查询路由器像这样做:
mongo --host query0.example.com --port 27017
这将连接到适当的查询路由器并打开一个mongo提示符。 我们将从此提示中添加所有的碎片服务器。
要添加我们的第一个分片,请键入:
sh.addShard( "shard0.example.com:27017" )
然后,您可以在此相同的界面添加您剩余的碎片Droplet。 您不需要单独登录每个分片服务器。
sh.addShard( "shard1.example.com:27017" ) sh.addShard( "shard2.example.com:27017" ) sh.addShard( "shard3.example.com:27017" )
如果要配置生产集群并完成复制集,则必须指定复制集名称和复制集成员,以将每个集合建立为不同的分片。 语法看起来像这样:
sh.addShard( "rep_set_name/rep_set_member:27017" )
如何为数据库集合启用分片
MongoDB将信息组织到数据库中。 在每个数据库内,数据通过“集合”进一步划分。 集合类似于传统关系数据库模型中的表。
在本节中,我们将使用查询路由器再次运行。 如果您仍然连接到查询路由器,您可以使用您在上一部分中使用的相同的mongo命令再次访问它:
mongo --host config0.example.com --port 27017
在数据库级别启用分片
我们将首先在数据库级别启用分片。 要做到这一点,我们将创建一个名为(适当地)测试数据库test_db 。
要创建这个数据库,我们只需要改变它。 它将被标记为我们当前的数据库,并在我们首次输入数据时动态创建:
use test_db
我们可以通过键入以下内容来检查我们当前是否正在使用刚刚创建的数据库:
db
test_db
我们可以通过键入以下内容查看所有可用数据库:
show dbs
您可能会注意到,我们刚创建的数据库不会显示。 这是因为它没有数据,所以它不是很现实。
我们可以通过发出以下命令在此数据库上启用分片:
sh.enableSharding("test_db")
同样,如果我们进入了show dbs命令,我们将不会看到我们的新的数据库。 但是,如果我们切换到config是自动生成的,并发出一个数据库find()命令,我们的新的数据库将返回:
use config
db.databases.find()
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "test_db", "partitioned" : true, "primary" : "shard0003" }
您的数据库将显示与show dbs命令时MongoDB中增加了一些数据到新的数据库。
在集合级别启用分片
现在我们的数据库被标记为可用于分片,我们可以在特定集合上启用分片。
在这一点上,我们需要决定一个分片策略。 分片的工作原理是将数据组织成基于指定为特定领域的不同类别shard key在它存储的文件。 它将所有具有匹配的分片键的文档放在同一个分片上。
例如,如果你的数据库是在一个公司存储的员工和片键是基于最喜欢的颜色,MongoDB的将会把所有与职工的blue在喜欢的色域在一个碎片。 如果每个人都喜欢几种颜色,这可能导致不成比例的存储。
分片键的更好的选择是保证更均匀分布的东西。 例如,在一家大公司,生日(月和日)字段可能会相当均匀地分布。
如果您不确定将如何分发事物,或没有适当的字段,则可以基于现有字段创建“hashed”分片键。 这是我们将为我们的数据。
我们可以创建一个名为集合test_collection和散列它的“id”字段。 确保我们使用我们的测试 DB数据库,然后发出以下命令:
use test_db
db.test_collection.ensureIndex( { _id : "hashed" } )
然后,我们可以通过发出以下命令来分片集合:
sh.shardCollection("test_db.test_collection", { "_id": "hashed" } )
这将分割所有可用碎片的集合。
将测试数据插入集合
我们可以通过使用循环来创建一些对象来看到我们的sharding在操作中。 这个循环从MongoDB的网站直接来自生成测试数据。
我们可以使用一个简单的循环将数据插入到集合中,如下所示:
use test_db
for (var i = 1; i <= 500; i++) db.test_collection.insert( { x : i } )
这将创建500个简单文档(只有ID字段和包含数字的“x”字段),并将它们分布在不同的分片中。 您可以通过键入以下内容查看结果:
db.test_collection.find()
{ "_id" : ObjectId("529d082c488a806798cc30d3"), "x" : 6 }
{ "_id" : ObjectId("529d082c488a806798cc30d0"), "x" : 3 }
{ "_id" : ObjectId("529d082c488a806798cc30d2"), "x" : 5 }
{ "_id" : ObjectId("529d082c488a806798cc30ce"), "x" : 1 }
{ "_id" : ObjectId("529d082c488a806798cc30d6"), "x" : 9 }
{ "_id" : ObjectId("529d082c488a806798cc30d1"), "x" : 4 }
{ "_id" : ObjectId("529d082c488a806798cc30d8"), "x" : 11 }
. . .
要获取更多值,请键入:
it
{ "_id" : ObjectId("529d082c488a806798cc30cf"), "x" : 2 }
{ "_id" : ObjectId("529d082c488a806798cc30dd"), "x" : 16 }
{ "_id" : ObjectId("529d082c488a806798cc30d4"), "x" : 7 }
{ "_id" : ObjectId("529d082c488a806798cc30da"), "x" : 13 }
{ "_id" : ObjectId("529d082c488a806798cc30d5"), "x" : 8 }
{ "_id" : ObjectId("529d082c488a806798cc30de"), "x" : 17 }
{ "_id" : ObjectId("529d082c488a806798cc30db"), "x" : 14 }
{ "_id" : ObjectId("529d082c488a806798cc30e1"), "x" : 20 }
. . .
要获取有关特定分片的信息,您可以键入:
sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"version" : 3,
"minCompatibleVersion" : 3,
"currentVersion" : 4,
"clusterId" : ObjectId("529cae0691365bef9308cd75")
}
shards:
{ "_id" : "shard0000", "host" : "162.243.243.156:27017" }
{ "_id" : "shard0001", "host" : "162.243.243.155:27017" }
. . .
这将提供有关MongoDB在碎片之间分布的块的信息。
结论
在本指南的结尾,您应该能够实现您自己的MongoDB分片配置。 服务器的特定配置和为每个集合选择的分片键将对群集的性能产生很大影响。
选择具有最佳分布属性并最接近地表示将反映在数据库查询中的逻辑分组的字段。 如果MongoDB只需要去一个单一的shard检索你的数据,它会返回更快。







