系统监控是每一个系统管理员的主要职责。我想每个系统管理员必须了解一些命令行和一些自动化系统监控工具。在这篇文章中,我提供15个监测工具,我希望它会帮助你。
#1. Top (Linux命令)
Top 是基本的和经常使用的命令。它显示正在运行的进程,监测系统性能的一切都是实时的。在我的学习时间,我仍然使用它。大多数Linux / Unix版本带有此命令。top提供进程PID,CPU和内存使用情况,交换内存,缓存大小,缓冲区大小等。
# top
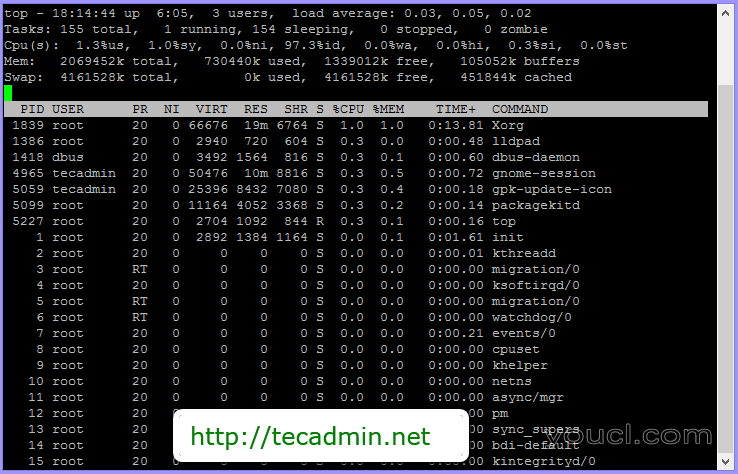
阅读全文-如何阅读top命令输出信息
#2. ps
ps命令提供了当前运行的进程的详细信息。 ps还提供了许多选项,得到的结果更具体的结果
# ps -e
PID TTY TIME CMD
1 ? 00:00:01 init
2 ? 00:00:00 kthreadd
3 ? 00:00:00 migration/0
4 ? 00:00:00 ksoftirqd/0
5 ? 00:00:00 migration/0
6 ? 00:00:00 watchdog/0
7 ? 00:00:00 events/0
8 ? 00:00:00 cpuset
9 ? 00:00:00 khelper
10 ? 00:00:00 netns
11 ? 00:00:00 async/mgr
12 ? 00:00:00 pm
13 ? 00:00:00 sync_supers
...
要列出服务器上的所有进程
# ps aux
要列出特定用户的所有进程
# ps -u <user_name>
#3. netstat(网络统计)
netstat是输出网络连接信息,输出路由表,接口统计,伪装连接和组播成员等非常有用的工具。 例如下面的命令将提供所有监听TCP和UDP端口,有服务名称的列表。
# netstat -tulnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 1371/rpcbind
tcp 0 0 0.0.0.0:39698 0.0.0.0:* LISTEN 1458/rpc.statd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1683/sshd
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 1556/cupsd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1771/master
tcp 0 0 :::80 :::* LISTEN 2247/httpd
tcp 0 0 :::22 :::* LISTEN 1683/sshd
udp 0 0 0.0.0.0:47307 0.0.0.0:* 1440/avahi-daemon
udp 0 0 0.0.0.0:111 0.0.0.0:* 1371/rpcbind
udp 0 0 0.0.0.0:631 0.0.0.0:* 1556/cupsd
udp 0 0 0.0.0.0:41242 0.0.0.0:* 1458/rpc.statd
udp 0 0 0.0.0.0:698 0.0.0.0:* 1371/rpcbind
udp 0 0 :::111 :::* 1371/rpcbind
#4. Nagios
Nagios是开源和强大的监测系统,它能够识别并解决IT基础设施问题,影响关键业务流程。 使用Nagios,我们可以轻松地监视主机系统,本地或远程服务,网络外设等,还可以通过电子邮件通知系统,短信等。 阅读教程:
在CentOS,RHEL系统安装Nagios和NagiosQL
#5. vnStat
vnStat是基于Linux system.It计数带宽(发送和接收)的网络接口上基于控制台的网络流量监控并存储在自己的数据库。 vnStat还提供了一个基于PHP的Web界面来显示以及图形形成网络静。
# vnstat -d
eth0 / daily
day rx | tx | total | avg. rate
------------------------+-------------+-------------+---------------
05/07/13 213.12 MiB | 837.71 MiB | 1.03 GiB | 120.06 kbit/s
------------------------+-------------+-------------+---------------
estimated 256 MiB | 0.98 GiB | 1.23 GiB |
# vnstat -m
# vnstat -h
# vnstat -l
阅读更多:
在CentOS,RHEL Linux上安装vnStat和vnStat PHP
#6. vmstat
vmstat命令显示有关进程,内存,分页,块IO,Traps 和CPU活动的信息。
# vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 1392620 108972 436948 0 0 15 4 17 20 0 0 99 0 0
您还可以指定显示在固定时间间隔的vmstat输出。下面的例子将显示在每次5秒输出。
# vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 1392612 108980 436948 0 0 15 4 17 20 0 0 99 0 0
0 0 0 1392604 108988 436944 0 0 0 12 22 24 0 0 100 0 0
0 0 0 1392604 108988 436948 0 0 0 0 12 15 0 0 100 0 0
0 0 0 1392604 108988 436948 0 0 0 0 18 24 0 0 100 0 0
#7. Munin
Munin是一个网络资源监控工具,可以帮助分析资源的趋势。Munin监测工具调查所有的计算机并记录保存下来。它可以通过Web界面以图表显示所有信息。
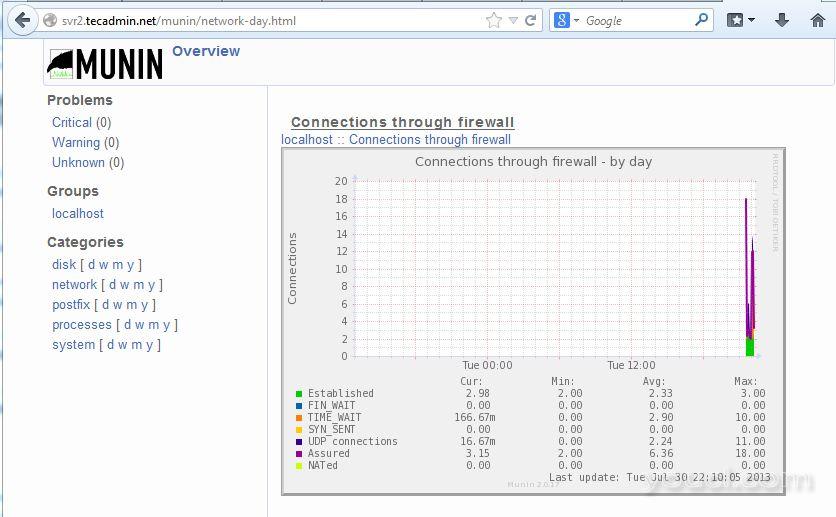 阅读更多:
在CentOS/RHEL和Fedora安装Munin网络监控
阅读更多:
在CentOS/RHEL和Fedora安装Munin网络监控
#8. Iostat
iostat命令通过观察在时间段内设备的平均传输速率,用于监控系统的input/output设备负载。 下面简单的iostat命令检查信息,它显示CPU细节和连接的磁盘统计数据输出。
# iostat
Linux 2.6.32-220.el6.i686 (youcl.com) 10/07/2013 _i686_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.07 0.00 0.29 0.17 0.00 99.47
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
scd0 0.00 0.01 0.00 392 0
sda 0.79 28.94 8.12 1178216 330444
dm-0 1.97 28.71 8.12 1168554 330376
dm-1 0.01 0.06 0.00 2576 0
检查特定磁盘的静态系统。
# iostat -d /dev/sda -m
Linux 2.6.32-220.el6.i686 (youcl.com) 10/07/2013 _i686_ (1 CPU)
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 0.78 0.01 0.00 575 161
-m :用于显示结果为每秒兆字节。
#9. Cacti
Cacti是利用RRDTool的数据存储和绘图功能的强大的开源,基于Web的网络监控图形界面工具。 Cacti还提供了“数据输入”机制,它允许用户定义可用于收集数据的自定义脚本。 阅读更多:
在CentOS和RHEL系统安装Cacti(网络图形工具)
#10. Htop
Htop 是 top 的替代工具,但它提供一个互动的系统监测进程查看器,相比top有更加用户友好的输出。
Htop还提供了一个使用键盘 Up/Down 键以更好的方式来浏览,以及我们也可以用鼠标来操作它的任何进程。要使用只需在终端上键入命令
htop
# htop
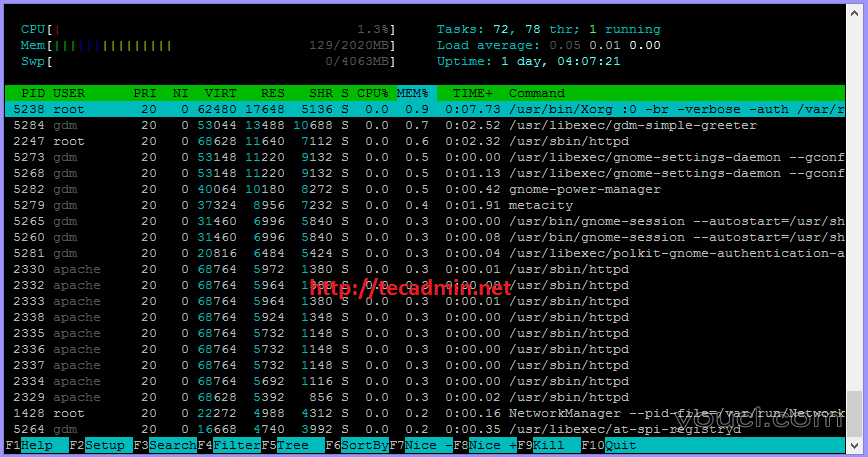
#11. iotop
iotop是很有用的命令找出哪些进程正在在硬盘上占用大量负荷。 iotop是一个Python程序,界面像top 一样显示代表其过程是I/O信息。它需要Python ≥ 2.7和Linux内核≥2.6.20。
# iotop
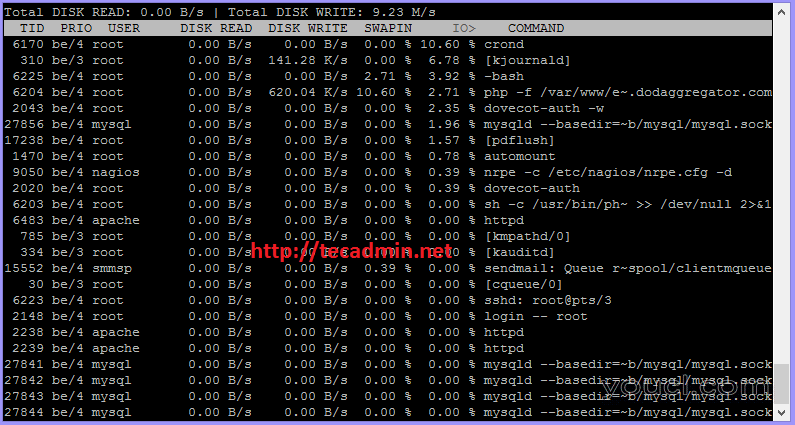
#12. uptime
uptime 命令可以用来查看服务器已经运行了多久。
# uptime
21:15:44 up 1 day, 6:56, 4 users, load average: 0.17, 0.43, 0.48
此外,它显示了当前有多少用户登录,以及服务器在过去的1分钟、5分钟、15分钟的系统平均负载值。
#13. strace
strace对于系统管理员解决与主要的二进制文件(其源不可用)程序问题的一个有用的命令。 例如,我们使用'ls'的命令列出的文件和目录,但我们不能编辑这个命令的源代码。在此情况下,命令不能正常工作,我们别无选择,修改其代码,但我们可以追踪的,但我们可以通过这个命令生成的系统调用和信号。
# strace ls
execve("/bin/ls", ["ls"], [/* 26 vars */]) = 0
brk(0) = 0x9558000
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7871000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=57422, ...}) = 0
mmap2(NULL, 57422, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7862000
close(3) = 0
...
...
要查看只读系统调用使用-e选项
# strace -e read ls
read(3, "177ELF111 3 3 1 220303A 004 "..., 512) = 512
read(3, "177ELF111 3 3 1 2003300 004 "..., 512) = 512
read(3, "177ELF111 3 3 1 340lp 004 "..., 512) = 512
read(3, "177ELF111 3 3 1 p366320 064 "..., 512) = 512
read(3, "177ELF1113 3 3 1 @23623 004 "..., 512) = 512
read(3, "177ELF111 3 3 1 `312+ 004 "..., 512) = 512
read(3, "177ELF111 3 3 1 260|, 004 "..., 512) = 512
read(3, "177ELF111 3 3 1 Pn337 004 "..., 512) = 512
read(3, "nodevtsysfsnnodevtrootfsnnodevtb"..., 1024) = 368
read(3, "", 1024)
#14. sar
sar 命令非常有用的收集、报告和保存系统活动信息的命令。 默认sar命令显示类似下面CPU的活动。
# sar
Linux 2.6.32-220.el6.i686 (youcl.com) 10/08/2013 _i686_ (1 CPU)
12:00:01 AM CPU %user %nice %system %iowait %steal %idle
12:10:01 AM all 0.01 0.00 0.09 0.01 0.00 99.89
12:20:01 AM all 0.02 0.00 0.08 0.02 0.00 99.88
Average: all 0.01 0.00 0.09 0.01 0.00 99.89
若要查看下面的命令以太网卡使用的活动。
# sar -n DEV
Linux 2.6.32-220.el6.i686 (youcl.com) 10/08/2013 _i686_ (1 CPU)
12:00:01 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
12:10:01 AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
12:10:01 AM eth0 1.76 0.00 0.18 0.00 0.00 0.00 0.00
12:20:01 AM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
12:20:01 AM eth0 1.83 0.02 0.19 0.00 0.00 0.00 0.00
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: eth0 1.79 0.01 0.19 0.00 0.00 0.00 0.00
#15. Zabbix
Zabbix是为您的网络性能监测的开源软件。它提供了所有平台代理。 Zabbix有数据的收集能力极强,创建图形和网络地图。
 Zabbix提供用于监视其它很多重要功能。
了解更多关于Zabbix功能。 阅读更多
在CentOS / RHEL和Fedora中安装Zabbix网络监控
Zabbix提供用于监视其它很多重要功能。
了解更多关于Zabbix功能。 阅读更多
在CentOS / RHEL和Fedora中安装Zabbix网络监控







