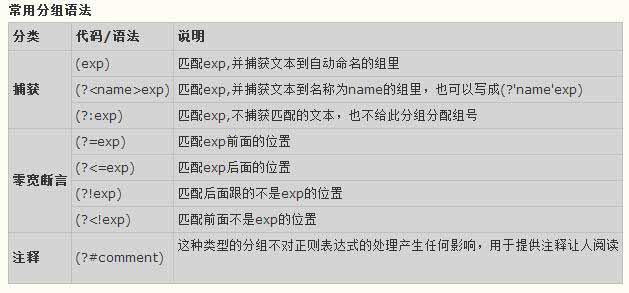
什么是零宽断言?
零宽断言的意思是(匹配宽度为零,满足一定的条件/断言) 我也不知道这个词语是那个王八蛋发明的,简直是太拗口了。
零宽断言用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像 \b ^ $ \< \> 这样的锚定作用,仅仅用于指定一个位置,不参与内容匹配,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。 断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配。
其中零宽断言又分四种:

(?=表达式) 零宽度正预测先行断言 表示匹配表达式前面的位置
例如,要匹配 cooking ,singing ,doing中除了ing之外的内容,只取cook, sing, do的内容,这时候的增则表达式可以用 [a-z]*(?=ing) 来匹配
注意:先行断言的执行步骤是这样的先从要匹配的字符串中的最右端找到第一个 ing (也就是先行断言中的表达式)然后 再匹配其前面的表达式,若无法匹配则继续查找第二个 ing 再匹配第二个 ing 前面的字符串,若能匹配则匹配,符合正则的贪婪性。
例如: .*(?=ing) 可以匹配 “cooking singing” 中的 “cooking sing” 而不是 cook
(?<=表达式) 零宽度正回顾后发断言 表示匹配表达式后面的位置
例如 (?<=abc).* 可以匹配 abcdefg 中的 defg
注意:后发断言跟先行断言恰恰相反 它的执行步骤是这样的:先从要匹配的字符串中的最左端找到第一个abc(也就是先行断言中的表达式)然后 再匹配其后面的表达式,若无法匹配则继续查找第二个 abc 再匹配第二个 abc 后面的字符串,若能匹配则匹配。
例如 (?<=abc).* 可以匹配 abcdefgabc 中的 defgabc 而不是 abcdefg
(?!表达式) 负向零宽先行断言
负向零宽断言 (?!exp) 也是匹配一个零宽度的位置,不过这个位置的“断言”取表达式的反值,例如 (?!exp) 表示 “exp” 前面的位置,如果 “exp” 不成立 ,匹配这个位置;如果 “exp” 成立,则不匹配。
同样,负向零宽断言也有“先行”和“后发”两种
负向零宽先行断言为
(?!exp)负向零宽后发断言为
(?<!exp)
(?﹤!表达式) 负向零宽后发断言
负向零宽断言要注意的跟正向的一样。
实战1:匹配不包含属性的HTML标签里的内容
一个更复杂的例子:(?<=<(\w+)>).*(?=<\/\1>)匹配不包含属性的简单HTML标签内里的内容。(<?(\w+)>)指定了这样的前缀:被尖括号括起来的单词(比如可能是<b>),然后是.*(任意的字符串),最后是一个后缀(?=<\/\1>)。注意后缀里的\/,它用到了前面提过的字符转义;\1则是一个反向引用,引用的正是捕获的第一组,前面的(\w+)匹配的内容,这样如果前缀实际上是<b>的话,后缀就是</b>了。整个表达式匹配的是<b>和</b>之间的内容(再次提醒,不包括前缀和后缀本身)。
实战2:获取小括号里面的内容
博客地址:https://www.youcl.com/info/2636
百度百科教程:http://baike.so.com/doc/204329-216060.html
配备一个视频讲解,非常容易理解
http://www.tudou.com/listplay/-_We06cygOw/ajlbc1Thm4A.html
文字摘录:http://jjdoor.blog.163.com/blog/static/184780342012318917389/







