最近阅读了《Redis开发与运维》,非常不错。这里对书中的知识整理一下,方便自己回顾一下Redis的整个体系,来对相关知识点查漏补缺。
我按照五点把书中的内容进行一下整理:
为什么要选择Redis:介绍Redis的使用场景与使用Redis的原因;
Redis常用命令总结:包括时间复杂度总结与具体数据类型在Redis内部使用的数据结构;
Redis的高级功能:包括持久化、复制、哨兵、集群介绍;
理解Redis:理解内存、阻塞;这部分是非常重要的,前面介绍的都可以成为术,这里应该属于道的部分。;
开发技巧:主要是一些开发实战的总结,包括缓存设计与常见坑点。
先来开启第一部分的内容,对Redis来一次重新打量。
本系列内容基于:redis-3.2.12
Redis不是万金油
在面试的时候,常被问比较下Redis与Memcache的优缺点,个人觉得这二者并不适合一起比较,一个是非关系型数据库不仅可以做缓存还能干其它事情,一个是仅用做缓存。常常让我们对这二者进行比较,主要也是由于Redis最广泛的应用场景就是Cache。那么Redis到底能干什么?又不能干什么呢?
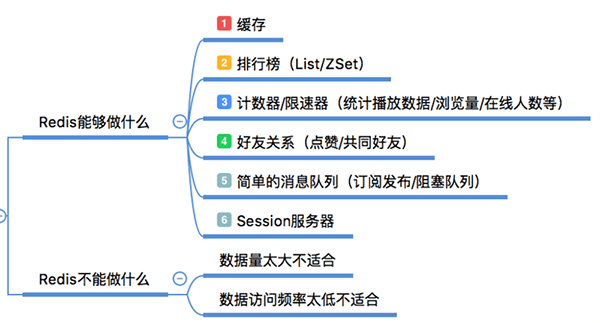
Redis都可以干什么事儿
缓存,毫无疑问这是Redis当今最为人熟知的使用场景。再提升服务器性能方面非常有效;
排行榜,如果使用传统的关系型数据库来做这个事儿,非常的麻烦,而利用Redis的SortSet数据结构能够非常方便搞定;
计算器/限速器,利用Redis中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力;限速器比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力;
好友关系,利用集合的一些命令,比如求交集、并集、差集等。可以方便搞定一些共同好友、共同爱好之类的功能;
简单消息队列,除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制,比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List来完成异步解耦;
Session共享,以PHP为例,默认Session是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆;采用Redis保存Session后,无论用户落在那台机器上都能够获取到对应的Session信息。
Redis不能干什么事儿
Redis感觉能干的事情特别多,但它不是万能的,合适的地方用它事半功倍。如果滥用可能导致系统的不稳定、成本增高等问题。
比如,用Redis去保存用户的基本信息,虽然它能够支持持久化,但是它的持久化方案并不能保证数据绝对的落地,并且还可能带来Redis性能下降,因为持久化太过频繁会增大Redis服务的压力。
简单总结就是数据量太大、数据访问频率非常低的业务都不适合使用Redis,数据太大会增加成本,访问频率太低,保存在内存中纯属浪费资源。
选择总需要找个理由
上面说了Redis的一些使用场景,那么这些场景的解决方案也有很多其它选择,比如缓存可以用Memcache,Session共享还能用MySql来实现,消息队列可以用RabbitMQ,我们为什么一定要用Redis呢?
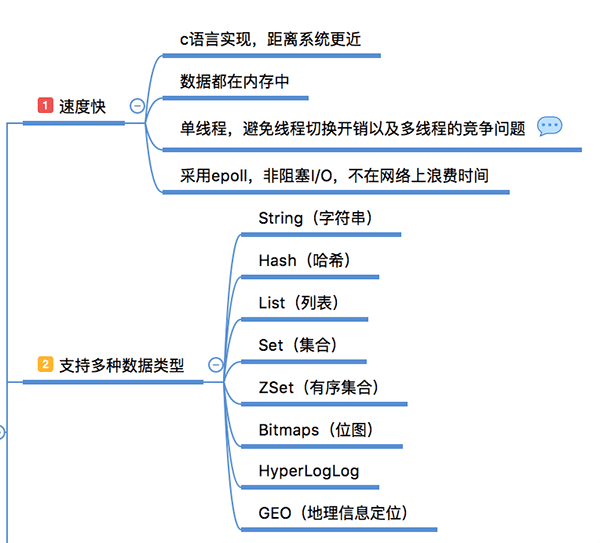
速度快,完全基于内存,使用C语言实现,网络层使用epoll解决高并发问题,单线程模型避免了不必要的上下文切换及竞争条件;
注意:单线程仅仅是说在网络请求这一模块上用一个请求处理客户端的请求,像持久化它就会重开一个线程/进程去进行处理
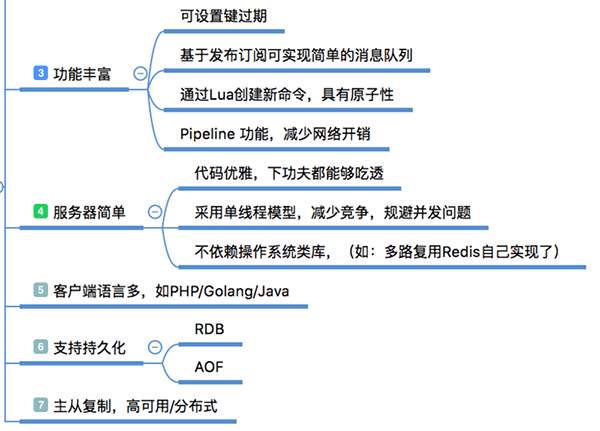
丰富的数据类型,Redis有8种数据类型,当然常用的主要是 String、Hash、List、Set、 SortSet 这5种类型,他们都是基于键值的方式组织数据。每一种数据类型提供了非常丰富的操作命令,可以满足绝大部分需求,如果有特殊需求还能自己通过 lua 脚本自己创建新的命令(具备原子性);
除了提供的丰富的数据类型,Redis还提供了像慢查询分析、性能测试、Pipeline、事务、Lua自定义命令、Bitmaps、HyperLogLog、发布/订阅、Geo等个性化功能。
Redis的代码开源在GitHub,代码非常简单优雅,任何人都能够吃透它的源码;它的编译安装也是非常的简单,没有任何的系统依赖;有非常活跃的社区,各种客户端的语言支持也是非常完善。另外它还支持事务(没用过)、持久化、主从复制让高可用、分布式成为可能。
做为一个开发者,对于我们使用的东西不能让它成为一个黑盒子,我们应该深入进去,对它更了解、更熟悉。今天简单说了下Redis的使用场景,以及为什么选择了Redis而不是其它。下次对Redis的内部数据结构及常用命令的时间复杂度进行总结。
来自:大愚Talk







