介绍
在Kubernetes集群上运行多个服务和应用程序时,集中式集群级日志记录可以帮助您快速排序和分析Pod生成的大量日志数据。 一种流行的集中式日志记录解决方案是E lasticsearch, F luentd和K ibana(EFK)。
Elasticsearch是一个实时,分布式和可扩展的搜索引擎,允许进行全文和结构化搜索以及分析。 它通常用于索引和搜索大量日志数据,但也可用于搜索许多不同类型的文档。
Elasticsearch通常与Kibana一起部署, Kibana是Elasticsearch的强大数据可视化前端和仪表板。 Kibana允许您通过Web界面浏览Elasticsearch日志数据,并构建仪表板和查询以快速回答问题并深入了解您的Kubernetes应用程序。
在本教程中,我们将使用Fluentd来收集,转换日志数据并将其发送到Elasticsearch后端。 Fluentd是一个流行的开源数据收集器,我们将在我们的Kubernetes节点上设置尾部容器日志文件,过滤和转换日志数据,并将其传递到Elasticsearch集群,在集群中将对其进行索引和存储。
我们将首先配置和启动可扩展的Elasticsearch集群,然后创建Kibana Kubernetes服务和部署。 最后,我们将Fluentd设置为DaemonSet,以便它在每个Kubernetes工作节点上运行。
先决条件
在开始本指南之前,请确保您可以使用以下内容:
启用了基于角色的访问控制(RBAC)的Kubernetes 1.10+集群
- 确保您的群集有足够的资源可用于部署EFK,如果不是通过添加工作节点来扩展群集。 我们将部署3-Pod Elasticsearch集群(如果需要,您可以将其缩小到1),以及单个Kibana Pod。 每个工作节点也将运行Fluentd Pod。 本指南中的群集由3个工作节点和一个托管控制平面组成。
kubectl命令行工具安装在本地计算机上,配置为连接到您的群集。 您可以在官方文档中阅读有关安装kubectl更多信息。
设置好这些组件后,您就可以开始使用本指南了。
第1步 - 创建命名空间
在我们推出Elasticsearch集群之前,我们首先要创建一个名称空间,我们将在其中安装所有日志记录工具。 Kubernetes允许您使用名为Namespaces的“虚拟集群”抽象来分隔在集群中运行的对象。 在本指南中,我们将创建一个kube-logging命名空间,我们将在其中安装EFK组件。 此命名空间还允许我们快速清理和删除日志,而不会对Kubernetes集群造成任何功能损失。
首先,首先使用kubectl调查集群中的现有命名空间:
kubectl get namespaces
您应该看到以下三个初始命名空间,它们预先安装了Kubernetes集群:
OutputNAME STATUS AGE
default Active 5m
kube-system Active 5m
kube-public Active 5m
default名称空间包含在未指定命名空间的default创建的对象。 kube-system命名空间包含由Kubernetes系统创建和使用的对象,如kube-dns , kube-proxy和kubernetes-dashboard 。 最好保持此命名空间清洁,不要将其与应用程序和检测工作负载一起污染。
kube-public Namespace是另一个自动创建的Namespace,可用于存储您希望在整个集群中可读和可访问的对象,甚至是未经身份验证的用户。
要创建kube-logging命名空间,首先使用您喜欢的编辑器打开并编辑名为kube-logging.yaml的文件,例如nano:
nano kube-logging.yaml
在编辑器中,粘贴以下命名空间对象YAML:
kind: Namespace
apiVersion: v1
metadata:
name: kube-logging
然后,保存并关闭该文件。
在这里,我们将Kubernetes对象的kind指定为Namespace对象。 要了解有关Namespace对象的更多信息,请参阅官方Kubernetes文档中的命名空间演练 。 我们还指定了用于创建对象的Kubernetes API版本( v1 ),并为其name , kube-logging 。
创建kube-logging.yaml命名空间对象文件后,使用带有-f filename标志的kubectl create创建命名空间:
kubectl create -f kube-logging.yaml
您应该看到以下输出:
Outputnamespace/kube-logging created
然后,您可以确认已成功创建命名空间:
kubectl get namespaces
此时,您应该看到新的kube-logging命名空间:
OutputNAME STATUS AGE
default Active 23m
kube-logging Active 1m
kube-public Active 23m
kube-system Active 23m
我们现在可以将Elasticsearch集群部署到此隔离的日志记录命名空间中。
第2步 - 创建Elasticsearch StatefulSet
现在我们已经创建了一个命名空间来存放我们的日志,我们可以开始推出它的各种组件。 我们首先开始部署一个3节点的Elasticsearch集群。
在本指南中,我们使用3个Elasticsearch Pod来避免高可用性多节点集群中出现的“裂脑”问题。 在高层次上,当一个或多个节点无法与其他节点通信时会产生“裂脑”,并且几个“分裂”主人会被选中。 要了解更多信息,请参阅“ 避免裂脑” 。
一个关键点是你应该将discover.zen.minimum_master_nodes Elasticsearch参数设置为N/2 + 1 (在小数字的情况下向下舍入),其中N是Elasticsearch集群中符合主节点的节点数。 对于我们的3节点集群,这意味着我们将此值设置为2 。 这样,如果一个节点暂时与群集断开连接,则另外两个节点可以选择新的主节点,并且群集可以在最后一个节点尝试重新加入时继续运行。 在扩展Elasticsearch集群时,请务必牢记此参数。
创造无头服务
首先,我们将创建一个名为elasticsearch的无头Kubernetes服务,该服务将为3个Pod定义DNS域。 无头服务不执行负载平衡或具有静态IP; 要了解有关无头服务的更多信息,请参阅官方Kubernetes文档 。
使用您喜欢的编辑器打开一个名为elasticsearch_svc.yaml的文件:
nano elasticsearch_svc.yaml
粘贴以下Kubernetes服务YAML:
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: kube-logging
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node
然后,保存并关闭该文件。
我们在kube-logging命名空间中定义一个名为kube-logging的Service ,并为其提供app: elasticsearch标签。 然后,我们将.spec.selector设置为app: elasticsearch .spec.selector ,以便服务选择具有app: elasticsearch标签的.spec.selector 。 当我们将Elasticsearch StatefulSet与此服务关联时,服务将返回带有app: elasticsearch标签的指向Elasticsearch Pods的DNS A记录。
然后我们设置clusterIP: None ,这使得服务无头。 最后,我们定义了端口9200和9300 ,它们分别用于与REST API交互和节点间通信。
使用kubectl创建服务:
kubectl create -f elasticsearch_svc.yaml
您应该看到以下输出:
Outputservice/elasticsearch created
最后,使用kubectl get仔细检查服务是否已成功创建:
kubectl get services --namespace=kube-logging
你应该看到以下内容:
OutputNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 26s
现在我们已经为我们的.elasticsearch.kube-logging.svc.cluster.local设置了无头服务和稳定的.elasticsearch.kube-logging.svc.cluster.local域,我们可以继续创建StatefulSet。
创建StatefulSet
Kubernetes StatefulSet允许您为Pod分配稳定的标识,并为它们授予稳定的持久存储。 Elasticsearch需要稳定的存储来保持Pod重新安排和重启的数据。 要了解有关StatefulSet工作负载的更多信息,请参阅Kubernetes文档中的Statefulsets页面。
在您喜欢的编辑器中打开一个名为elasticsearch_statefulset.yaml的文件:
nano elasticsearch_statefulset.yaml
我们将逐节遍历StatefulSet对象定义,将块粘贴到此文件中。
首先粘贴在以下块中:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
在这个块中,我们在kube-logging命名空间中定义了一个名为es-cluster的StatefulSet。 然后,我们使用serviceName字段将其与我们之前创建的elasticsearch服务相关联。 这可确保使用以下DNS地址访问StatefulSet中的每个Pod: es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local ,其中[0,1,2]对应到Pod的指定整数序数。
我们指定3个replicas (Pods)并将matchLabels选择器设置为app: elasticseach matchLabels ,然后我们在.spec.template.metadata部分中镜像。 .spec.selector.matchLabels和.spec.template.metadata.labels字段必须匹配。
我们现在可以转到对象规范。 粘贴在前一个块正下方的YAML的以下块中:
. . .
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch-oss:6.4.3
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.zen.ping.unicast.hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: discovery.zen.minimum_master_nodes
value: "2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
这里我们在StatefulSet中定义Pod。 我们将容器命名为docker.elastic.co/elasticsearch/elasticsearch-oss:6.4.3并选择docker.elastic.co/elasticsearch/elasticsearch-oss:6.4.3 Docker镜像。 此时,您可以修改此图像标记以对应于您自己的内部Elasticsearch图像或不同的版本。 请注意,出于本指南的目的,仅测试了Elasticsearch 6.4.3 。
-ossPostfix确保我们使用Elasticsearch的开源版本。 如果您想使用包含X-Pack的默认版本(包括免费许可证),请省略-ossPostfix。 请注意,您必须稍微修改本指南中的步骤,以考虑X-Pack提供的添加的身份验证。
然后,我们使用resources字段指定容器需要至少0.1 vCPU保证,并且可以突发最多1个vCPU(这限制了Pod在执行初始大量摄取或处理负载峰值时的资源使用情况)。 您应该根据预期的负载和可用资源修改这些值。 要了解有关资源请求和限制的更多信息,请参阅官方Kubernetes文档 。
然后,我们分别打开并命名端口9200和9300用于REST API和节点间通信。 我们指定一个名为data的volumeMount ,它将PersistentVolume命名data挂载到路径/usr/share/elasticsearch/data的容器中。 我们将在稍后的YAML块中为此StatefulSet定义VolumeClaims。
最后,我们在容器中设置了一些环境变量:
-
cluster.name集群的名称,在本指南中为k8s-logs。 -
node.name:节点的名称,我们使用valueFrom设置为.metadata.name字段。 这将解析为es-cluster-[0,1,2],具体取决于节点的指定序数。 -
discovery.zen.ping.unicast.hosts:此字段设置用于在Elasticsearch集群中相互连接节点的发现方法。 我们使用unicast发现,它为我们的集群指定了一个静态主机列表。 在本指南中,由于我们之前配置的无头服务,我们的Pod具有es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local形式的域,因此我们相应地设置此变量。 使用本地命名空间Kubernetes DNS解析,我们可以将其缩短为es-cluster-[0,1,2].elasticsearch。 要了解有关Elasticsearch发现的更多信息,请参阅Elasticsearch官方文档 。 -
discovery.zen.minimum_master_nodes:我们将其设置为(N/2) + 1,其中N是我们集群中符合主节点的节点数。 在本指南中,我们有3个Elasticsearch节点,因此我们将此值设置为2(向下舍入到最接近的整数)。 要了解有关此参数的更多信息,请参阅官方Elasticsearch文档 。 -
ES_JAVA_OPTS:这里我们将其设置为-Xms512m -Xmx512m,它告诉JVM使用512 MB的最小和最大堆大小。 您应该根据群集的资源可用性和需求调整这些参数。 要了解更多信息,请参阅设置堆大小 。
我们将粘贴的下一个块看起来如下:
. . .
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
在此块中,我们定义了几个在主elasticsearch应用程序容器之前运行的Init容器。 这些初始容器按照定义的顺序运行完成。 要了解有关Init Containers的更多信息,请参阅官方Kubernetes文档 。
第一个命名的fix-permissions运行chown命令,将Elasticsearch数据目录的所有者和组更改为1000:1000 ,即Elasticsearch用户的UID。 默认情况下,Kubernetes以root身份安装数据目录,这使得Elasticsearch无法访问它。 要了解有关此步骤的更多信息,请参阅Elasticsearch的“ 生产使用和默认注意事项 ”。
第二个名为increase-vm-max-map ,运行一个命令来增加操作系统对mmap计数的限制,默认情况下可能太低,导致内存不足错误。 要了解有关此步骤的更多信息,请参阅Elasticsearch官方文档 。
要运行的下一个Init容器是increase-fd-ulimit ,它运行ulimit命令以增加打开文件描述符的最大数量。 要了解有关此步骤的更多信息,请参阅Elasticsearch官方文档中的“ 生产使用和默认注意事项 ”。
注意: Elasticsearch Notes for Production Use还提到由于性能原因而禁用交换。 根据您的Kubernetes安装或提供程序,可能已禁用交换。 要检查这一点,请exec到正在运行的容器并运行cat /proc/swaps以列出活动交换设备。 如果你什么也看不到,那就禁用交换。
现在我们已经定义了我们的主app容器和在它之前运行的Init Containers来调整容器操作系统,我们可以将最后一块添加到我们的StatefulSet对象定义文件中: volumeClaimTemplates 。
粘贴在以下volumeClaimTemplate块中:
. . .
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 100Gi
在这个块中,我们定义了StatefulSet的volumeClaimTemplates 。 Kubernetes将使用它为Pod创建PersistentVolumes。 在上面的块中,我们将其命名为data (这是我们之前在之前定义的volumeMount引用的name ),并为其提供相同的app: elasticsearch标签作为我们的StatefulSet。
然后,我们将其访问模式指定为ReadWriteOnce ,这意味着它只能由单个节点以读写方式挂载。 我们在本指南中将存储类定义为do-block-storage ,因为我们使用DigitalOcean Kubernetes集群进行演示。 您应该根据运行Kubernetes集群的位置更改此值。 要了解更多信息,请参阅Persistent Volume文档。
最后,我们指定我们希望每个PersistentVolume的大小为100GiB。 您应根据生产需要调整此值。
完整的StatefulSet规范应如下所示:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch-oss:6.4.3
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.zen.ping.unicast.hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: discovery.zen.minimum_master_nodes
value: "2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 100Gi
一旦您对Elasticsearch配置感到满意,请保存并关闭该文件。
现在,使用kubectl部署StatefulSet:
kubectl create -f elasticsearch_statefulset.yaml
您应该看到以下输出:
Outputstatefulset.apps/es-cluster created
您可以使用kubectl rollout status监视StatefulSet:
kubectl rollout status sts/es-cluster --namespace=kube-logging
在推出集群时,您应该看到以下输出:
OutputWaiting for 3 pods to be ready...
Waiting for 2 pods to be ready...
Waiting for 1 pods to be ready...
partitioned roll out complete: 3 new pods have been updated...
部署完所有Pod后,您可以通过执行针对REST API的请求来检查您的Elasticsearch集群是否正常运行。
为此,首先使用kubectl port-forward将本地端口9200转发到其中一个Elasticsearch节点( es-cluster-0 )上的端口9200 :
kubectl port-forward es-cluster-0 9200:9200 --namespace=kube-logging
然后,在单独的终端窗口中,对REST API执行curl请求:
curl http://localhost:9200/_cluster/state?pretty
您应该看到以下输出:
Output{
"cluster_name" : "k8s-logs",
"compressed_size_in_bytes" : 348,
"cluster_uuid" : "QD06dK7CQgids-GQZooNVw",
"version" : 3,
"state_uuid" : "mjNIWXAzQVuxNNOQ7xR-qg",
"master_node" : "IdM5B7cUQWqFgIHXBp0JDg",
"blocks" : { },
"nodes" : {
"u7DoTpMmSCixOoictzHItA" : {
"name" : "es-cluster-1",
"ephemeral_id" : "ZlBflnXKRMC4RvEACHIVdg",
"transport_address" : "10.244.8.2:9300",
"attributes" : { }
},
"IdM5B7cUQWqFgIHXBp0JDg" : {
"name" : "es-cluster-0",
"ephemeral_id" : "JTk1FDdFQuWbSFAtBxdxAQ",
"transport_address" : "10.244.44.3:9300",
"attributes" : { }
},
"R8E7xcSUSbGbgrhAdyAKmQ" : {
"name" : "es-cluster-2",
"ephemeral_id" : "9wv6ke71Qqy9vk2LgJTqaA",
"transport_address" : "10.244.40.4:9300",
"attributes" : { }
}
},
...
这表明我们的Elasticsearch集群k8s-logs已成功创建了3个节点: es-cluster-0 , es-cluster-1和es-cluster-2 。 当前主节点是es-cluster-0 。
现在您的Elasticsearch集群已启动并运行,您可以继续为其设置Kibana前端。
第3步 - 创建Kibana部署和服务
要在Kubernetes上启动Kibana,我们将创建一个名为kibana的服务,以及一个包含一个Pod副本的部署。 您可以根据生产需要扩展副本数量,并可选择为服务指定LoadBalancer类型,以跨部署窗格负载平衡请求。
这次,我们将在同一个文件中创建服务和部署。 在您喜欢的编辑器中打开一个名为kibana.yaml的文件:
nano kibana.yaml
粘贴以下服务规范:
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
ports:
- port: 5601
selector:
app: kibana
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana-oss:6.4.3
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601
然后,保存并关闭该文件。
在这个规范中,我们在kube-logging命名空间中定义了一个名为kibana的服务,并为其提供了app: kibana标签。
我们还指定它应该可以在端口5601上访问,并使用app: kibana标签来选择服务的目标app: kibana 。
在Deployment规范中,我们定义了一个名为kibana的部署,并指定我们想要1个Pod副本。
我们使用docker.elastic.co/kibana/kibana-oss:6.4.3图像。 此时,您可以替换您自己的私人或公共Kibana图像。 我们再次使用-ossPostfix来指定我们喜欢开源版本。
我们指定我们希望保证最低0.1 vCPU到Pod,突发限制为1 vCPU。 您可以根据预期的负载和可用资源更改这些参数。
接下来,我们使用ELASTICSEARCH_URL环境变量来设置Elasticsearch集群的端点和端口。 使用Kubernetes DNS,此端点对应于其服务名称elasticsearch 。 此域将解析为3个Elasticsearch Pod的IP地址列表。 要了解有关Kubernetes DNS的更多信息,请参阅服务和 Pod的DNS。
最后,我们将Kibana的容器端口设置为5601 , kibana服务将转发请求。
一旦您对Kibana配置感到满意,就可以使用kubectl推出服务和部署:
kubectl create -f kibana.yaml
您应该看到以下输出:
Outputservice/kibana created
deployment.apps/kibana created
您可以通过运行以下命令来检查卷展栏是否成功:
kubectl rollout status deployment/kibana --namespace=kube-logging
您应该看到以下输出:
Outputdeployment "kibana" successfully rolled out
要访问Kibana界面,我们将再次将本地端口转发到运行Kibana的Kubernetes节点。 使用kubectl get Kibana Pod详细信息:
kubectl get pods --namespace=kube-logging
OutputNAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 55m
es-cluster-1 1/1 Running 0 54m
es-cluster-2 1/1 Running 0 54m
kibana-6c9fb4b5b7-plbg2 1/1 Running 0 4m27s
在这里,我们观察到我们的Kibana Pod被称为kibana-6c9fb4b5b7-plbg2 。
将本地端口5601转发到此Pod上的端口5601 :
kubectl port-forward kibana-6c9fb4b5b7-plbg2 5601:5601 --namespace=kube-logging
您应该看到以下输出:
OutputForwarding from 127.0.0.1:5601 -> 5601
Forwarding from [::1]:5601 -> 5601
现在,在您的Web浏览器中,访问以下URL:
http://localhost:5601
如果您看到以下Kibana欢迎页面,那么您已成功将Kibana部署到Kubernetes集群中:
您现在可以继续推出EFK的最终组件:日志收集器,Fluentd。
第4步 - 创建Fluentd DaemonSet
在本指南中,我们将Fluentd设置为DaemonSet,这是一种Kubernetes工作负载类型,它在Kubernetes集群中的每个节点上运行给定Pod的副本。 使用这个DaemonSet控制器,我们将在集群中的每个节点上推出一个Fluentd日志代理Pod。 要了解有关此日志记录体系结构的更多信息,请参阅官方Kubernetes文档中的“ 使用节点日志记录代理 ”。
在Kubernetes中,登录到stdout和stderr容器化应用程序捕获了它们的日志流并重定向到节点上的JSON文件。 Fluentd Pod将拖尾这些日志文件,过滤日志事件,转换日志数据,并将其发送到我们在第2步中部署的Elasticsearch日志后端。
除容器日志外,Fluentd代理还将推出Kubernetes系统组件日志,如kubelet,kube-proxy和Docker日志。 要查看Fluentd日志记录代理程序的完整源代码列表,请参阅用于配置日志记录代理程序的kubernetes.conf文件。 要了解有关登录Kubernetes集群的更多信息,请参阅官方Kubernetes文档中的“ 在节点级别进行日志记录 ”。
首先在您喜欢的文本编辑器中打开一个名为fluentd.yaml的文件:
nano fluentd.yaml
再一次,我们将逐块粘贴Kubernetes对象定义,随着我们的进展提供上下文。 在本指南中,我们使用Fluentd维护者提供的Fluentd DaemonSet规范 。 Fluentd维护者提供的另一个有用资源是Kubernetes Logging with Fluentd 。
首先,粘贴以下ServiceAccount定义:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
在这里,我们创建一个名为fluentd的服务帐户,Fluentd Pod将使用该帐户访问Kubernetes API。 我们在kube-logging命名空间中创建它,并再次给它标签app: fluentd 。 要了解有关Kubernetes中服务帐户的更多信息,请参阅官方Kubernetes文档中的配置Pods服务帐户 。
接下来,粘贴以下ClusterRole块:
. . .
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
在这里,我们定义一个名为fluentd ,我们授予fluentd和lists fluentd的get , list和watch权限。 ClusterRoles允许您授予对节点范围内的Kubernetes资源的访问权限。 要了解有关基于角色的访问控制和群集角色的更多信息,请参阅官方Kubernetes文档中的使用RBAC授权 。
现在,粘贴以下ClusterRoleBinding块:
. . .
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
在这个块中,我们定义了一个名为fluentd , fluentd流利的fluentd绑定到fluentd服务帐户。 这fluentd ServiceAccount授予fluentd Cluster Role中列出的权限。
此时我们可以开始粘贴实际的DaemonSet规范:
. . .
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
在这里,我们在kube-logging命名空间中定义一个名为fluentd ,并kube-logging提供app: fluentd标签。
接下来,粘贴以下部分:
. . .
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v0.12-debian-elasticsearch
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENT_UID
value: "0"
在这里,我们匹配.metadata.labels定义的app: fluentd标签,然后为DaemonSet分配流利的服务帐户。 我们还选择了app: fluentd这个DaemonSet管理的Pod是流利的。
接下来,我们定义NoSchedule容忍度以匹配Kubernetes主节点上的等效污点。 这将确保DaemonSet也被推广到Kubernetes主人。 如果您不想在主节点上运行Fluentd Pod,请删除此容差。 要了解有关Kubernetes污点和耐受性的更多信息,请参阅官方Kubernetes文档中的“Taints and Tolerations ”。
接下来,我们开始定义Pod容器,我们称之为fluentd 。
我们使用Fluentd维护者提供的官方v0.12 Debian映像 。 如果您想使用自己的私人或公共Fluent图像,或使用其他图像版本,请修改容器规格中的image标记。 这个图像的Dockerfile和内容可以在Fluentd的fluentd-kubernetes-daemonset Github repo中找到 。
接下来,我们使用一些环境变量配置Fluentd:
-
FLUENT_ELASTICSEARCH_HOST:我们将其设置为之前定义的Elasticsearch无头服务地址:elasticsearch.kube-logging.svc.cluster.local。 这将解析为3个Elasticsearch Pod的IP地址列表。 实际的Elasticsearch主机很可能是此列表中返回的第一个IP地址。 要在群集中分发日志,您需要修改Fluentd的Elasticsearch Output插件的配置。 要了解有关此插件的更多信息,请参阅Elasticsearch输出插件 。 -
FLUENT_ELASTICSEARCH_PORT:我们将其设置为我们之前配置的Elasticsearch端口9200。 -
FLUENT_ELASTICSEARCH_SCHEME:我们将其设置为http。 -
FLUENT_UID:我们将其设置为0(超级用户),以便Fluentd可以访问/var/log的文件。
最后,粘贴在以下部分:
. . .
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
这里我们在FluentD Pod上指定512 MiB内存限制,并保证其内存为0.1vCPU和200MiB。 您可以根据预期的日志量和可用资源调整这些资源限制和请求。
接下来,我们使用varlog和varlibdockercontainers volumeMounts将/var/log和/var/lib/docker/containers主机路径装入容器。 这些volumes在块的末尾定义。
我们在这个块中定义的最后一个参数是terminationGracePeriodSeconds ,它在接收SIGTERM信号时给予Fluentd 30秒优雅地关闭。 30秒后,向容器发送SIGKILL信号。 terminationGracePeriodSeconds的默认值为30s,因此在大多数情况下可以省略此参数。 要了解有关优雅地终止Kubernetes工作负载的更多信息,请参阅Google的“ Kubernetes最佳实践:终止优雅” 。
整个Fluentd规范看起来应该是这样的:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v0.12-debian-elasticsearch
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENT_UID
value: "0"
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
完成Fluentd DaemonSet的配置后,保存并关闭文件。
现在,使用kubectl推出kubectl :
kubectl create -f fluentd.yaml
您应该看到以下输出:
Outputserviceaccount/fluentd created
clusterrole.rbac.authorization.k8s.io/fluentd created
clusterrolebinding.rbac.authorization.k8s.io/fluentd created
daemonset.extensions/fluentd created
使用kubectl验证您的DaemonSet是否已成功kubectl :
kubectl get ds --namespace=kube-logging
您应该看到以下状态输出:
OutputNAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd 3 3 3 3 3 <none> 58s
这表明有3个fluentd正在运行,这与我们Kubernetes集群中的节点数相对应。
我们现在可以检查Kibana以验证是否正确收集了日志数据并将其发送到Elasticsearch。
在kubectl port-forward仍然打开的情况下,导航到http://localhost:5601 。
单击左侧导航菜单中的Discover 。
您应该看到以下配置窗口:
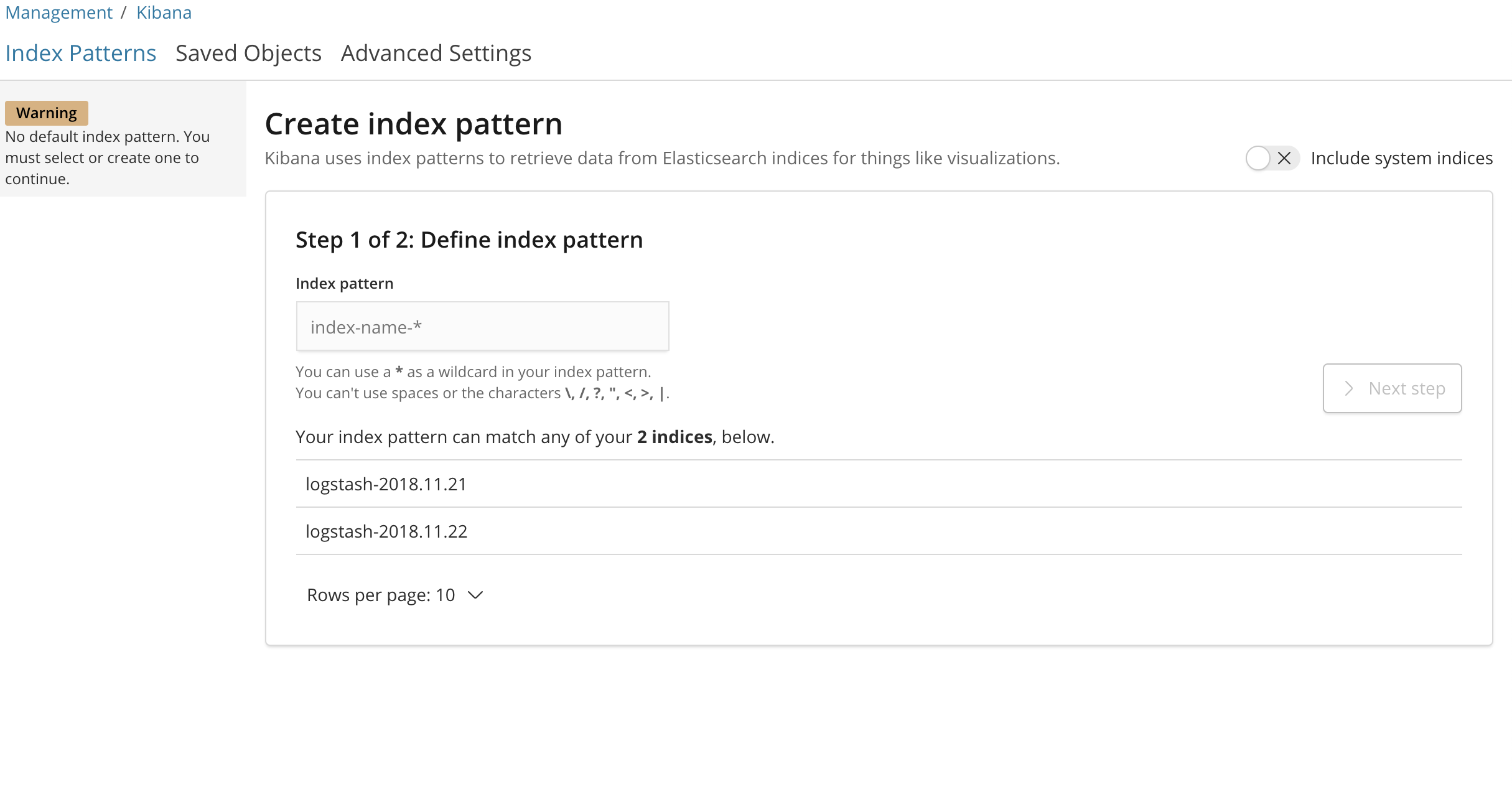
这允许您定义您想要在Kibana中探索的Elasticsearch索引。 要了解更多信息,请参阅官方Kibana文档中的定义索引模式 。 For now, we'll just use the logstash-* wildcard pattern to capture all the log data in our Elasticsearch cluster. Enter logstash-* in the text box and click on Next step .
You'll then be brought to the following page:
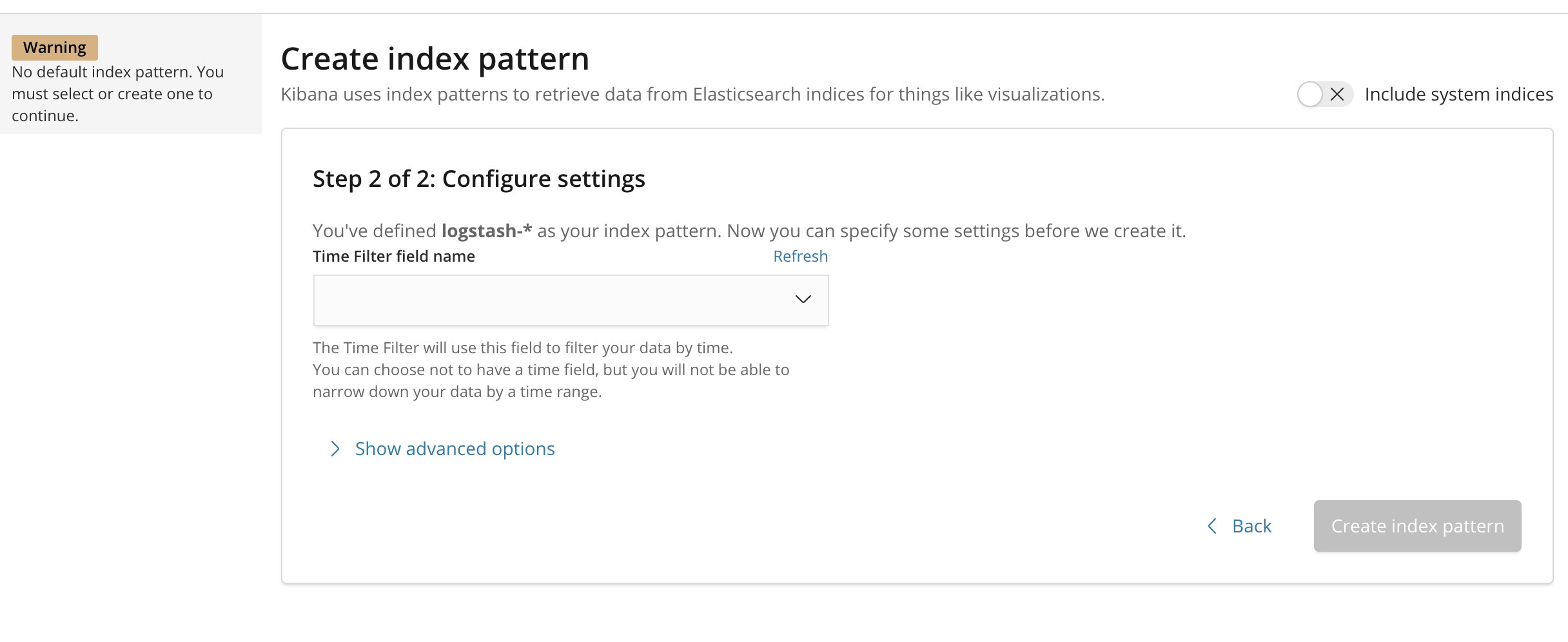
This allows you to configure which field Kibana will use to filter log data by time. In the dropdown, select the @timestamp field, and hit Create index pattern .
Now, hit Discover in the left hand navigation menu.
You should see a histogram graph and some recent log entries:
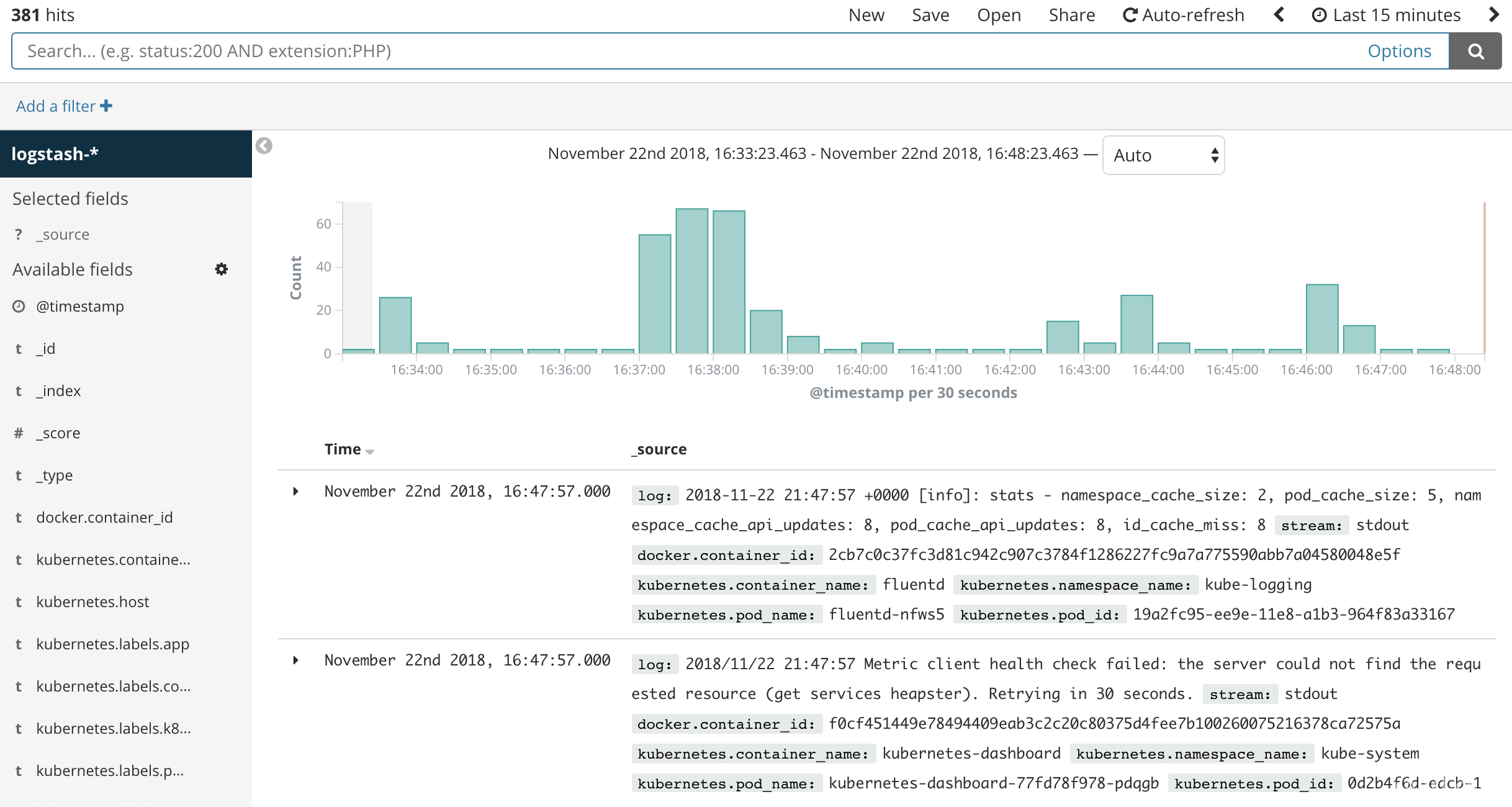
At this point you've successfully configured and rolled out the EFK stack on your Kubernetes cluster. To learn how to use Kibana to analyze your log data, consult the Kibana User Guide .
In the next optional section, we'll deploy a simple counter Pod that prints numbers to stdout, and find its logs in Kibana.
Step 5 (Optional) — Testing Container Logging
To demonstrate a basic Kibana use case of exploring the latest logs for a given Pod, we'll deploy a minimal counter Pod that prints sequential numbers to stdout.
Let's begin by creating the Pod. Open up a file called counter.yaml in your favorite editor:
nano counter.yaml
Then, paste in the following Pod spec:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
保存并关闭文件。
This is a minimal Pod called counter that runs a while loop, printing numbers sequentially.
Deploy the counter Pod using kubectl :
kubectl create -f counter.yaml
Once the Pod has been created and is running, navigate back to your Kibana dashboard.
From the Discover page, in the search bar enter kubernetes.pod_name:counter . This filters the log data for Pods named counter .
You should then see a list of log entries for the counter Pod:
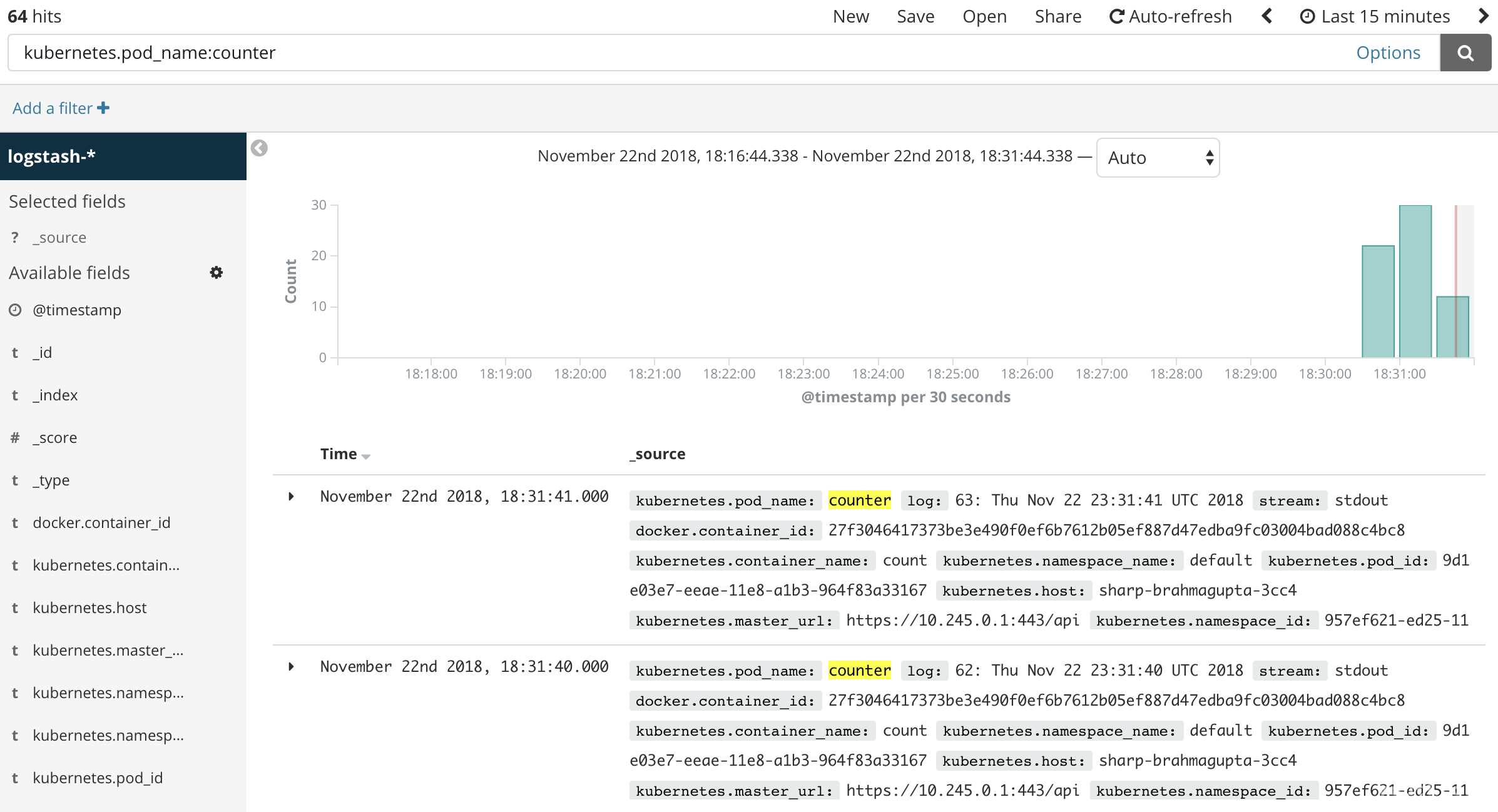
You can click into any of the log entries to see additional metadata like the container name, Kubernetes node, Namespace, and more.
结论
In this guide we've demonstrated how to set up and configure Elasticsearch, Fluentd, and Kibana on a Kubernetes cluster. We've used a minimal logging architecture that consists of a single logging agent Pod running on each Kubernetes worker node.
Before deploying this logging stack into your production Kubernetes cluster, it's best to tune the resource requirements and limits as indicated throughout this guide. You may also want to use the X-Pack enabled image with built-in monitoring and security.
The logging architecture we've used here consists of 3 Elasticsearch Pods, a single Kibana Pod (not load-balanced), and a set of Fluentd Pods rolled out as a DaemonSet. You may wish to scale this setup depending on your production use case. To learn more about scaling your Elasticsearch and Kibana stack, consult Scaling Elasticsearch .
Kubernetes also allows for more complex logging agent architectures that may better suit your use case. To learn more, consult Logging Architecture from the Kubernetes docs.







