使用Tesseract OCR在Ubuntu 7.04上进行光学字符识别
版本1.0
作者:Oliver Meyer <o [dot] meyer [at] projektfarm [dot] de>
本文档介绍如何在Ubuntu 7.04上设置Tesseract OCR。 OCR表示“光学字符识别”。 所得到的系统将能够将具有嵌入文本的图像转换为文本文件。 Tesseract是根据Apache许可证v2.0授权的 。
这是一个实践指南; 它不包括理论背景。 他们在网络上的许多其他文档中被处理。
本文档不附带任何形式的保证! 我想说,这不是设立这样一个制度的唯一办法。 实现这一目标有很多方法,但这是我所采取的方式。 我不会保证这将为您工作!
1准备
设置一个基本的Ubuntu 7.04系统并进行更新。
自动获取扫描图像或扫描文档。
如果您使用的是扫描仪,请确保正确地支持扫描仪。 支持的设备列表可从http://www.sane-project.org/ 获取 。
2 Get Imagemagick
Ubuntu存储库中提供的tesseract的当前版本仅支持未压缩和G3压缩的tiff文件。
为了确保tesseract能够处理您的图像,您应该将它们转换为未压缩的tiff。
由于使用Gimp进行未压缩tiff的转换不可用,因此我使用了由Imagemagick软件包提供的转换工具。
使用Synaptic包管理器从Ubuntu存储库安装Imagemagick。
3获取Tesseract
使用Synaptic软件包管理器从Ubuntu存储库安装软件包tesseract-ocr和tesseract-ocr-data 。
4准备图像
要从tesseract获得最佳效果,您必须优化图像。 我建议使用最小分辨率约为200dpi的图像。
我使用Gimp进行以下第4步.1 - 4.3。
4.1清洁
从图像中删除任何非字母数字内容,以防止tesseract产生混乱的文本块。
这可以通过Gimp中的擦除工具轻松完成。
4.2阈值
将图像转换为RGB或灰度模式。
在gimp内
图像 - 模式 - RGB或灰度
使用阈值功能减少偏光照明并清除碎片。 移动滑块以定义明暗区域。 观看预览时,可以看到图像上的效果。
在Gimp内:
Tools - Color Tools - Threshold
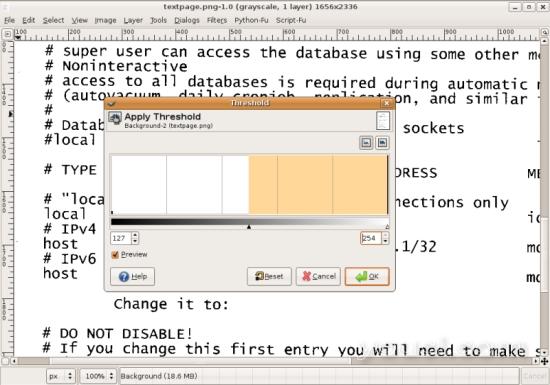
4.3黑白
为了改善文本识别,我们通过将图像切换到索引模式,将颜色减少为黑色。
在Gimp内:
Image - Mode - Indexed
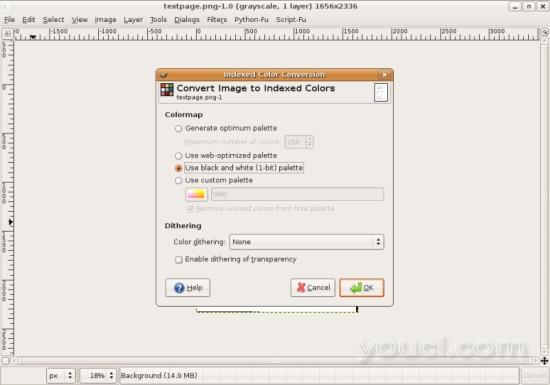
确保关闭抖动。
此步骤后保存图像。
5转换为Tiff
现在你必须将图像转换为未压缩的tiff。
convert %source_file% %destination_file%
例如:
convert document.jpg document.tif
6使用Tesseract
在这一点上,所有的准备工作都完成了,所以你可以开始使用tesseract。
tesseract %tiff_file% %name_for_resulting_files%
例如:
tesseract document.tif result
Tesseract为生成的文件本身添加文件扩展名。 在这个例子中,tesseract会创建result.txt , result.map和result.raw 。
链接
- Tesseract: http : //sourceforge.net/projects/tesseract-ocr
- Sane: http : //www.sane-project.org/
- Ubuntu: http : //www.ubuntu.com/







