NLTK代表“自然语言工具包”。 它是一个用于清理和处理人类语言数据的python编程模块。 其丰富的内置工具可帮助我们轻松构建自然语言处理领域(又称NLP)的应用程序。
语料库是以特定语言存在的一组单词,NLTK提供超过50种不同的语料库来处理和提供核心图书馆,如POS标签,语音结尾标记,标记化,语义推理,分类等。以下简要描述NLP中使用的5个主要功能或步骤,可以使用NLTK轻松执行:
- 语音结尾标签(EOS标签):这涉及到将文本制作成有意义句子的集合。
- 标记:将句子分解成单词。 它不仅适用于白色空间,而且还可以删除像(。,?,!等)这样的禁用词,它是一个集合,这意味着重复的单词被删除。
- 语音标签(POS标签)的一部分:标记词表示字的类型。 标签被编码。 名词,过去式动词等,所以每个单词都有一个标签。
- 分块:使用类似标签分组单词的过程。 分块的结果将是一棵树结构。
- 提取:一旦数据分块,我们可以只提取名词,或只提取动词等来满足需求。
现在,这可能看起来很酷,但这是可以使用的最好的模块吗? 那么这个答案取决于手头的任务。 一般来说,NLTK很慢,但非常准确。 还有像PsyKit这样的其他模块,它的速度更快,但是在精确度方面有一个权衡。因此,对于准确度超前的应用,NLTK是正确的选择。 这个帖子显示了NLTK如何安装和使用一个例子。
2下载并安装NLTK
可以使用“pip”安装程序轻松安装NLTK。 在安装NLTK之前,我们还要安装numpy。使用以下命令:
sudo pip install -U numpy
sudo pip install -U nltk
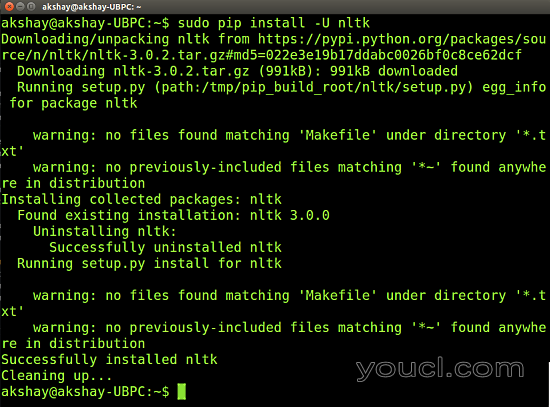
下图显示nltk的执行。 请注意,安装numpy是类似的,但是可能需要更多的时间才能安装,具体取决于系统的处理器。
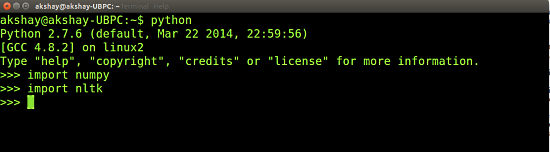
完成后,您可以通过使用下图中的2个命令来测试是否已正确安装,并确保运行时没有错误。
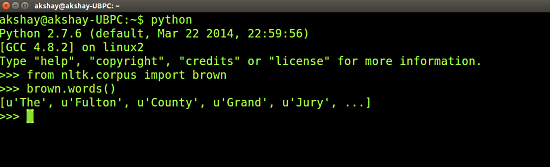
3安装NLTK数据
一旦您确认已安装nltk,我们将不得不下载并安装NLTK数据。 Nltk数据由语料库和语言中的所有单词以及各种语法语法,玩具语法,训练模型等组成。它们通过应用各种功能帮助用户轻松处理语言。 请注意,安装nltk数据是一个漫长的过程,它涉及下载超过1 GB的数据。 要下载nltk数据,在终端类型“python”中打开python解释器,并键入以下两个命令:
>>> import nltk >>> nltk.download()
应打开一个新窗口,显示nltk下载。 安装在“usr / share / nltk_data”文件夹中。 一旦完成测试,如果已经通过键入命令并获取输出,如下图所示下载。
4使用NLTK的示例
现在我们可以尝试使用NLTK执行的NLP任务的一些示例。 EOS检测,令牌化,POS标签,分块和提取的5个过程如下:
4.1 EOS检测
语言结尾的标签将文本分解成有意义的句子集合。 我们这样做是因为对单个句子的进一步的工作。 以下是EOS检测的示例和输出。
>>> import nltk >>> text = "Mrs. Hudson made a cup of tea. She is a wonderful woman." >>> sentences = nltk.tokenize.sent_tokenize(text) >>> sentences ['Mrs. Hudson made a cup of tea.', 'She is a wonderful woman.'] >>>
使用nltk的语料库可以在上面看到。 知道“太太” 不是一个句子,而是一个缩写。 因此,它被作为一个句子的一部分而不是一个句子。
4.2令牌化
这个步骤对单个句子进行操作,将它们分成令牌。 所以我们得到一个包含令牌的列表。 下面的例子是上一步的继续。
>>> tokens = [nltk.tokenize.word_tokenize(s) for s in sentences] >>> tokens [['Mrs.', 'Hudson', 'made', 'a', 'cup', 'of', 'tea', '.'], ['She', 'is', 'a', 'wonderful', 'woman', '.']] >>>
这里我们可以看到,令牌不仅由单词组成,而且还包括句子的结尾。 重要的是要注意,令牌化不仅将句子分解成单词,而且还具有将句子分解成令牌的能力,其中空格不是字符来分隔单词。
4.3 POS标签
POS表示说Discourse音,并且在该步骤中,POS信息被分配给令牌列表中的每个令牌。 这些POS信息中的每一个表示它是什么样的语音。 例如,标签“VBD”表示一种简单的过去时态的动词,“JJ”表示形容词。 此步骤有助于我们在下一步安排或订购这些单词。 下面给出了一个例子。
>>> PosTokens = [nltk.pos_tag(e) for e in tokens]
>>> PosTokens
[[('Mrs.', 'NNP'), ('Hudson', 'NNP'), ('made', 'VBD'), ('a', 'DT'), ('cup', 'NN'), ('of', 'IN'), ('tea', 'NN'),
('.', '.')], [('She', 'PRP'), ('is', 'VBZ'), ('a', 'DT'), ('wonderful', 'JJ'), ('woman', 'NN'), ('.', '.')]]
>>>
4.4分块和提取
分块是指基于标签组合复杂标记的过程。 Nltk还允许为分块定义一个自定义语法。 另一方面,提取是指通过现有块并将其标记为命名实体的过程,如人员,组织,位置等示例:
>>> chunks = nltk.ne_chunk_sents(PosTokens) >>> for each in chunks: ... print each ... (S Mrs./NNP (PERSON Hudson/NNP) made/VBD a/DT cup/NN of/IN tea/NN ./.) (S She/PRP is/VBZ a/DT wonderful/JJ woman/NN ./.) >>>
我们可以看到,哈德森夫人已经被认定为一个人。 所有这些信息都以树的形式存储。
5结论
从上面给出的样本,我们可以看到我们能够轻松地处理数据。 一旦应用了这五个步骤,我们可以继续应用各种算法来处理/排列数据,并从中提取有用的信息。 可以使用的一个例子是“自动文本摘要”。 总而言之,与其他人相比,Nltk是一个强大的,准确的,有点慢的工具。 它可以用于优先考虑精度的应用。
6官方链接
有关nltk的数百项任务和功能的详细使用信息,请访问其官方网站: http : //www.nltk.org/genindex.html







