介绍
许多数据分析,大数据和机器学习项目都需要抓取网站来收集您将要使用的数据。 Python编程语言被广泛应用于数据科学界,因此具有您在自己的项目中使用的模块和工具的生态系统。 在本教程中,我们将专注于美丽的汤模块。
美丽的汤 ,是对刘易斯卡罗尔的“ 爱丽丝梦游仙境”第10章中发现的模仿龟的歌曲的一个引用,是一个Python图书馆,可以快速绕过网络刮刮项目。 美丽的汤4目前可用,与Python 2.7和Python 3兼容,Beautiful Soup从解析的HTML和XML文档(包括带有非封闭标签的文档或标签汤和其他格式错误的标记)创建了一个解析树。
在本教程中,我们将收集和解析一个网页,以便抓取文本数据并将我们收集的信息写入CSV文件。
先决条件
在使用本教程之前,您应该在您的机器上设置本地或基于服务器的 Python编程环境。
您应该安装“请求和美丽的汤”模块,您可以通过遵循我们的教程“ 如何使用使用请求和使用Python 3的美丽汤的Web数据 ”实现。通过熟悉这些模块也很有用。
另外,由于我们将处理从网络上刮下来的数据,所以您应该对HTML结构和标记感到满意。
了解数据
在本教程中,我们将使用美国国家艺术馆官方网站上的数据。 国家美术馆是位于华盛顿特区国家购物中心的艺术博物馆,拥有超过12万件文艺复兴时期,至今已有13,000多名艺术家。
我们想搜索“艺术家索引”, 网址是https://www.nga.gov/collection/an.shtm 。
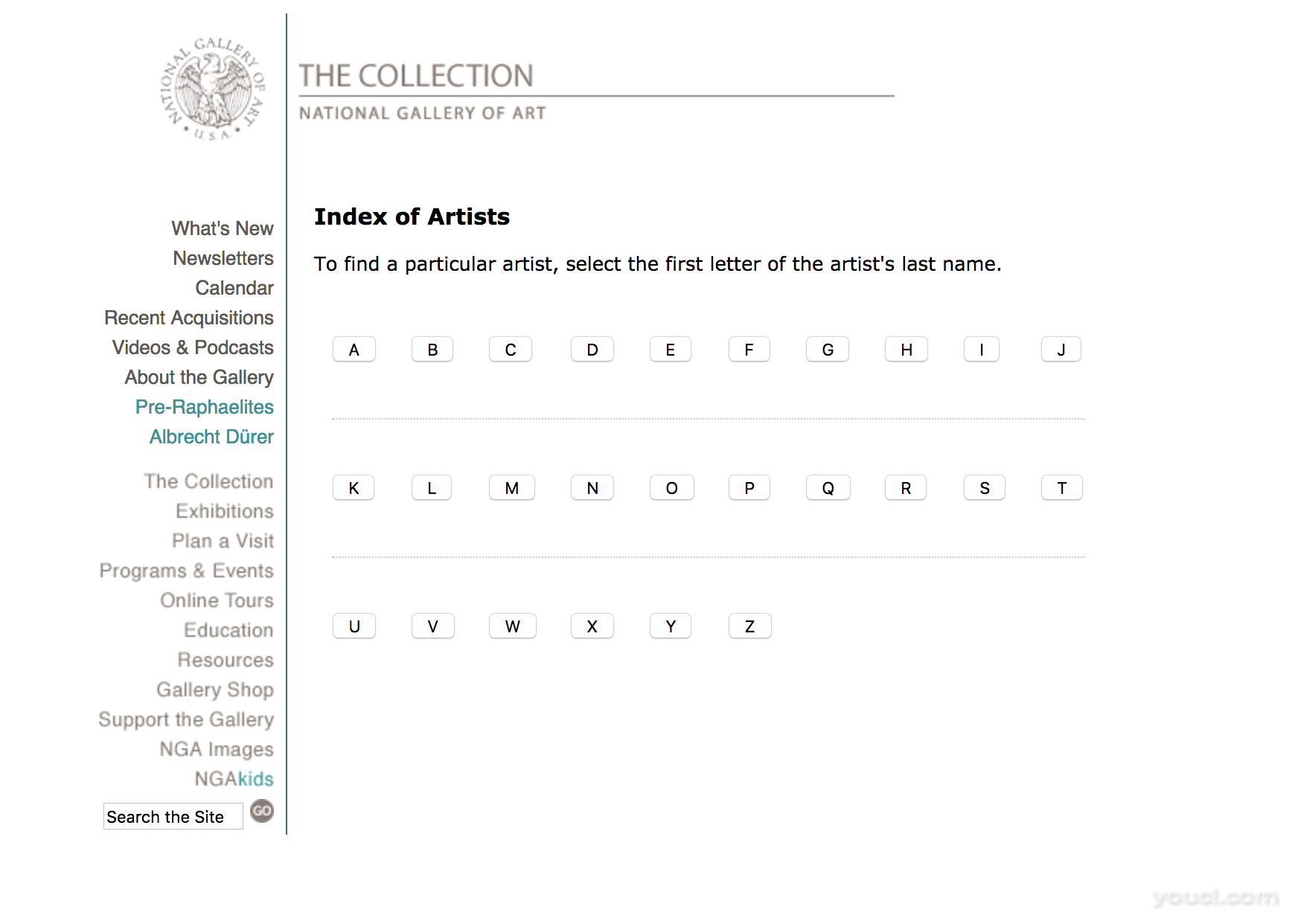
由于我们将要完成这个项目,以了解如何利用美丽的汤来学习网页抓取,所以我们不需要从网站上提取太多的数据,所以我们来限制我们正在寻找的艺术家数据的范围。 因此,我们选择一个字母 - 在我们的例子中,我们将选择字母Z - 我们将看到一个如下所示的页面:

在上面的页面中,我们看到,在撰写本文时列出的第一位艺术家是Zabaglia,Niccola ,当我们开始提取数据时,这是一件好事。 我们先从第一页开始,使用以下字母Z的 URL:
https://www.nga.gov/collection/anZ1.htm
重要的是要注意到您选择列出的信件有多少页,您可以通过点击到艺术家的最后一页来发现。 在这种情况下,共有5页,而在写作时列出的最后一位艺术家是Zykmund,Václav 。 Z艺术家的最后一页有以下URL:
https://www.nga.gov/collection/anZ5.htm
要开始熟悉此网页的DOM,您可以打开浏览器的开发工具 。
导入图书馆
要开始我们的编码项目,让我们激活我们的Python 3编程环境。 确保您位于您的环境所在的目录中,并运行以下命令:
. my_env/bin/activate
随着我们的编程环境的激活,我们将创建一个新的文件,例如nano。 您可以为您的文件命名任何您想要的,我们将在本教程中称之为nga_z_artists.py 。
nano nga_z_artists.py
在这个文件中,我们可以开始导入我们将要使用的库 - 请求和美丽的汤。
请求库允许您以可读的方式在Python程序中使用HTTP,而美丽的Soup模块旨在快速完成Web抓取。
我们将使用import语句导入“请求”和“Beautiful Soup”。 对于美丽的汤,我们将从bs4导入美丽汤4的包装。
# Import libraries
import requests
from bs4 import BeautifulSoup
随着请求和Beautiful Soup模块的导入,我们可以继续工作,首先收集一个页面,然后解析它。
收集和分析网页
我们需要做的下一步是使用请求收集第一个网页的URL。 我们将使用requests.get()方法将第一页的URL分配给变量 page 。
import requests
from bs4 import BeautifulSoup
# Collect first page of artists’ list
page = requests.get('https://www.nga.gov/collection/anZ1.htm')
接下来,我们将创建一个BeautifulSoup对象或一个解析树。 该对象将其从参数(请求(服务器的响应内容)中的page.text文档作为参数,然后从Python的内置html.parser解析出来。
import requests
from bs4 import BeautifulSoup
page = requests.get('https://www.nga.gov/collection/anZ1.htm')
# Create a BeautifulSoup object
soup = BeautifulSoup(page.text, 'html.parser')
现在我们的页面被收集,解析并设置为BeautifulSoup对象,我们可以继续收集我们想要的数据。
从Web页面拉取文本
对于这个项目,我们将收集艺术家的名字和网站上提供的相关链接。 您可能需要收集不同的数据,例如艺术家的国籍和日期。 无论您想收集什么数据,您需要了解Web页面的DOM如何描述。
为此,在您的网络浏览器中,右键单击 - 或CTRL +单击macOS - 第一个艺术家的名字, Zabaglia,Niccola 。 在弹出的上下文菜单中,您应该会看到类似于Inspect Element (Firefox)或Inspect (Chrome)的菜单项。
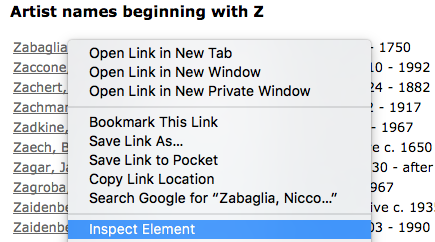
一旦您点击相关的Inspect菜单项,Web开发人员的工具就会出现在您的浏览器中。 我们要查找与此列表中艺术家姓名相关联的类和标签。
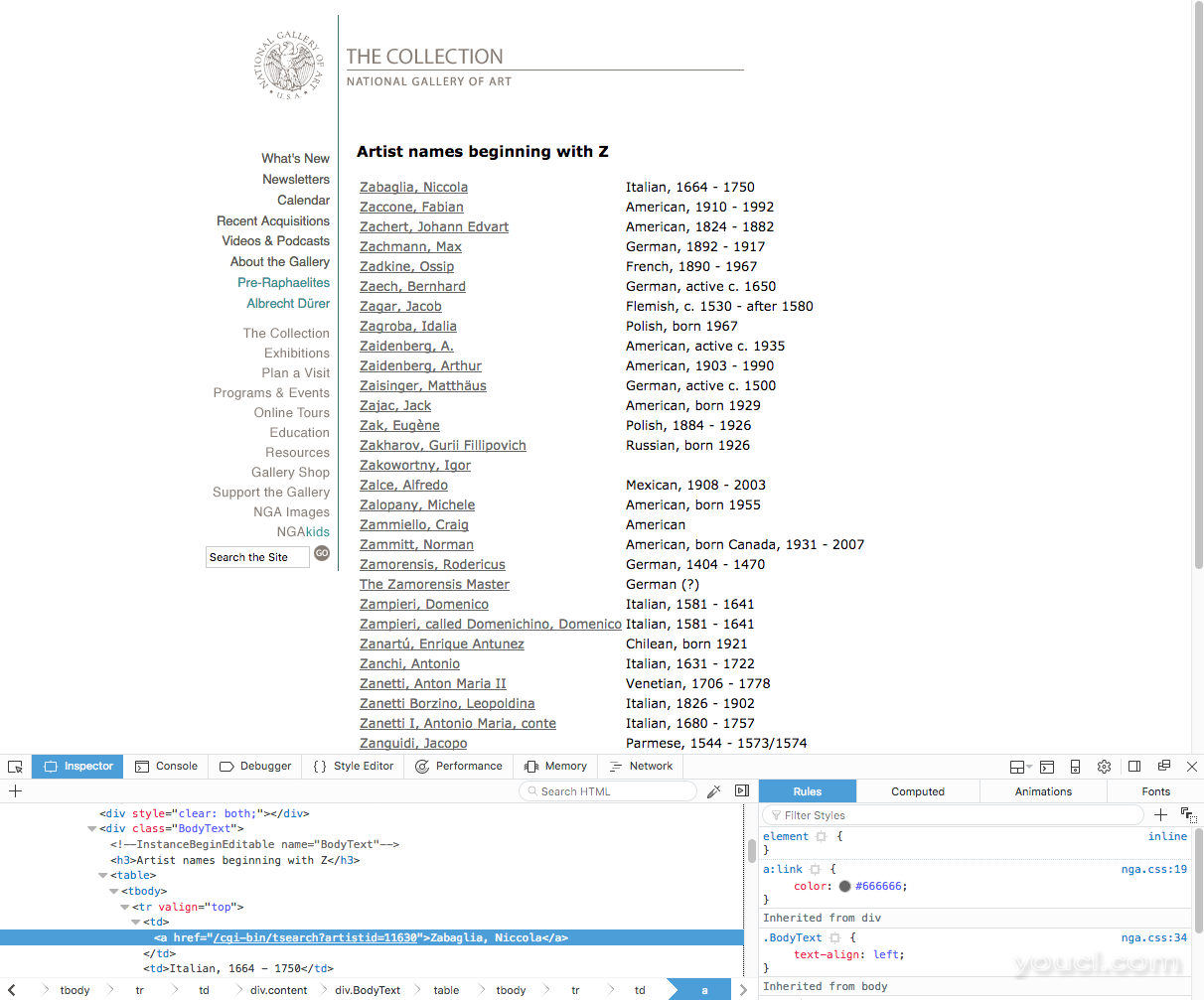
我们首先看到名字表在class="BodyText" <div>标签中。 这很重要,以便我们只在网页的这一部分搜索文本。 我们还注意到,名称Zabaglia,Niccola是一个链接标签,因为这个名字引用了描述艺术家的网页。 所以我们将要引用链接的<a>标签。 每个艺术家的名字都是对链接的引用。
为了做到这一点,我们将使用Beautiful Soup的find()和find_all()方法来从BodyText <div>拉出艺术家名字的文本。
import requests
from bs4 import BeautifulSoup
# Collect and parse first page
page = requests.get('https://www.nga.gov/collection/anZ1.htm')
soup = BeautifulSoup(page.text, 'html.parser')
# Pull all text from the BodyText div
artist_name_list = soup.find(class_='BodyText')
# Pull text from all instances of <a> tag within BodyText div
artist_name_list_items = artist_name_list.find_all('a')
接下来,在我们的程序文件的底部,我们将要创建一个for循环 ,以迭代我们刚刚放入artist_name_list_items变量的所有艺术家名字。
我们将使用prettify()方法打印这些名称,以便将“美丽的汤”解析树变成一个格式正确的Unicode字符串。
...
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
# Create for loop to print out all artists' names
for artist_name in artist_name_list_items:
print(artist_name.prettify())
到目前为止,让我们来运行程序:
python nga_z_artists.py
一旦我们这样做,我们将收到以下输出:
Output<a href="/cgi-bin/tsearch?artistid=11630">
Zabaglia, Niccola
</a>
...
<a href="/cgi-bin/tsearch?artistid=961">
Zanguidi, Jacopo
</a>
<a href="/collection/anZ2.htm">
Zan-Zep
</a>
<a href="/collection/anZ3.htm">
Zer-Zit
</a>
<a href="/collection/anZ4.htm">
Zoa-Zuc
</a>
<a href="/collection/anZ5.htm">
<strong>
next
<br/>
page
</strong>
</a>
我们现在在输出中看到的是与第一页上<div class="BodyText">标签中的<a>标签中所有艺术家名称相关的全文和标签,以及一些底部附加链接文字。 由于我们不想要这些额外的信息,所以我们在下一节中将其删除。
删除多余的数据
到目前为止,我们已经能够在我们网页的一个<div>部分中收集所有链接文本数据。 但是,我们不希望底层链接不能引用艺术家的名字,所以我们来努力去除这部分。
为了删除页面的底部链接,我们再次右键单击并检查 DOM。 我们将看到<div class="BodyText">部分底部的链接包含在HTML表中: <table class="AlphaNav"> :
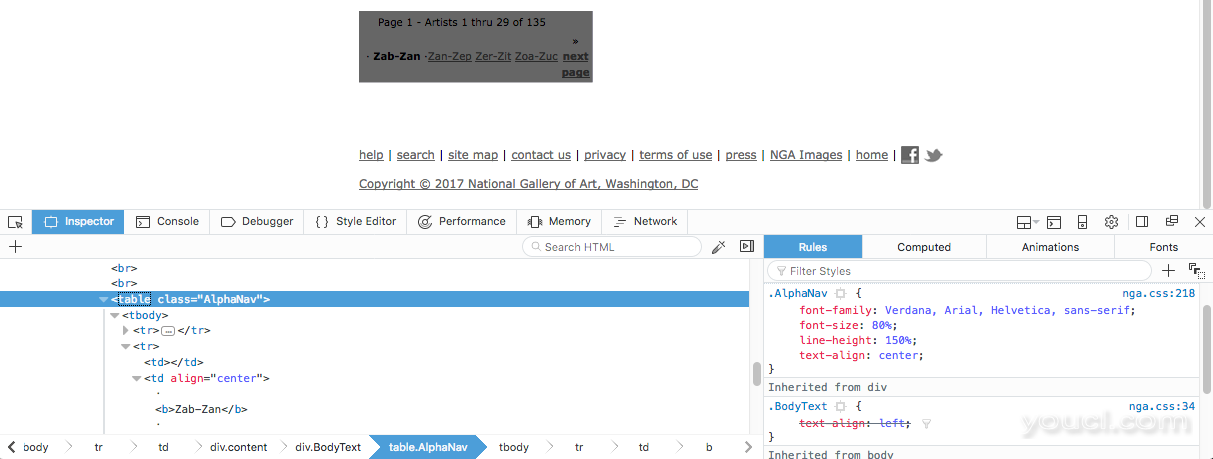
因此,我们可以使用美丽的汤找到AlphaNav类,并使用decompose()方法从解析树中删除标签,然后将其与其内容一起销毁。
我们将使用变量last_links来引用这些底层链接并将它们添加到程序文件中:
import requests
from bs4 import BeautifulSoup
page = requests.get('https://www.nga.gov/collection/anZ1.htm')
soup = BeautifulSoup(page.text, 'html.parser')
# Remove bottom links
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
for artist_name in artist_name_list_items:
print(artist_name.prettify())
现在,当我们使用python nga_z_artist.py命令运行程序时,我们将收到以下输出:
Output<a href="/cgi-bin/tsearch?artistid=11630">
Zabaglia, Niccola
</a>
<a href="/cgi-bin/tsearch?artistid=34202">
Zaccone, Fabian
</a>
...
<a href="/cgi-bin/tsearch?artistid=3454">
Zanetti I, Antonio Maria, conte
</a>
<a href="/cgi-bin/tsearch?artistid=961">
Zanguidi, Jacopo
</a>
此时,我们看到输出不再包含网页底部的链接,现在只显示与艺术家姓名相关联的链接。
到目前为止,我们专门针对与艺术家名称的链接,但我们有不需要的额外的标签数据。 我们在下一节中删除它。
从标签中拉出内容
为了仅访问实际艺术家的名字,我们将要针对<a>标签的内容,而不是打印整个链接标签。
我们可以用Beautiful Soup的.contents ,它将返回标签的孩子作为Python 列表数据类型 。
我们来修改for循环,以便打印整个链接和它的标签,而不是打印孩子列表(即艺术家的全名):
import requests
from bs4 import BeautifulSoup
page = requests.get('https://www.nga.gov/collection/anZ1.htm')
soup = BeautifulSoup(page.text, 'html.parser')
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
# Use .contents to pull out the <a> tag’s children
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
print(names)
请注意,我们通过调用每个项目的索引号遍历上面的列表。
我们可以使用python命令运行程序来查看以下输出:
OutputZabaglia, Niccola
Zaccone, Fabian
Zachert, Johann Edvart
...
Zanetti Borzino, Leopoldina
Zanetti I, Antonio Maria, conte
Zanguidi, Jacopo
我们收到了Z字母第一页上所有艺术家名字的列表。
但是,如果我们想要捕获与这些艺术家相关联的网址呢? 我们可以使用Beautiful Soup的get('href')方法来提取页面的<a>标签中找到的URL。
从上面的链接的输出,我们知道整个URL没有被捕获,所以我们将链接字符串连接到URL字符串的前面(在本例中为https://www.nga.gov )。
这些行我们还将添加到for循环中:
...
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
links = 'https://www.nga.gov' + artist_name.get('href')
print(names)
print(links)
当我们运行上述程序时,我们将收到艺术家的名字和URL链接,告诉我们更多关于艺术家的链接:
OutputZabaglia, Niccola
https://www.nga.gov/cgi-bin/tsearch?artistid=11630
Zaccone, Fabian
https://www.nga.gov/cgi-bin/tsearch?artistid=34202
...
Zanetti I, Antonio Maria, conte
https://www.nga.gov/cgi-bin/tsearch?artistid=3454
Zanguidi, Jacopo
https://www.nga.gov/cgi-bin/tsearch?artistid=961
虽然我们正在从网站获取信息,但目前正在打印到我们的终端窗口。 我们来捕获这些数据,以便我们可以在其他地方将其写入到一个文件中。
将数据写入CSV文件
仅收集终端窗口中的数据并不是很有用。 逗号分隔值(CSV)文件允许我们以纯文本形式存储表格数据,是电子表格和数据库的通用格式。 在开始本节之前,您应该熟悉如何处理Python中的纯文本文件 。
首先,我们需要将Python的内置csv模块与Python编程文件顶部的其他模块一起导入:
import csv
接下来,我们将创建并打开一个名为z-artist-names .csv以便我们使用'w'模式来写入 (我们将在这里使用变量f表示文件)。 我们还将写出顶行标题:我们将作为列表传递给writerow()方法的Name和Link :
f = csv.writer(open('z-artist-names.csv', 'w'))
f.writerow(['Name', 'Link'])
最后,在我们的for循环中,我们将用艺术家的names和相关联的links写出每一行:
f.writerow([names, links])
您可以在下面的文件中看到每个这些任务的行:
import requests
import csv
from bs4 import BeautifulSoup
page = requests.get('https://www.nga.gov/collection/anZ1.htm')
soup = BeautifulSoup(page.text, 'html.parser')
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
# Create a file to write to, add headers row
f = csv.writer(open('z-artist-names.csv', 'w'))
f.writerow(['Name', 'Link'])
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
links = 'https://www.nga.gov' + artist_name.get('href')
# Add each artist’s name and associated link to a row
f.writerow([names, links])
当您使用python命令运行程序时,不会将任何输出返回到您的终端窗口。 相反,将在您正在使用的名为z-artist-names .csv的目录中创建一个文件。
根据您打开它的内容,可能看起来像这样:
Name,Link
"Zabaglia, Niccola",https://www.nga.gov/cgi-bin/tsearch?artistid=11630
"Zaccone, Fabian",https://www.nga.gov/cgi-bin/tsearch?artistid=34202
"Zachert, Johann Edvart",https://www.nga.gov/cgi-bin/tsearch?artistid=35577
"Zachmann, Max",https://www.nga.gov/cgi-bin/tsearch?artistid=46892
"Zadkine, Ossip",https://www.nga.gov/cgi-bin/tsearch?artistid=3475
...
或者,它可能看起来更像一个电子表格:
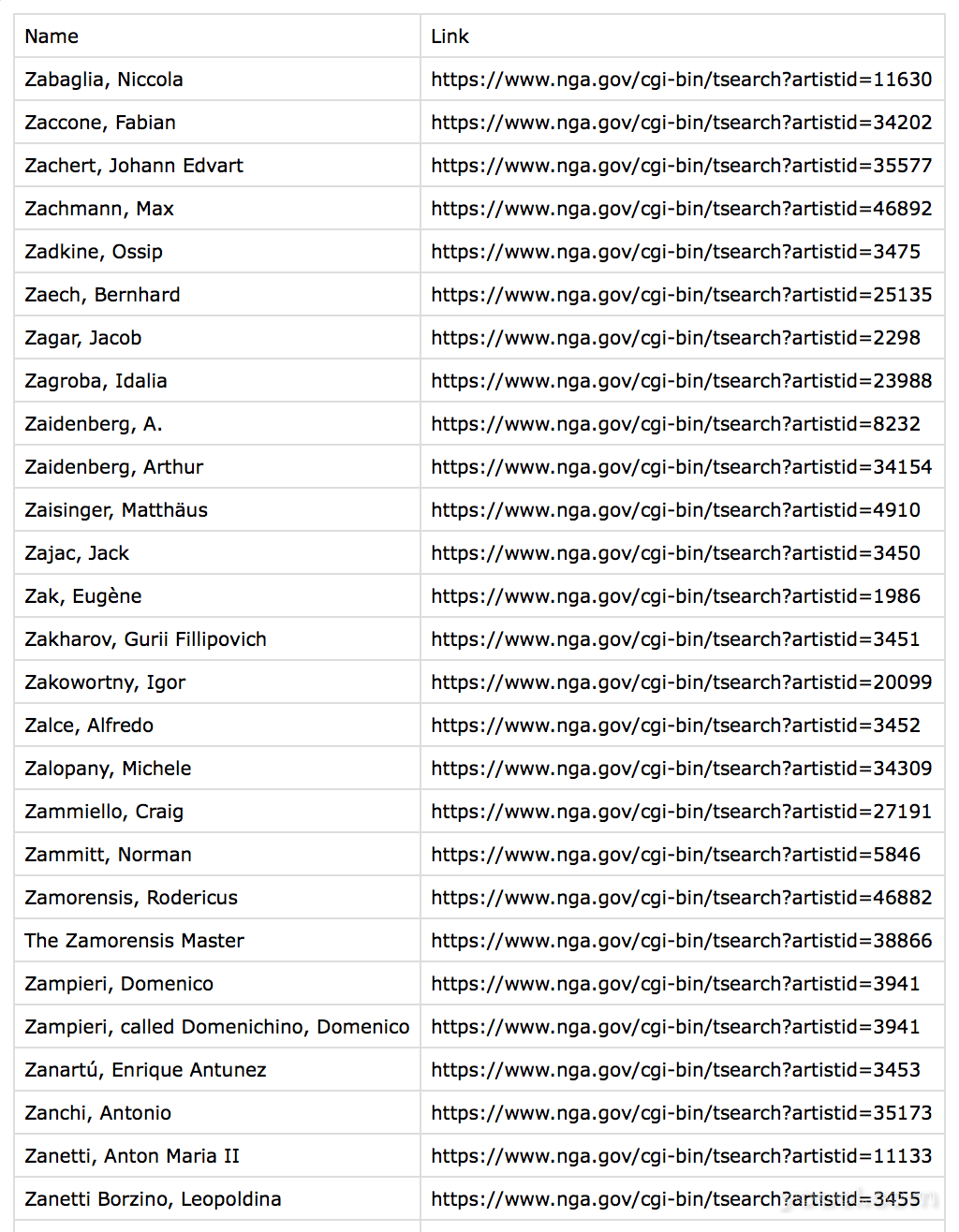
在这两种情况下,您现在可以使用此文件以更有意义的方式处理数据,因为您收集的信息现在存储在计算机的内存中。
检索相关页面
我们创建了一个程序,它将从名字以字母Z开头的艺术家列表的第一页拉出数据。 不过,这些艺术家共有5页在网站上可用。
为了收集所有这些页面,我们可以for循环执行更多的迭代。 这将修改我们迄今编写的大部分代码,但将采用类似的概念。
首先,我们要初始化一个列表来保存页面:
pages = []
我们将使用以下for循环填充此初始化列表:
for i in range(1, 6):
url = 'https://www.nga.gov/collection/anZ' + str(i) + '.htm'
pages.append(url)
在本教程前面 ,我们注意到,我们应该注意包含艺术家名字的页面总数,以字母Z (或任何我们使用的字母)开头。 由于字母Z有5页,我们构造了上面的for循环,范围为1到6以便它遍历5页中的每一页。
对于这个特定的网站,URL以字符串https://www.nga.gov/collection/anZ开头,然后跟随一个页面的数字(这将是我们转换为 for循环的整数i 一个字符串 ),以.htm结尾。 我们将这些字符串连接在一起,然后将结果附加到pages列表。
除了这个循环之外,我们还将有一个第二个循环,将遍历上面的每个页面。 这个for循环中的代码将看起来与我们迄今为止创建的代码类似,因为它正在完成我们为5个页面中的每一页的Z个艺术家的第一页完成的任务。 请注意,因为我们将原始程序放入第二个for循环中,我们现在将原始循环作为其中包含的嵌套for循环 。
两个for循环将如下所示:
pages = []
for i in range(1, 6):
url = 'https://www.nga.gov/collection/anZ' + str(i) + '.htm'
pages.append(url)
for item in pages:
page = requests.get(item)
soup = BeautifulSoup(page.text, 'html.parser')
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
links = 'https://www.nga.gov' + artist_name.get('href')
f.writerow([names, links])
在上面的代码中,您应该看到第一个for循环遍历页面,第二个for循环是从这些页面中删除数据,然后逐行添加每个页面的每一行的艺术家名称和链接。
这两个for循环位于import语句下方,CSV文件创建和写入程序(用于写入文件标题的行)以及pages变量(分配给列表)的初始化。
在编程文件的更大的上下文中,完整的代码如下所示:
import requests
import csv
from bs4 import BeautifulSoup
f = csv.writer(open('z-artist-names.csv', 'w'))
f.writerow(['Name', 'Link'])
pages = []
for i in range(1, 6):
url = 'https://www.nga.gov/collection/anZ' + str(i) + '.htm'
pages.append(url)
for item in pages:
page = requests.get(item)
soup = BeautifulSoup(page.text, 'html.parser')
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
links = 'https://www.nga.gov' + artist_name.get('href')
f.writerow([names, links])
由于这个程序正在做一些工作,所以创建CSV文件需要一点时间。 一旦完成,输出将完成,显示艺术家的名字及其相关链接,从Zabaglia,Niccola到Zykmund,Václav 。
要考虑
当抓取网页时,重要的是要保持考虑您正在抓取信息的服务器。
检查网站是否具有涉及网络刮刮的服务条款或使用条款。 另外,检查网站是否有一个API,您可以在抓取数据之前自己抓取数据。
确保不要连续击中服务器来收集数据。 一旦您从网站收集到您需要的内容,请运行脚本,以便在本地浏览数据,而不是为其他人的服务器负担。
另外,最好用一个标题来查找你的姓名和电子邮件地址,以便一个网站可以识别你并跟进,如果他们有任何问题。 您可以使用Python请求库的标题示例如下:
import requests
headers = {
'User-Agent': 'Your Name, example.com',
'From': 'email@example.com'
}
url = 'https://example.com'
page = requests.get(url, headers = headers)
使用具有可识别信息的标头可确保通过服务器日志的人员可以与您联系。
结论
本教程使用Python和美丽的汤来浏览网站上的数据。 我们将我们收集的文本存储在CSV文件中。
您可以通过收集更多数据并使您的CSV文件更加健壮,继续开展此项目。 例如,您可能希望包括每位艺术家的国籍和年份。 您还可以使用您所学到的来从其他网站上刮取数据。
要继续学习从Web上提取信息,请阅读我们的教程“ 如何使用Scrapy和Python 3抓取Web页面 ”。







