介绍
内存量,缓存大小,读取和写入磁盘的速度以及处理能力的速度和可用性都是影响基础架构性能的关键因素。 在本文中,我们将重点介绍CPU介绍介绍介绍和警报策略。 我们将介绍如何使用两个常见的Linux实用程序( uptime和top )来了解您的CPU负载和利用率,以及如何设置DigitalOcean警报策略以通知您有关Droplet CPU的重大更改。
先决条件
我们讨论的两个实用程序, uptime和top可用作大多数Linux发行版的默认安装的一部分。 要利用DigitalOcean功能,如警报策略,您将需要启用了监视器的DigitalOcean Droplet。
指南介绍了如何在新的Droplet上启用监视,以及如何将Monitoring Agent添加到已经运行的Droplet。
背景
在深入了解uptime , top和DigitalOcean监控的细节之前,我们将考虑如何测量CPU使用情况,以及需要什么样的模式。
CPU负载与CPU利用率
CPU负载和CPU利用率是查看使用计算机处理能力的两种截然不同的方法。
为了概念化两者之间的主要区别,我们可以将处理器设想为杂货店的收银员,并作为客户的任务。 CPU负载就像有一个单一的结帐线,客户等待下一个收银员可用。 负担基本上是排队人数的计数,包括在收银机上的人数。 线越长,等待时间越长。 相比之下, CPU利用率只关心出纳员多么忙碌,不知道有多少客户正在排队等待。
更具体地说,任务排队使用服务器的CPU。 当到达队列的顶部时,它被安排接收一定量的处理时间。 如果完成,则退出; 否则返回到队列的末尾。 在任何一种情况下,下一个任务都在轮到。
CPU负载是计划任务队列的长度,包括正在处理的任务的队列长度。 任务可以在几毫秒内进行切换,因此单个快照的负载并不像在一段时间内获取的几个读数的平均值那么有用,因此负载值通常作为负载平均值提供。
CPU负载告诉我们CPU时间有多少需求。 高需求可能导致CPU时间的争夺和性能下降。
另一方面, CPU利用率告诉我们CPU有多忙,没有意识到有多少进程正在等待。 监控利用率可以显示随时间的趋势,突出显示峰值,并帮助识别不需要的活动,
非归一化与归一化值
在单处理器系统上,总容量始终为1.在多处理器系统上,数据可以以两种不同的方式显示。 无论处理器数量多少,所有处理器的组合容量都被视为100%,这被称为归一化。 另一种选择是将每个处理器作为一个单元进行计数,使得充分利用的2处理器系统的容量为200%,全面使用的4处理器系统容量为400%,等等。
为了正确解释CPU负载或使用量数据,我们需要知道服务器有多少个处理器。
显示CPU信息
我们可以使用带有--all选项的nproc命令来显示处理器数量。 没有--all标志,它将显示当前进程可用的处理单元数,这将少于处理器总数(如果有的话)。
nproc --all
Output of nproc2
在大多数现代Linux发行版中,我们还可以使用lscpu命令,它不仅显示处理器数量,还显示了体系结构,型号名称,速度等等。
lscpu
Output of lscpuArchitecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 2
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2650L v3 @ 1.80GHz
Stepping: 2
CPU MHz: 1797.917
BogoMIPS: 3595.83
Virtualization: VT-x
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 30720K
NUMA node0 CPU(s): 0,1
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl eagerfpu pni pclmulqdq vmx ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm vnmi ept fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt arat
了解处理器的数量对于了解不同工具的CPU相关输出实际意义重要。
负载和利用的最佳值是甚么?
最佳CPU利用率取决于服务器预期的工作类型。 持续的高CPU使用率与系统的响应性较低的交互性的代价。 通常,适用于计算密集型应用程序和批处理作业可以始终运行在或接近满容量。 然而,如果系统预期为诸如SSH的服务提供网页或提供响应式交互式会话,那么可能希望有一些空闲处理能力可用。
像性能的许多方面一样,了解系统上服务的具体需求和监测意外变化是优化资源的关键。
监控CPU
有许多工具能够深入了解系统的CPU状态。 我们将看看两个命令, uptime和top 。 两者都是大多数流行的Linux发行版的默认安装的一部分,并且通常按需要调查CPU负载和利用率。 在下面的例子中,我们将对上面我们分析的2核Droplet进行检查。
运行时间
我们将从uptime命令开始,查看CPU负载,尽管仅显示基本的CPU负载平均值,但是当系统对交互式查询的响应缓慢时,由于需要较少的系统资源,因此可能会有所帮助。
正常运行时间显示:
- 运行命令时的系统时间
- 服务器运行了多长时间
- 用户对机器的连接数量
- 过去一,五和十五分钟的CPU负载平均值。
uptime
Output 14:08:15 up 22:54, 2 users, load average: 2.00, 1.37, 0.63
在这个例子中,这个命令是在服务器上的下午2:08运行的,这个服务器已经持续了将近23个小时。 两个用户在uptime运行时连接。 由于该服务器具有2个CPU,因此在命令运行前的一分钟内,CPU负载平均值为2.00意味着在平均时间内,两个进程平均使用CPU,没有进程正在等待。 5分钟负载平均值表示,对于某些间隔时间,大约60%的时间有一个空闲处理器。 15分钟的值表示有更多的可用处理时间。 三位数字在过去十五分钟内显示了负载的增加。
正常运行时间提供了有用的扫视负载平均值,但是为了获得更多的深入信息,我们将转向顶部。
最佳
像uptime一样,top可以在Linux和Unix系统上使用,除了显示预设历史间隔的负载平均值之外,它还提供周期性的实时CPU使用信息以及其他相关的性能指标。 而uptime运行和退出,顶部停留在前台,并定期刷新。
top
标题块
前五行提供有关服务器上进程的摘要信息:
Outputtop - 18:31:30 up 1 day, 3:17, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 114 total, 1 running, 113 sleeping, 0 stopped, 0 zombie
%Cpu(s): 7.7 us, 0.0 sy, 0.0 ni, 92.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.1 st
KiB Mem : 4046532 total, 3238884 free, 73020 used, 734628 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 3694712 avail Mem
- 第一行几乎与
uptime的输出相同。 像uptime一样,显示一个,五个和十五分钟的负载平均值。 该行和uptime的输出之间的唯一区别是,行的开头显示命令名称,top,并且每次top刷新数据时更新时间。 - 第二行提供了任务状态的总结:进程的总数,其次是有多少个正在运行,睡眠,停止或僵尸。
- 第三行告诉我们CPU利用率。 这些数字被归一化并显示为百分比(不含%符号),因此无论CPU数量多少,此行上的所有值都应加起来为100%。
- 标题信息的第四行和第五行分别告诉我们有关内存和交换使用情况。
最后,标题块后面是一个表,其中包含有关每个进程的信息,我们稍后再看看。
在下面的示例标题块中,一分钟的负载平均数超过了处理器数量.77,表示具有一点点等待时间的短队列。 总CPU容量是100%利用率,并且有大量的可用内存。
Outputtop - 14:36:05 up 23:22, 2 users, load average: 2.77, 2.27, 1.91
Tasks: 117 total, 3 running, 114 sleeping, 0 stopped, 0 zombie
%Cpu(s): 98.3 us, 0.2 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.2 si, 1.3 st
KiB Mem : 4046532 total, 3244112 free, 72372 used, 730048 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 3695452 avail Mem
. . .
我们来看看CPU行上的每个字段更深入:
我们,用户:时间运行un-niced用户进程
该类别是指没有显式调度优先级启动的用户进程。
更具体地说,Linux系统使用nice命令来设置进程的调度优先级 ,因此“un-niced”表示没有使用nice来更改默认值。 用户和漂亮的值占所有用户进程。 此类别中的高CPU使用可能会导致失控过程,您可以使用进程表中的输出来确定是否是这种情况。sy,系统:运行内核进程的时间
大多数应用程序都具有用户和内核组件。 当Linux内核正在进行系统调用,检查权限或代表应用程序与设备进行交互时,内核会显示CPU的使用情况。 当一个进程做自己的工作时,它将出现在上述用户图中,或者如果使用nice命令明确设置优先级,则在下面的漂亮图中。ni,nice:时间运行niced用户进程
像用户一样,这是指不涉及内核的进程任务。 与用户不同,这些任务的调度优先级已被明确设置。 进程的精细度在标题NI下的进程表的第四列中显示。 消耗大量CPU时间的1到20之间的精度值的进程通常不是问题,因为具有正常或更高优先级的任务将在需要时获得处理能力。 但是,如果在-1到-20之间升高的任务正在占用CPU数量不成比例的任务,那么它们很容易影响系统的响应速度,值得进一步的调查。 请注意,由内核生成的调度优先级最高的-19或-20的许多进程都是由内核产生的,用于执行影响系统稳定性的重要任务。 如果您不了解您所看到的流程,则应该谨慎对其进行调查,而不是杀死他们。id,idle:在内核空闲处理程序中花费的时间
该图表示CPU可用和空闲的时间百分比。 当用户 , 好的和空闲的数字组合在一起时,系统通常处于CPU的良好工作状态,接近100%。wa,IO-wait:等待I / O完成的时间
IO等待图显示处理器何时开始读取或写入活动并正在等待I / O操作完成。 远程资源(如NFS和LDAP)的读/写任务也将计入IO等待。 像空闲时间一样,这里的峰值是正常的,但是在这种状态下任何频繁或持续的时间表明这是一个低效的任务,一个缓慢的设备或潜在的硬盘问题。嗨:用于维护硬件中断的时间
这是从外围设备(如磁盘和硬件网络接口)发送到CPU的物理中断所花费的时间。 当硬件中断值为高电平时,外围设备之一可能无法正常工作。si:维护软件中断所花费的时间
软件中断由进程而不是物理设备发送。 与CPU级别发生的硬件中断不同,软件中断发生在内核级别。 当软件中断值使用大量处理能力时,请查看正在使用CPU的具体进程。st:由管理程序从这个vm中偷走的时间
“窃取”值是指虚拟CPU花费多少时间等待物理CPU,而管理程序正在为自己或不同的虚拟CPU进行服务。 基本上,此字段中CPU使用量表示您的虚拟机准备使用多少处理能力,但由于物理主机或其他虚拟机正在使用哪些处理能力,您的应用程序不可用。 一般来说,短时间内偷窃价值高达10%是不值得关注的。 更长时间的偷窃数量较大可能表明物理服务器对CPU的需求比可支持的要高。
现在我们已经看了top的头部块中提供的CPU使用情况的总结,我们将看一下下面显示的进程表,注意CPU特定的列。
过程表
在任何状态下,在服务器上运行的所有进程都在摘要块下列出。 下面的示例包含上面部分top命令中进程表的前六行。 默认情况下,进程表按照%CPU进行排序,因此我们先看到处理CPU最多的进程。
Output
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9966 sammy 20 0 9528 96 0 R 99.7 0.0 0:40.53 stress
9967 sammy 20 0 9528 96 0 R 99.3 0.0 0:40.38 stress
7 root 20 0 0 0 0 S 0.3 0.0 0:01.86 rcu_sched
1431 root 10 -10 7772 4556 2448 S 0.3 0.1 0:22.45 iscsid
9968 root 20 0 42556 3604 3012 R 0.3 0.1 0:00.08 top
9977 root 20 0 96080 6556 5668 S 0.3 0.2 0:00.01 sshd
...
CPU%显示为百分比值,但不是正常化,所以在这个双核系统上,当两个处理器都被充分利用时,进程表中所有值的总和应该加起来高达200%。
注意:如果您希望查看归一化值,可以按SHIFT + I,显示将从Irix模式切换到Solaris模式。 这将显示与服务器总CPU数相同的信息,以便所使用的数量不会超过100%。 当我们切换到Solaris模式时,我们将得到一个简短的信息,即Irix模式是关闭的,我们的压力过程的值将从几乎100%转换到每个约50%。
Output PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10081 sammy 20 0 9528 96 0 R 50.0 0.0 0:49.18 stress
10082 sammy 20 0 9528 96 0 R 50.0 0.0 0:49.08 stress
1439 root 20 0 223832 27012 14048 S 0.2 0.7 0:11.07 snapd
1 root 20 0 39832 5868 4020 S 0.0 0.1 0:07.31 systemd
到目前为止,我们已经在两个通常用于查看CPU负载和CPU利用率的Linux命令中进行了检查。 在下一节中,我们将对DigitalOcean Droplet免费提供CPU监控工具。
DigitalOcean监控CPU利用率
默认情况下,当您单击“控制面板”中的“滴液”名称时,所有“Droplet”显示带宽,CPU和磁盘I / O图形:
这些图可视化每个资源在过去6小时,24小时,7天和24小时的使用情况。 CPU图提供CPU利用率信息。 深蓝色线表示用户进程的CPU使用。 浅蓝色表示系统进程使用的CPU。 图形上的值及其细节被归一化,使得总容量为100%,而不考虑虚拟核心数量。
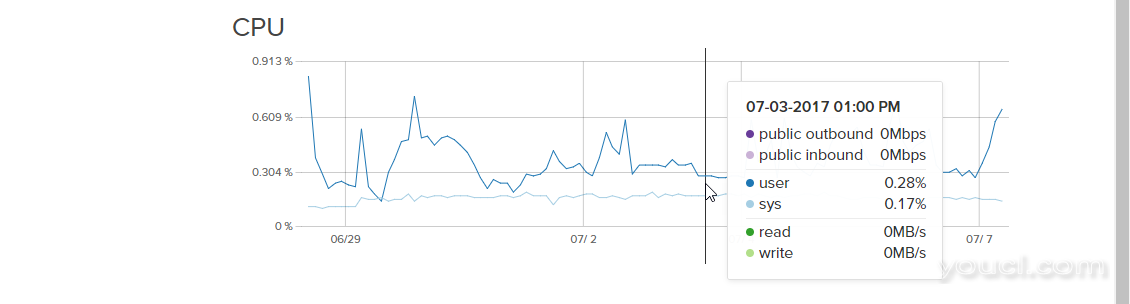
这些图表可让您了解您是否正在经历间歇性或持续使用更改,并有助于发现服务器CPU使用模式中的更改。
除了这些默认图形之外,您还可以在Droplet上安装DigitalOcean Agent,以收集和显示其他数据。 代理还允许您为系统设置警报策略。 可以帮助您设置。
安装代理后,您可以设置警报策略来通知您有关资源使用情况。 您选择的阈值将取决于工作负载。
示例警报
监控变化:CPU高于1%
如果您使用Droplet主要用于集成和保存测试代码,那么您可能会设置一个略高于历史模式的警报,以便检测是否将新的代码推送到服务器,从而增加CPU使用率。 对于上图中CPU从未达到1%的图表,5分钟CPU使用率为1%的阈值可以提供有关基于代码的更改影响CPU使用的预警。
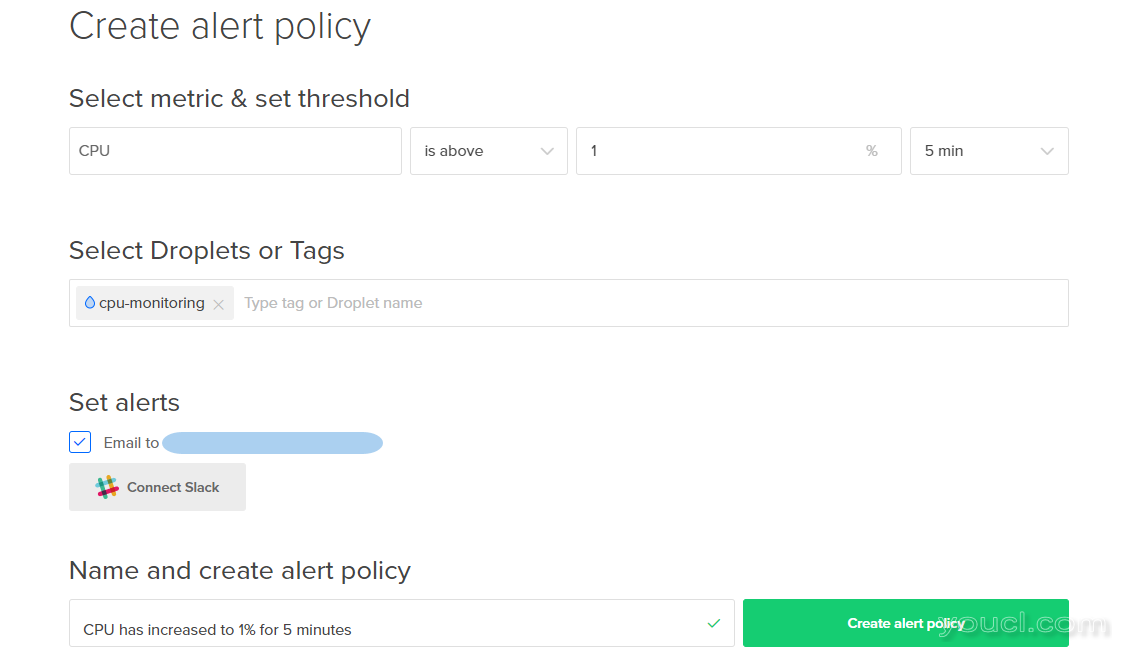
在大多数系统上,这个阈值很有可能是完全不合适的,但是通过调整持续时间并设置略高于当前平均负载的阈值,您可以在新代码或新服务对CPU利用率的影响方面早日学习。
监测紧急情况:CPU利用率高于90%
您可能还想设置一个远远高于平均水平的阈值,您认为是关键的阈值,并且需要及时调查。 例如,如果经历持续CPU使用50%的服务器,每隔五分钟一次,间隔时间会突然高达90%,您可能需要立即登录以调查情况。 同样,阈值特定于系统的工作负载。
结论
在本文中,我们探讨了uptime和top两个常见的Linux实用程序,以提供对Linux系统上CPU的了解,以及如何使用DigitalOcean Monitoring来查看Droplet上的历史CPU利用率并提醒您更改和紧急情况。
要了解有关DigitalOcean监控的更多信息,请参阅DigitalOcean监控简介
有关在标准,高内存和高CPU计划之间进行选择的指导,请参阅为应用程序选择正确的Droplet 。
如果您正在寻找更细致的监控服务,您可能需要了解更多关于使用Zabbix , Icinga和TICK等特定工具的信息 ,或查看DigitalOcean Monitoring教程的完整列表。







