介绍
DigitalOcean Monitoring通过改进的图形,可配置的警报策略和集成的通知,使管理员能够更深入地了解其基础架构的资源使用情况。 Droplet图提供了各种指标的当前和历史资源消耗的分钟可视化。 警报策略允许用户为特定的Droplet级资源配置阈值。 如果使用率超过这些阈值,则会发送电子邮件或松弛通知。
DigitalOcean监控系统旨在帮助用户及时响应资源枯竭,基础设施健康受到影响的关键情况。 然而,它也可以提供早期的洞察变化的使用模式,以协助规划和主动措施,以避免未来的问题。
在本指南中,我们将提供DigitalOcean监控的概述,并讨论如何帮助您更好地管理基础架构资源。
什么是DigitalOcean监控?
DigitalOcean Monitoring是一项免费的选择性服务,可以深入了解整个基础设施的资源使用情况。 监控由几个不同的组件组成,它们一起提高了服务器运行状况的可见性。
Droplet图是系统级度量的可视化表示,用于提供资源使用的高级概述。 这可以帮助您了解资源使用情况如何随着时间的推移而变化,不同的资源级别关联以及哪些流程对这些级别有所贡献。 通过阅读我们的“如何跟踪数字海水曲线曲线的性能”文章,您可以了解更多。
警报策略是用户创建的规则,用于定义资源消耗的阈值。 当用法超过阈值时,通过电子邮件或Slack调度通知。 我们的“如何通过DigitalOcean监控设置警报”文章提供了有关如何开始提醒的更多详细信息。
有关DigitalOcean监控的几点知识:
- 价格 :免费
- 区域支持 :在所有地区可用
- 要求 :DigitalOcean代理必须安装在所有参与的Droplet上
- Graphed指标 :系统和用户CPU使用情况,内存使用情况,磁盘读取,磁盘写入,磁盘使用情况,传入和传出公共带宽,传入和传出私有带宽,CPU和内存的顶级进程
- 具有警报功能的指标 :CPU,输入带宽,传出带宽,磁盘读取,磁盘写入,内存使用情况,磁盘使用情况
- 通知方式 :Email和Slack
什么时候应该使用警报策略和通知?
DigitalOcean监控是为了提高您对Droplet资源利用率的意识。 收集的指标和警报可以帮助您跟踪基础设施的运行状况。 换句话说,DigitalOcean Monitoring关心数据源,最好地表明您的服务器具有满足其当前工作负载的资源能力。
由于代理专注于系统级数据,因此不适用于应用程序性能监视(APM)任务,例如跟踪应用程序错误,网站连接或响应时间。 这些需要具有不同重点的监控系统,除了DigitalOcean监控之外,它也可以使用。
启用DigitalOcean代理
所有监控功能都需要一个小型的开放源码的DigitalOcean Agent程序来安装在参与的Droplet上。 代理收集相关指标并将其转发给DigitalOcean监控服务。 要详细了解代理收集的指标及其工作原理,请阅读我们的“如何安装和使用DigitalOcean Agent进行监控”指南 。
该代理目前支持Ubuntu 14.04及更高版本,Debian 8和CentOS 6及更高版本。 Fedora的“自动监视”复选框不可用,但可以使用安装脚本。
您可以通过选中“ 监视 ”框,选择“监视”并自动安装代理创建“ 滴滴 ”时:

如果在创建期间未选择“监视”,则可以通过登录到“Droplet”并键入以下内容来手动安装代理:
curl -sSL https://agent.digitalocean.com/install.sh | sh
选择加入后,您可以开始创建警报策略。
在DigitalOcean控制面板中创建警报策略
您可以随时通过单击DigitalOcean控制面板主导航中的监视链接 ,然后单击创建警报策略按钮来创建警报策略 :
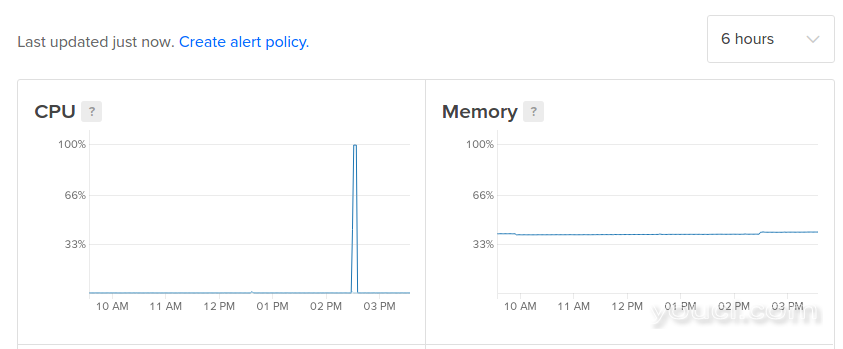
您还可以按照“滴液图”页面的链接:
您将进入“ 创建警报”策略页面,您可以在其中定义新的警报策略:
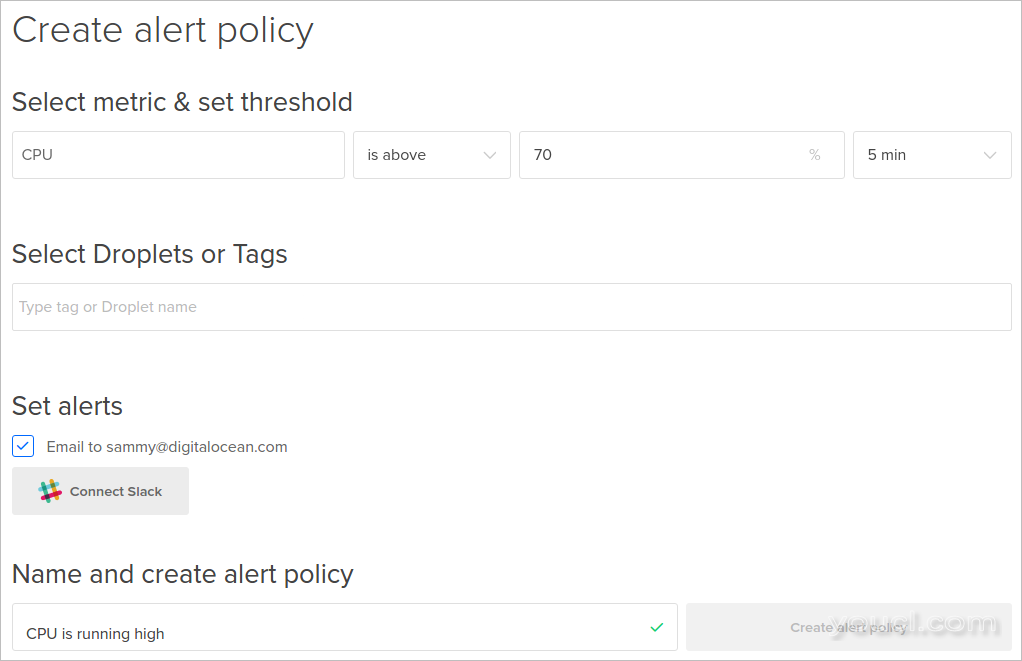
警报创建过程主要围绕四个主要决策:
- 设置度量和阈值
- 选择Droplet或标签
- 设置警报
- 命名警报策略
一旦您对选择感到满意,您将点击按钮创建警报。 让我们更详细地看看上面的每一个决定。
设置公制和阈值
用于定义警报策略的模式对于所有度量标准是相同的:
- 选择指标。 选项包括CPU,入站带宽,出站带宽,磁盘读取,磁盘写入,内存利用率和磁盘利用率。 有关这些度量的更多信息,请参阅监控词汇表 。
- 指示当使用量高于或低于阈值时是否要通知您。 以上的默认值通常是合适的。
- 将使用阈值本身指定为正在使用的总可用容量的百分比,或者根据所选指标的使用率。 这里的适当值将取决于度量,警报的目标和典型的服务器使用模式。
- 选择触发通知之前Droplet必须超过阈值的时间。 间隔时间包括5分钟,10分钟,30分钟,1小时,6小时和1天。
例如,如果磁盘利用率超过90%超过10分钟,我们可能会设置紧急警报以通知我们。 由于目前的能力几乎已经耗尽,这种警报将有助于立即通知员工采取紧急行动。
但是为了帮助进行容量规划,当磁盘利用率超过70%超过一天时,我们也可能会选择提醒您。 这将作为能力问题的早期指标,以便我们能够在紧急情况下计划增加更多的存储空间。 第二种类型的警报可能告诉我们,当我们星期一到达办公室时,我们应该考虑添加额外的存储空间(如果我们预计消费率在此之前不会超过剩余存储空间):

如果上述两个警报都已到位,如果使用率上升到90%以上,我们仍然会收到通知,如果我们的消费估计不正确,这将是有帮助的。
定义度量和阈值后,下一步是选择应用警报策略的滴滴。
将政策应用于Droplet
该策略可以通过名称或标签应用到Droplet。 当名称添加一个Droplet时,它将从警报策略页面进行管理。 这可以与较小的基础设施或特定于仅仅几滴水的政策一起工作。
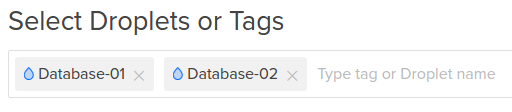
当通过标签添加Droplet时,只需要在警报策略表单上管理该标签。 之后,使用策略标签安装并分类的代理的任何Droplet将自动被监控。 使用标签应用警报策略在管理许多Droplet时可能会有所帮助,因为标签可以作为创建过程的一部分添加到Droplet中:
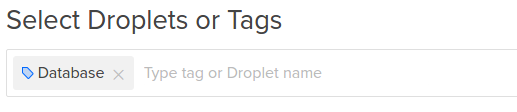
没有什么会阻止一个滴滴被添加到一个策略多次,通过名称和标签,例如。 当触发警报时,这不会导致该Droplet的多个通知。 对于每个Droplet,每个策略将发送一次警报,而不管Droplet可能有多少种方式符合该策略。
配置通知方法
要创建策略,您必须至少选择两种可能的通知方法之一:电子邮件或松弛。 默认检查的首选项是您在创建策略时使用的帐户的已验证电子邮件地址 。 目前,您无法添加或更改电子邮件地址。
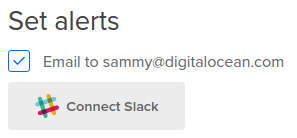
除电子邮件通知外, Slack用户可以连接到一个Slack团队,然后选择一个通道进行通知:
一旦您授权DigitalOcean Monitoring和Slack团队之间的链接,该连接将在下次创建警报策略时默认启用。 如果您选择在新的警报策略中取消关联,则可以选择不同的渠道或不同的团队,而不会影响以前的任何连接。
命名和创建警报策略
创建策略之前的最后一步是分配一个名称。 为每个指标提供默认主题行,但为了更容易地区分策略,我们建议您自定义名称。
您在“监视器名称”字段中输入的文本将:
- 在监控索引页面上标识策略

- 形成电子邮件警报主题行的一部分
Subject: DigitalOcean monitoring triggered: Disk Utilization is high on a server tagged 'Database'
配置完所有内容后,单击“ 创建警报”策略按钮将创建策略并启动对传入数据的评估。
新策略将显示在“监控”页面的“ 警报策略”下 :
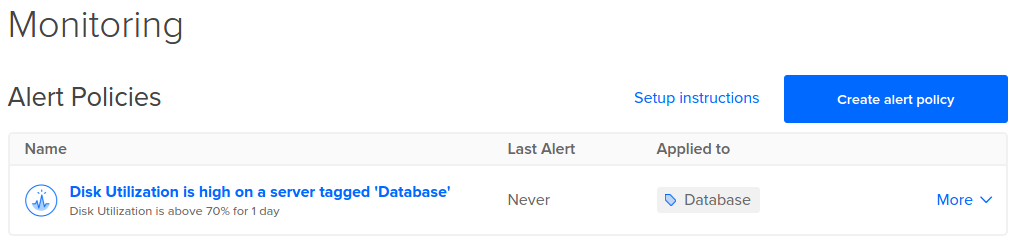
一旦有了警报策略,了解监控系统如何收集数据并评估警报状态非常重要。
数据点收集和警报状态
当策略首次创建时,可能需要几分钟的时间才能开始评估传入的数据。 之后,稍微延迟,将定期对数据进行评估。
如果警报间隔中的数据点的平均值超过阈值,则触发警报。 在我们的示例中,一旦监控开始,在1440分钟(一天)之后,监控将在该时间段内平均数据点,以确定磁盘使用的百分比。 如果平均值表示磁盘使用率高于70%,我们将收到通知。
使用相同的数据点评估过程来确定警报何时解决。 数据点将继续定期收集。 每次接收到新的度量标准时,最旧的点都将被关闭,最新的点被添加,并且评估阈值间隔的平均值。 这意味着如果几乎没有超出阈值,并且出现了新的数据点,使新的平均值低于阈值,则可以无延迟地触发解决通知。
使用我们的磁盘示例,假设日志轮换策略会删除旧的特别大的日志文件,导致阈值大幅下降。 我们将在收到警报通知的同一渠道收到解决通知(除非我们在过渡期间修改了该政策)。
此时,无法手动解析或确认警报。 根据警报策略,当资源使用回落到可接受的水平时,警报将自动解决。
接收通知并查看活动警报
当根据上述过程触发警报时,使用所选择的介质发送通知。 当触发警报时,每个配置的介质将通知一次。 当警报已经解决时,会发送第二个通知。
每个通知包括警报的名称,触发Droplet的名称和IP地址,以及控制面板中触发Droplet页面的链接。 此外,关于触发警报的通知包括警报策略参数和触发警报时的平均资源使用情况。 解决通知包括警报事件的长度和当前的平均资源使用量。
控制面板中的警报
如果触发警报,监控界面中的新部分将显示为触发警报 。 此部分仅在有活动警报时可见:
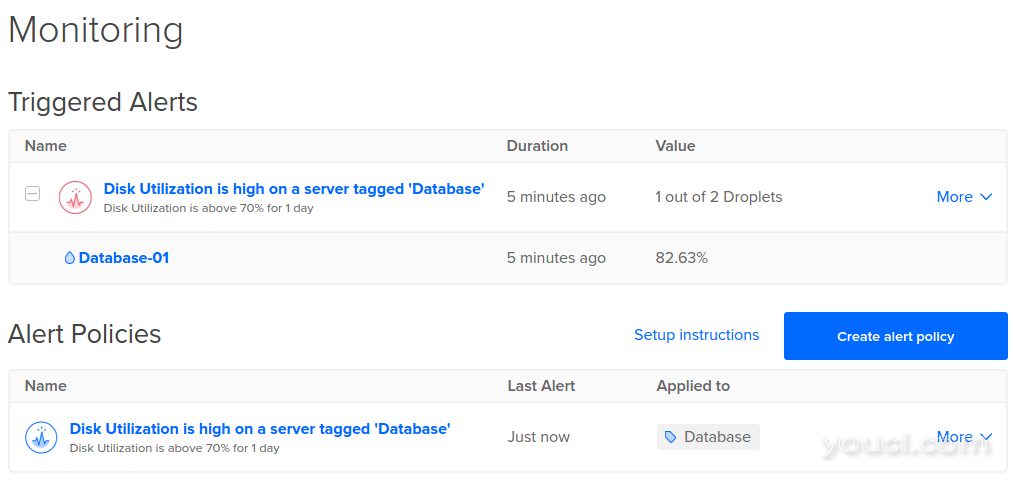
该页面的此部分显示活动警报,包括当前高于使用阈值的每个Droplet。 一旦警报已经解决,该条目将退出“ 触发警报”部分。 如果不再有任何活动警报, 触发警报部分将被隐藏。
电子邮件通知
如果您选择了电子邮件通知,系统会在触发警报时收到通知电子邮件:
Example Content Subject: DigitalOcean monitoring triggered: Disk Utilization is high on a server tagged 'Database'
Disk Utilization is currently at 82.63%, above threshold of 70.00% for more than 1 day.
View droplet Database-01: https://cloud.digitalocean.com/droplets/12345678
IP: 203.0.113.1
警报一经解决,将发送类似的解决方案电子邮件 :
Example ContentSubject: DigitalOcean monitoring resolved: Disk Utilization is high on a server tagged 'Database'
The monitor was triggered for more than 1 day.
Disk Utilization is currently at 69.70%.
View droplet Database-01: https://cloud.digitalocean.com/droplets/12345678
IP: 203.0.113.1
这表示警报已经解决。
松弛通知
如果您已经启用了“松弛”通知,您将在“警报”策略中选择的团队和频道中收到一个Slack通知:
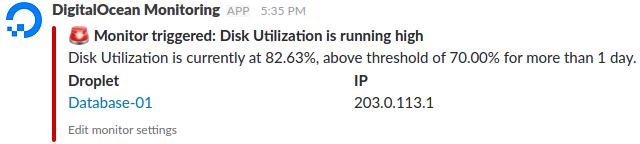
一旦平均资源消耗量再次下降到阈值以下,将发送类似的Slack通知,指示警报已经解决:

同样,此消息表示警报已解决。
结论
DigitalOcean监控提供有关您的基础设施健康状况的最新信息,以便及时,数据驱动的决策。 Droplet图形可以帮助您了解使用习惯模式随着时间的推移而发展的历史,同时,警报策略和通知可让您了解使用情况如何超出您可以接受的参数。
要了解有关DigitalOcean监控的更多信息,请查看以下指南:







