介绍
TICK是来自时间序列数据库 InfluxDB的开发人员的产品的 集合 。它由以下组件组成:- T elegraf从各种来源收集时间序列数据。
- nfluxDB存储时间序列数据。
- C hronograf可视化和图形化时间序列数据。
- K apacitor提供警报并检测时间序列数据中的异常。
先决条件
开始之前,您需要具备以下条件:- 一个Ubuntu 16.04服务器通过遵循Ubuntu 16.04初始服务器设置指南设置 ,包括sudo非root用户和防火墙。
- 用于发送警报的SMTP服务器,以及连接详细信息。 如果你没有一个,你可以安装
sendmail与sudo apt-get install sendmail。 - 如果您希望按照第7步中所述保护Chronograf用户界面,您需要一个GitHub组织的GitHub帐户。 按照本教程创建一个GitHub组织。
第1步 - 添加TICK存储库
默认情况下,TICK组件不能通过程序包管理器使用。所有TICK组件都使用相同的存储库,因此我们将设置存储库配置文件以使安装无缝。 使用以下命令添加InfluxData存储库:curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
sudo apt-get update
第2步 - 安装InfluxDB并配置身份验证
InfluxDB是一个开源数据库,优化了快速,高可用性存储和检索时间序列数据。 InfluxDB非常适合运行监控,应用程序度量和实时分析。 运行以下命令安装InfluxDB:sudo apt-get install influxdb
sudo systemctl start influxdb
systemctl status influxdb
[secondary_label Output
● influxdb.service - InfluxDB is an open-source, distributed, time series database
Loaded: loaded (/lib/systemd/system/influxdb.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2017-03-13 15:20:53 CST; 11s ago
Docs: https://docs.influxdata.com/influxdb/
Main PID: 1619 (influxd)
CGroup: /system.slice/influxdb.service
└─1619 /usr/bin/influxd -config /etc/influxdb/influxdb.conf
influx
sammy_admin创建一个
sammy用户,但您可以使用任何您想要的。
CREATE USER "sammy" WITH PASSWORD 'sammy_admin' WITH ALL PRIVILEGES
show users
Output user admin
---- -----
sammy true
exit
/etc/influxdb/influxdb.conf 。这是InfluxDB的配置文件。
sudo nano /etc/influxdb/influxdb.conf
[http]部分,取消注释
auth-enabled选项,并将其值设置为
true :
/etc/influxdb/influxdb.conf
...
[http]
# Determines whether HTTP endpoint is enabled.
# enabled = true
# The bind address used by the HTTP service.
# bind-address = ":8086"
# Determines whether HTTP authentication is enabled.
auth-enabled = true
...
sudo systemctl restart influxdb
第3步 - 安装和配置Telegraf
Telegraf是一个开源代理,可以收集运行系统或其他服务的指标和数据。 Telegraf然后将数据写入InfluxDB或其他输出。 运行以下命令安装Telegraf:sudo apt-get install telegraf
sudo nano /etc/telegraf/telegraf.conf
[outputs.influxdb]部分并提供用户名和密码:
/etc/telegraf/telegraf.conf
[[outputs.influxdb]]
## The full HTTP or UDP endpoint URL for your InfluxDB instance.
## Multiple urls can be specified as part of the same cluster,
## this means that only ONE of the urls will be written to each interval.
# urls = ["udp://localhost:8089"] # UDP endpoint example
urls = ["http://localhost:8086"] # required
## The target database for metrics (telegraf will create it if not exists).
database = "telegraf" # required
...
## Write timeout (for the InfluxDB client), formatted as a string.
## If not provided, will default to 5s. 0s means no timeout (not recommended).
timeout = "5s"
username = "sammy"
password = "sammy_admin"
## Set the user agent for HTTP POSTs (can be useful for log differentiation)
# user_agent = "telegraf"
## Set UDP payload size, defaults to InfluxDB UDP Client default (512 bytes)
# udp_payload = 512
sudo systemctl restart telegraf
systemctl status telegraf
Output● telegraf.service - The plugin-driven server agent for reporting metrics into InfluxDB
Loaded: loaded (/lib/systemd/system/telegraf.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2017-03-14 15:24:41 CST; 1min 26s ago
Docs: https://github.com/influxdata/telegraf
Main PID: 1752 (telegraf)
CGroup: /system.slice/telegraf.service
└─1752 /usr/bin/telegraf -config /etc/telegraf/telegraf.conf -config-directory /etc/telegraf/telegraf.d
influx -username 'sammy' -password 'sammy_admin'
show databases
telegraf数据库:
Output name: databases
name
----
_internal
telegraf
telegraf数据库,请检查您配置的Telegraf设置,以确保您指定了正确的用户名和密码。 让我们看看Telegraf在那个数据库中存储什么。执行以下命令切换到Telegraf数据库:
use telegraf
show measurements
Output name: measurements
name
----
cpu
disk
diskio
kernel
mem
processes
swap
system
- Apache
- Cassandra
- Docker
- Elasticsearch
- Graylog
- IPtables
- MySQL
- PostgreSQL
- Redis
- SNMP
- 和许多其他
telegraf -usage plugin-name ,可以查看每个输入插件的使用说明。 退出InfluxDB控制台:
exit
第4步 - 安装Kapacitor
Kapacitor是一个数据处理引擎。它允许您插入自己的自定义逻辑,以使用动态阈值处理警报,匹配模式的度量或识别统计异常。我们将使用Kapacitor从InfluxDB读取数据,生成警报,并将这些警报发送到指定的电子邮件地址。 运行以下命令安装Kapacitor:sudo apt-get install kapacitor
sudo nano /etc/kapacitor/kapacitor.conf
[[influxdb]]部分,并提供用于连接到InfluxDB数据库的用户名和密码:
/etc/kapacitor/kapacitor.conf
# Multiple InfluxDB configurations can be defined.
# Exactly one must be marked as the default.
# Each one will be given a name and can be referenced in batch queries and InfluxDBOut nodes.
[[influxdb]]
# Connect to an InfluxDB cluster
# Kapacitor can subscribe, query and write to this cluster.
# Using InfluxDB is not required and can be disabled.
enabled = true
default = true
name = "localhost"
urls = ["http://localhost:8086"]
username = "sammy"
password = "sammy_admin"
...
sudo systemctl start kapacitor
kapacitor list tasks
Output ID Type Status Executing Databases and Retention Policies
第5步 - 安装和配置Chronograf
Chronograf是一个图形和可视化应用程序,它提供了可视化监控数据和创建警报和自动化规则的工具。它包括对模板的支持,并且具有用于公共数据集的智能预配置仪表板库。我们将配置它连接到我们已经安装的其他组件。 下载并安装最新的软件包:wget https://dl.influxdata.com/chronograf/releases/chronograf_1.2.0~beta5_amd64.deb
sudo dpkg -i chronograf_1.2.0~beta5_amd64.deb
sudo systemctl start chronograf
8888 :
sudo ufw allow 8888/tcp
http:// your_server_ip :8888访问Chronograf界面。 您将看到一个欢迎页面,如下图所示:
 输入InfluxDB数据库的用户名和密码,然后单击“
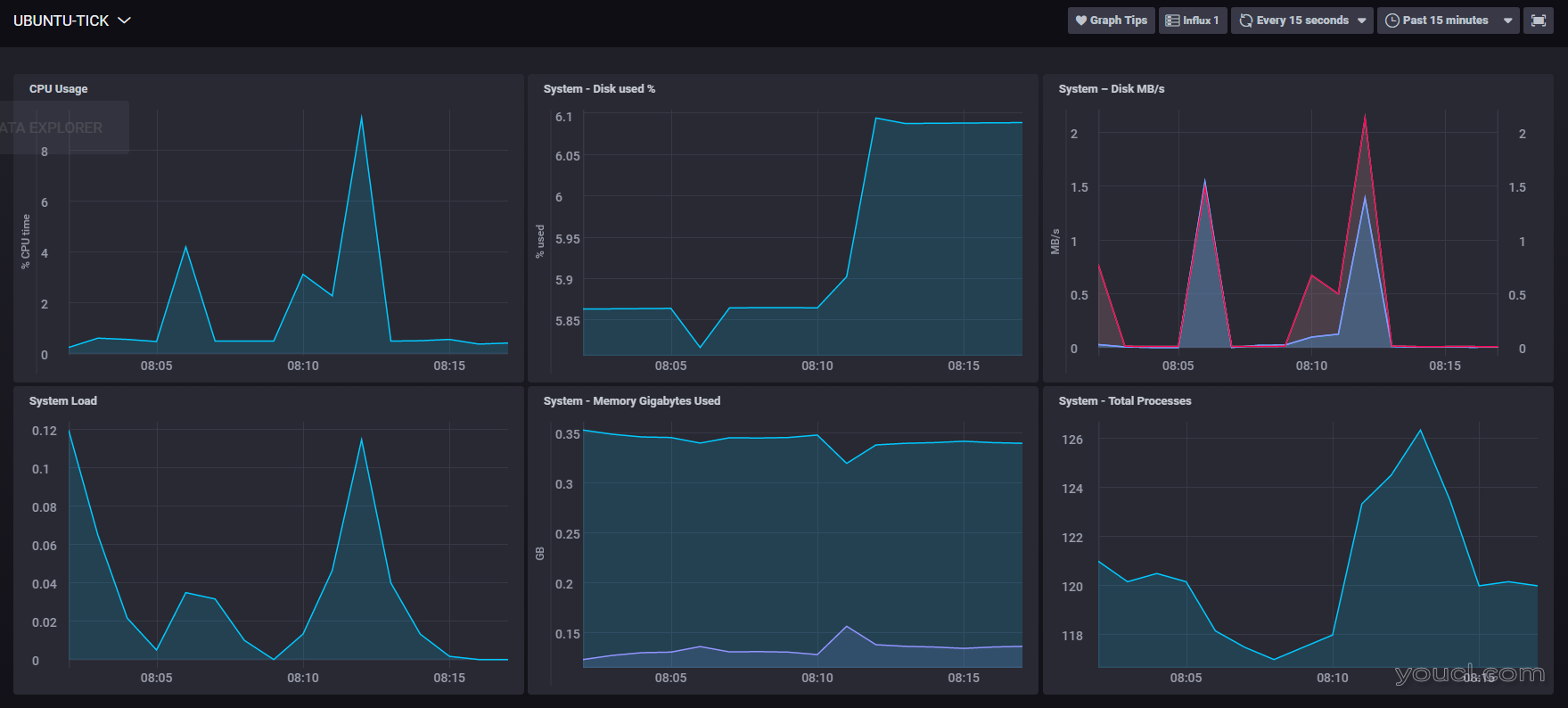
连接新源”以继续。 连接后,您将看到主机列表。单击服务器的主机名以打开一个仪表板,其中包含有关主机的一系列系统级图表,如下图所示:
输入InfluxDB数据库的用户名和密码,然后单击“
连接新源”以继续。 连接后,您将看到主机列表。单击服务器的主机名以打开一个仪表板,其中包含有关主机的一系列系统级图表,如下图所示:
 现在让我们将Chronograf连接到Kapacitor以设置警报。将鼠标悬停在左侧导航菜单中的齿轮图标上,然后点击
Kapacitor打开配置页。
现在让我们将Chronograf连接到Kapacitor以设置警报。将鼠标悬停在左侧导航菜单中的齿轮图标上,然后点击
Kapacitor打开配置页。
 使用默认连接详细信息;我们没有为Kapacitor配置用户名和密码。单击
连接Kapacitor 。 一旦Kapacitor成功连接,您将在表单下方看到“
配置警报端点”部分。 Kapacitor支持多个警报终点:
使用默认连接详细信息;我们没有为Kapacitor配置用户名和密码。单击
连接Kapacitor 。 一旦Kapacitor成功连接,您将在表单下方看到“
配置警报端点”部分。 Kapacitor支持多个警报终点:
- HipChat
- OpsGenie
- PagerDuty
- Sensu
- 松弛
- SMTP
- 谈论
- 电报
- 维多利亚
sendmail ,将它们保留为默认值。 然后单击
保存 。 配置就绪后,让我们创建一些警报。
第6步 - 配置警报
让我们设置一个简单的警报,寻找高CPU使用率。 将鼠标悬停在左侧导航菜单中的惊叹号图标上,然后单击“ Kapacitor规则” 。 然后单击 创建新规则 。 在第一部分中,单击 telegraf.autogen选择时间序列。 然后从显示的列表中选择 系统 。 然后选择 load1 。您将在下面的部分中立即看到相应的图表。 在图表上方,找到 Load1大于的值为“ 发送警报”的字段,并为该值输入0.8 。 然后将以下文本粘贴到“
警报消息”字段中以配置警报消息的文本:
{{ .ID }} is {{ .Level }} value: {{ index .Fields "value" }}
示例消息
{
"Name":"system",
"TaskName":"chronograf-v1-50c67090-d74d-42ba-a47e-45ba7268619f",
"Group":"nil",
"Tags":{
"host":"centos-tick"
},
"ID":"TEST:nil",
"Fields":{
"value":1.25
},
"Level":"CRITICAL",
"Time":"2017-03-08T12:09:30Z",
"Message":"TEST:nil is CRITICAL value: 1.25"
}
dd命令从
/dev/zero读取数据并将其发送到
/dev/null ,以创建CPU尖峰:
dd if=/dev/zero of=/dev/null
CTRL+C停止命令。 过一会儿,您将收到一封电子邮件。此外,您还可以通过单击Chronograf用户界面左侧导航菜单中的
警报历史记录来查看所有警报。
注意 :确认您可以接收快讯后,请务必停止使用CTRL+C启动的dd命令。 我们有警报运行,但任何人都可以登录Chronograf。让我们限制访问。
第7步 - 使用OAuth保护Chronograf
默认情况下,任何知道运行Chronograf应用程序的服务器地址的人都可以查看任何数据。它可以接受测试环境,但不是生产。 Chronograf支持Google,Heroku和GitHub的OAuth身份验证。我们将通过 GitHub帐户配置登录,因此您需要一个登录才能继续。 首先,用GitHub注册一个新的应用程序。登录您的GitHub帐户,然后导航到 https://github.com/settings/applications/new 。 然后填写以下详细信息的表单:- 使用Chronograf填充应用程序名称或合适的描述性名称。
- 对于首页网址 ,请使用
http:// your_server_ip :8888。 - 使用
http:// your_server_ip :8888/oauth/github/callback填写授权回调网址 。 - 单击注册应用程序以保存设置。
- 复制下一个屏幕上提供的客户端ID和客户端密钥值。
/lib/systemd/system/chronograf.service :
sudo nano /lib/systemd/system/chronograf.service
[Service]部分,并编辑以
ExecStart=开头的行:
/lib/systemd/system/chronograf.service
[Service]
User=chronograf
Group=chronograf
ExecStart=/usr/bin/chronograf --host 0.0.0.0 --port 8888 -b /var/lib/chronograf/chronograf-v1.db -c /usr/share/chronograf/canned -t 'secret_token' -i 'your_github_client_id' -s 'your_github_client_secret' -o 'your_github_organization'
KillMode=control-group
Restart=on-failure
sudo systemctl daemon-reload
sudo systemctl restart chronograf
http:// your_server_ip :8888以访问Chronograf界面。 这次你将看到一个
用Github登录按钮。单击按钮登录,系统会要求您允许应用程序访问您的Github帐户。一旦您允许访问,您就会登录。







