介绍
时间序列分析属于统计学的一个分支,涉及有序的,经常是时间的数据的研究。当相关应用时,时间序列分析可以显示意想不到的趋势,提取有用的统计,甚至预测未来的趋势。由于这些原因,它被应用于许多领域,包括经济,天气预报和能力规划等等。 在本教程中,我们将介绍时间序列分析中使用的一些常用技术,并逐步介绍操作,可视化时间序列数据所需的迭代步骤。
先决条件
本指南将介绍如何在本地桌面或远程服务器上进行时间序列分析。使用大型数据集可能需要大量内存,因此在任一情况下,计算机将需要至少
2GB的内存来执行本指南中的一些计算。 在本教程中,我们将使用
Jupyter Notebook来处理数据。 如果你还没有,你应该按照我们的
教程安装和设置Jupyter Notebook for Python 3 。
第1步 - 安装软件包
我们将利用
statsmodels库,它在处理数据时提供了很大的灵活性,而
statsmodels库允许我们在Python中执行统计计算。这两个库一起使用,扩展了Python以提供更多的功能,并显着增加我们的分析工具包。 像其他Python包一样,我们可以用
pip安装
statsmodels和
statsmodels 。首先,让我们进入我们的本地编程环境或基于服务器的编程环境:
cd environments
. my_env/bin/activate
从这里,让我们为我们的项目创建一个新的目录。我们将调用它的时间
timeseries ,然后移动到目录。 如果调用该项目不同的名称,请务必在整个指南中用您的名称
timeseries序列
mkdir timeseries
cd timeseries
我们现在可以安装
statsmodels ,
statsmodels和数据绘图软件包
matplotlib 。它们的依赖也将被安装:
pip install pandas statsmodels matplotlib
在这一点上,我们现在设置开始使用
pandas和
statsmodels 。
第2步 - 加载时间序列数据
要开始使用我们的数据,我们将启动Jupyter Notebook:
jupyter notebook
要创建新的笔记本文件,请从右上角的下拉菜单中选择
新建 >
Python 3 :
 这将打开一个笔记本,允许我们加载所需的库(注意用于引用pandas,
这将打开一个笔记本,允许我们加载所需的库(注意用于引用pandas,
matplotlib和
statsmodels的标准
statsmodels )。在我们的笔记本顶部,我们应该写下面的内容:
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
在本教程中的每个代码块之后,您应该键入
ALT + ENTER运行代码并移动到笔记本中的新代码块。 方便地,
statsmodels带有内置数据集,因此我们可以将时间序列数据集直接加载到内存中。 我们将使用一个名为“来自美国夏威夷Mauna Loa天文台的连续空气样本的大气CO2”的数据集,其中收集了1958年3月至2001年12月的CO2样本。我们可以引入这些数据:
data = sm.datasets.co2.load_pandas()
co2 = data.data
让我们检查我们的时间序列数据的前5行是什么样子:
print(co2.head(5))
Output co2
1958-03-29 316.1
1958-04-05 317.3
1958-04-12 317.6
1958-04-19 317.5
1958-04-26 316.4
随着我们的包导入和CO2数据集准备好,我们可以继续索引我们的数据。
第3步 - 使用时间序列数据建立索引
您可能已经注意到,日期已设置为我们的
pandas DataFrame的索引。当在Python中使用时间序列数据时,我们应该确保使用日期作为索引,所以请务必检查,我们可以通过运行以下命令:
co2.index
OutputDatetimeIndex(['1958-03-29', '1958-04-05', '1958-04-12', '1958-04-19',
'1958-04-26', '1958-05-03', '1958-05-10', '1958-05-17',
'1958-05-24', '1958-05-31',
...
'2001-10-27', '2001-11-03', '2001-11-10', '2001-11-17',
'2001-11-24', '2001-12-01', '2001-12-08', '2001-12-15',
'2001-12-22', '2001-12-29'],
dtype='datetime64[ns]', length=2284, freq='W-SAT')
dtype=datetime[ns]字段确认我们的索引由日期戳对象组成,而
length=2284和
freq='W-SAT'告诉我们,我们有从周六开始的2,284周的日期戳。 每周的数据可能很难处理,所以让我们使用我们的时间序列的月平均值。这可以通过使用方便的
resample函数来获得,这允许我们将时间序列分组为桶(1个月),对每个组应用函数(平均值),并组合结果(每个组一行)。
y = co2['co2'].resample('MS').mean()
这里,术语
MS意味着我们以桶为单位对数据进行分组,并确保我们使用每个月的开始作为时间戳:
y.head(5)
Output1958-03-01 316.100
1958-04-01 317.200
1958-05-01 317.120
1958-06-01 315.800
1958-07-01 315.625
Freq: MS, Name: co2, dtype: float64
pandas的一个有趣的特点是它能够处理日期戳索引,这使我们能够快速分割我们的数据。例如,我们可以将数据集切分为仅检索
1990后的数据点:
y['1990':]
Output1990-01-01 353.650
1990-02-01 354.650
...
2001-11-01 369.375
2001-12-01 371.020
Freq: MS, Name: co2, dtype: float64
或者,我们可以将我们的数据集分割为仅在
1995 10月到
1996 10月
1995检索数据点:
y['1995-10-01':'1996-10-01']
Output1995-10-01 357.850
1995-11-01 359.475
1995-12-01 360.700
1996-01-01 362.025
1996-02-01 363.175
1996-03-01 364.060
1996-04-01 364.700
1996-05-01 365.325
1996-06-01 364.880
1996-07-01 363.475
1996-08-01 361.320
1996-09-01 359.400
1996-10-01 359.625
Freq: MS, Name: co2, dtype: float64
使用我们的数据正确索引处理时间数据,我们可以移动到可能缺少的处理值。
第4步 - 处理时间序列数据中的缺失值
现实世界的数据往往是凌乱的。从图中我们可以看出,时间序列数据包含缺失值并不罕见。检查这些的最简单的方法是直接绘制数据或使用下面的命令,将显示丢失的数据输出:
y.isnull().sum()
Output5
此输出告诉我们,在我们的时间序列中有5个月缺少值。 一般来说,如果它们不是太多,我们应该“填充”缺失值,以便我们在数据中没有间隙。我们可以使用
fillna()命令在
fillna()中做到这一点。为了简单起见,我们可以使用我们的时间序列中最接近的非空值填充缺失值,但重要的是要注意滚动平均值有时会更好。
y = y.fillna(y.bfill())
在填充缺失值的情况下,我们可以再次检查是否存在任何空值,以确保我们的操作有效:
y.isnull().sum()
Output0
在执行这些操作后,我们看到我们已经成功地填充了我们的时间序列中的所有缺失值。
第5步 - 可视化时间序列数据
当处理时间序列数据时,可以通过可视化来显示很多。要注意的几件事:
- 季节性 : 数据是否显示清晰的周期性模式?
- 趋势 : 数据是否遵循一致的向上或向下斜率?
- 噪声 : 是否有任何异常点或缺失值与其他数据不一致?
我们可以使用
matplotlib API周围的
matplotlib包装来显示我们的数据集的图:
y.plot(figsize=(15, 6))
plt.show()
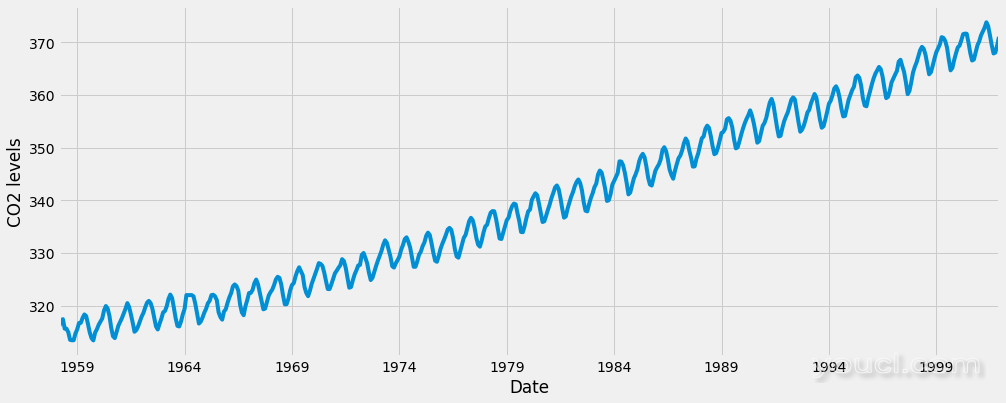 当我们绘制数据时,出现一些可区分的模式。时间序列具有明显的季节性模式,以及总体增长趋势。我们还可以使用称为时间序列分解的方法可视化我们的数据。顾名思义,时间序列分解使我们将时间序列分解为三个不同的组成部分:趋势,季节性和噪声。 幸运的是,
当我们绘制数据时,出现一些可区分的模式。时间序列具有明显的季节性模式,以及总体增长趋势。我们还可以使用称为时间序列分解的方法可视化我们的数据。顾名思义,时间序列分解使我们将时间序列分解为三个不同的组成部分:趋势,季节性和噪声。 幸运的是,
statsmodels提供了方便的季节性分解功能来执行季节性分解开箱即用。 如果您有兴趣了解更多,其原始实现的参考可以在以下文章“
STL:A Seasonal-Trend Decomposition Procedure Based on Loess ”中
找到 。 下面的脚本显示了如何在Python中执行时间序列季节性分解。默认情况下,
seasonal_decompose返回一个相对较小的数字,所以这段代码块的前两行确保输出数据足够大以供我们可视化。
from pylab import rcParams
rcParams['figure.figsize'] = 11, 9
decomposition = sm.tsa.seasonal_decompose(y, model='additive')
fig = decomposition.plot()
plt.show()
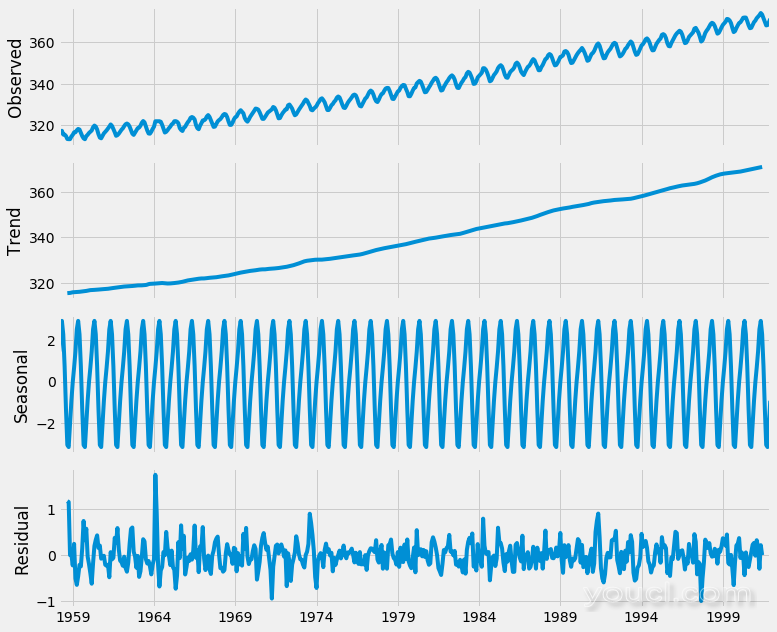 使用时间序列分解使得更容易快速识别数据中的变化平均值或变化。上图清楚地显示了我们的数据的上升趋势,以及其每年的季节性。这些可以用来理解我们的时间序列的结构。时间序列分解背后的直觉很重要,因为许多预测方法基于结构化分解的这一概念来产生预测。
使用时间序列分解使得更容易快速识别数据中的变化平均值或变化。上图清楚地显示了我们的数据的上升趋势,以及其每年的季节性。这些可以用来理解我们的时间序列的结构。时间序列分解背后的直觉很重要,因为许多预测方法基于结构化分解的这一概念来产生预测。
结论
如果您遵循本指南,现在您已经掌握了在Python中可视化和操作时间序列数据的经验。 要进一步提高您的技能集,您可以加载另一个数据集,并重复本教程中的所有步骤。例如,您可能希望使用
statsmodels库读取CSV文件,或者使用预先装入
statsmodels库的
statsmodels数据集:
data = sm.datasets.sunspots.load_pandas().data 。







