介绍
文本数据以许多不同的形式存在,从新闻到社交媒体到电子邮件。 当我们分析和可视化文本数据时,我们可以揭示可以改变我们解释文本的方式的一般趋势。
在本教程中,我们将探索在文本语料库中绘制字频率。 我们将要创建的程序将搜索一个纯文本文档,并按照其频率组织每个唯一字。 然后我们将使用matplotlib我们找到的数据。
先决条件
要能够使用本教程,请确保您具有以下先决条件:
最后,确保你遵循第1步 - 导入matplotlib我们的如何绘制数据在Python 3使用matplotlib ,因为它是必要的为这个项目安装matplotlib 。
第1步 - 设置程序文件
现在我们已经在我们的计算机上安装了matplotlib ,我们可以开始创建我们的项目。
使用您选择的文本编辑器,创建一个新的Python文件并将其word_freq.py 。 这将是我们的主要文件。
在这个程序中,我们将导入 matplotlib和我们需要的类(它是pyplot ),并传递它的plt 别名 。 这本质上将plt声明为将在我们的脚本中使用的全局变量。
import matplotlib.pyplot as plt
接下来,我们将在Python中导入一些默认包。 这些将用于设置和接收命令行输入。 要注意的重要包是argparse 。 这是我们将使用从命令行获取信息,并包括用户的帮助文本。
让我们在Python中导入以下默认包:
import matplotlib.pyplot as plt
import sys
import operator
import argparse
最后,创建标准的main方法和调用。 在main方法中,我们将编写大部分代码。
import matplotlib.pyplot as plt
import sys
import operator
import argparse
def main():
if __name__ == "__main__":
main()
现在我们已经导入了所有内容并为我们的项目设置了框架,我们可以继续使用我们导入的包。
第2步 - 设置参数解析器
对于这一部分,我们将创建命令行参数并将它们存储在变量中以便快速访问。
在我们的主要方法中,让我们创建我们的解析器变量并将其分配给默认的构造argparse提供。 然后我们将为文件中要查找的单词分配期望的参数。 最后,我们将为包含该单词的文件分配期望的参数。这将是一个.txt文件。
...
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"word",
help="the word to be searched for in the text file."
)
parser.add_argument(
"filename",
help="the path to the text file to be searched through"
)
if __name__ == "__main__":
main()
现在,方法中的第一个参数是我们期望在命令行中的标题。 第二个参数help= "..."用于向用户提供关于命令行参数应该是什么的一些信息。
接下来,我们将给定的参数保存到另一个我们称为args变量。
...
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"word",
help="the word to be searched for in the text file."
)
parser.add_argument(
"filename",
help="the path to the text file to be searched through"
)
args = parser.parse_args()
if __name__ == "__main__":
main()
为了良好的测量,我们应该总是检查我们的输入,以防在命令行参数中有打字错误。 这也是为了防止我们的脚本突然崩溃。 因此,我们通过使用try语句来处理错误。
...
def main():
...
args = parser.parser_args()
try:
open(args.filename)
except FileNotFoundError:
sys.stderr.write("Error: " + args.filename + " does not exist!")
sys.exit(1)
if __name__ == "__main__":
main()
我们使用sys.exit(1)向用户指示代码有问题,无法成功完成。
我们的项目现在将能够接受命令行参数。 下一步是解析我们的输入文件。
第3步 - 解析文件
在这一步中,我们将接收一个文件,读取每个单词,记录它们出现的频率,并将其保存为字典数据类型。
让我们创建一个名为word_freq()的函数,它接受两个命令行参数(单词和文件名),然后在main()调用该函数。
...
def main():
...
word_freq(args.word, args.filename)
def word_freq(word, filename):
if __name__ == "__main__":
main()
解析文件的第一步是创建一个字典数据类型,我们将调用doc 。 这将保存文件中找到的每个词,并跟踪它已经出现了多少次。
...
def word_freq( word, filename ):
doc = {}
if __name__ == "__main__":
main()
下一步是遍历给定的文件。 这是使用嵌套for循环 。
第一个for循环被设计为打开文件,并从它的第一行。 然后它需要每行中的内容,并根据字之间的空格字符串将其分割,同时将字存储到数组中。
第二个for循环接受这个数组,并循环检查它是否在字典中。 如果是,我们添加一个计数。 如果不是,则我们创建一个新条目并将其初始化为1。
...
def word_freq(word, filename):
doc = {}
for line in open(filename):
split = line.split(' ')
for entry in split:
if (doc.__contains__(entry)):
doc[entry] = int(doc.get(entry)) + 1
else:
doc[entry] = 1
if __name__ == "__main__":
main()
现在我们已经完成了项目的一半。
总结一下, our main()方法应该设置我们的命令行输入,并将它们传递给word_freq()函数。 word_freq()应该word_freq()获取字和文件名,并保存文本文件中找到的每个唯一字。
接下来,我们将获取这些数据并将其组织在图形中使用。
第4步 - 存储和排序数据
在我们制作图之前,我们必须确保这个词实际上是在我们打开的文件中。 我们可以使用if 条件语句来做到这一点 。
...
def word_freq(word, filename):
...
else:
doc[entry] = 1
if (not word in doc):
sys.stderr.write("Error: " + word + " does not appear in " + filename)
sys.exit(1)
if __name__ == "__main__":
main()
现在我们知道这个词是在文件中,我们可以开始为图形设置数据。
首先,我们必须从我们的字典数据类型排序,从最高到最低出现次数,并初始化变量供以后使用。 我们必须对我们的字典进行排序,以便在图形上适当地可视化。
...
def word_freq(word, filename):
...
if (not word in doc):
sys.stderr.write("Error: " + word + " does not appear in " + filename)
sys.exit(1)
sorted_doc = (sorted(doc.items(), key = operator.itemgetter(1)))[::-1]
just_the_occur = []
just_the_rank = []
word_rank = 0
word_frequency = 0
if __name__ == "__main__":
main()
要注意的两个变量是just_the_occur ,它是将保存单词出现的次数的数据。 另一个变量是just_the_rank ,它是一个变量,它将保存有关单词排名的数据。
现在我们有了排序的字典,我们将循环遍历它,找到我们的单词和它的排名,以及用这些数据填充我们的图。
...
def word_freq( word, filename ):
...
sortedDoc = (sorted(doc.items(), key = operator.itemgetter(1)))[::-1]
just_the_occur = []
just_the_rank = []
word_rank = 0
word_frequency = 0
entry_num = 1
for entry in sorted_doc:
if (entry[0] == word):
word_rank = entryNum
word_frequency = entry[1]
just_the_rank.append(entry_num)
entry_num += 1
just_the_occur.append(entry[1])
if __name__ == "__main__":
main()
这里我们必须确保两个变量just_the_occur和just_the_rank是相同的长度,否则matplotlib不会让我们创建图。
我们还在循环中添加了一个if语句来找到我们的单词(我们已经知道的),并提取它的排名和频率。
现在我们拥有创建图形所需的一切。 我们的下一步是最终创建它。
第5步 - 创建图形
在这一点上,我们可以插入我们在开始创建的plt变量。 要创建我们的图,我们需要一个标题,y轴标签,x轴标签,比例和图形类型。
在我们的例子中,我们将创建一个日志基础10图形来组织我们的数据。 标题和轴标签可以是任何你想要的,但更多的描述性,将是更好的人将看到你的图表。
...
def word_freq( word, filename ):
...
just_the_rank.append(entry_num)
entry_num += 1
just_the_occur.append(entry[1])
plt.title("Word Frequencies in " + filename)
plt.ylabel("Total Number of Occurrences")
plt.xlabel("Rank of word(\"" + word + "\" is rank " + str(word_rank) + ")")
plt.loglog(
just_the_rank,
just_the_occur,
basex=10
)
plt.scatter(
[word_rank],
[word_frequency],
color="orange",
marker="*",
s=100,
label=word
)
plt.show()
if __name__ == "__main__":
main()
标题, plt.ylabel()和plt.xlabel()函数是每个轴的标签。
plt.loglog()函数just_the_occur为x和y轴分别使用just_the_rank和just_the_occur。
我们更改日志基数并将其设置为10。
然后,我们设置散点图并突出显示我们的点。 我们做了一个橙色的星星,大小100,所以它的发音。 最后,我们用我们的话标记它。
一旦一切都完成了我们的图,我们告诉它与plt.show() 。
现在我们的代码终于完成了,我们可以测试运行它。
第6步 - 运行程序
对于我们的文本示例,我们需要一个文本文件来阅读,所以让我们从Project Gutenberg下载一个,该项目是一个志愿者项目,向读者提供免费电子书(大部分是在公共领域)。
让我们将Charles Dickens的小说“两城故事”的文本保存为名为cities.txt的文件, cities.txt curl保存到我们当前保存Python脚本的目录中:
curl http://www.gutenberg.org/files/98/98-0.txt --output cities.txt
接下来,让我们运行我们的代码传递我们选择的单词的参数(我们将使用“鱼”)和文本文件的名称:
python word_freq.py fish cities.txt
如果一切正常工作,你应该看到:
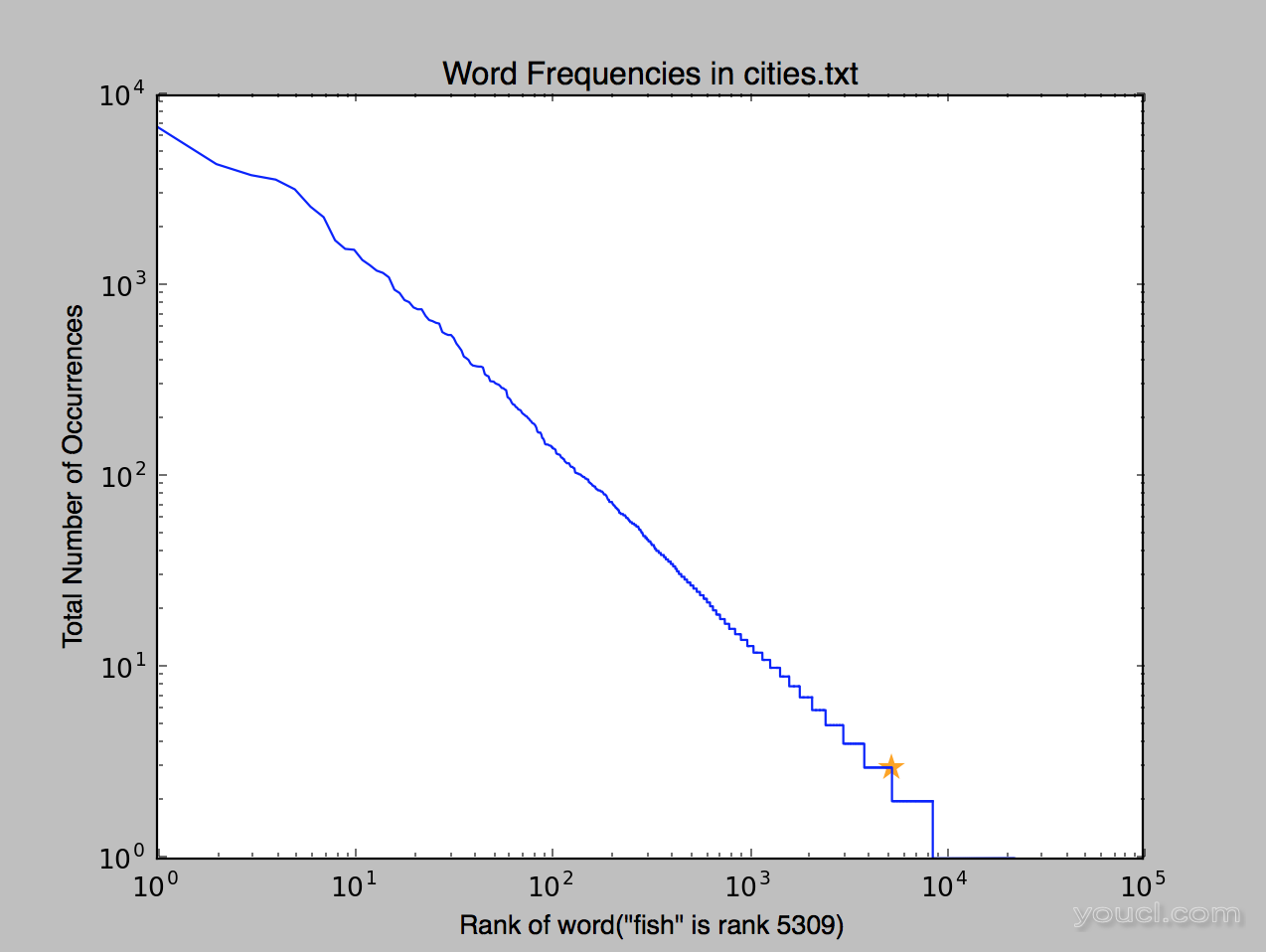
我们看到单词“fish”的排名是5309,并且出现的可视化。
现在,您可以继续尝试不同的单词和不同的文本文件。 您可以通过阅读我们的如何处理Python 3教程中的纯文本文件来了解有关处理文本文件的更多信息。
完成代码和代码改进
在这一点上,你应该有一个完整功能的程序,将确定.txt文件中给定词的字频率。
下面是我们为这个项目完成的代码。
import matplotlib.pyplot as plt
import sys
import operator
import argparse
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"word",
help="the word to be searched for in the text file."
)
parser.add_argument(
"filename",
help="the path to the text file to be searched through"
)
args = parser.parse_args()
try:
open(args.filename)
except FileNotFoundError:
# Custom error print
sys.stderr.write("Error: " + args.filename + " does not exist!")
sys.exit(1)
word_freq(args.word, args.filename)
def word_freq(word, filename):
doc = {}
for line in open(filename):
# Assume each word is separated by a space
split = line.split(' ')
for entry in split:
if (doc.__contains__(entry)):
doc[entry] = int(doc.get(entry)) + 1
else:
doc[entry] = 1
if (word not in doc):
sys.stderr.write("Error: " + word + " does not appear in " + filename)
sys.exit(1)
sorted_doc = (sorted(doc.items(), key=operator.itemgetter(1)))[::-1]
just_the_occur = []
just_the_rank = []
word_rank = 0
word_frequency = 0
entry_num = 1
for entry in sorted_doc:
if (entry[0] == word):
word_rank = entry_num
word_frequency = entry[1]
just_the_rank.append(entry_num)
entry_num += 1
just_the_occur.append(entry[1])
plt.title("Word Frequencies in " + filename)
plt.ylabel("Total Number of Occurrences")
plt.xlabel("Rank of word(\"" + word + "\" is rank " + str(word_rank) + ")")
plt.loglog(just_the_rank, just_the_occur, basex=10)
plt.scatter(
[word_rank],
[word_frequency],
color="orange",
marker="*",
s=100,
label=word
)
plt.show()
if __name__ == "__main__":
main()
现在一切都完成了,我们可以做一些潜在的改进和修改这个代码。
如果我们想比较两个字的频率,那么我们将在我们的命令行参数中添加一个额外的字位置。 要完成这个,我们必须添加另一个检查器的单词和更多的变量的单词。
我们还可以修改程序,以便比较每个单词与另一个单词的长度。 要做到这一点,我们将比较长度的词,并将每个唯一的长度保存到字典。
结论
我们刚刚创建了一个程序来读取文本文件,并组织数据以查看特定词与文本中其他词相比的频率。
如果您对数据可视化感兴趣,您还可以查看我们如何使用JavaScript和D3 Library教程制作条形图 。







