一些公司不能让他们的服务失效。 在服务器中断的情况下,蜂窝运营商可能会遇到计费系统停机,导致其所有客户端的连接丢失。 承认这种情况的潜在影响导致总是有计划B的想法。
在本文中,我们将介绍针对服务器故障的不同保护方式,以及用于部署VMmanager Cloud的架构,VMmanager Cloud是用于构建高可用性群集的控制面板。

前言
集群容忍领域的术语因网站而异。 为了避免混合不同的术语和定义,我们来概述在给定文章中将使用的术语和定义:
- 容错(FT)是系统在其组件故障后继续运行的能力。
- 集群是通过通信通道连接的一组服务器(集群节点)。
- 容错群集(FTC)是一个群集,其中一个服务器的故障不会导致整个群集完全不可用。 故障节点的功能将在其余节点之间自动重新分配。
- 持续可用性(CA)意味着用户可以利用该服务,而不会遇到任何超时。 自从节点出现故障以来已经有多长时间了。
- 高可用性(HA)意味着用户可能会遇到服务超时,以防其中一个节点出现故障; 然而,系统将在最少停机时自动恢复。
- CA群集是Continuous Availability群集。
- HA集群是高可用性集群。
需要在每个节点上部署包含10个节点的虚拟机的群集。 目标是在服务器发生故障后保护虚拟机。 双CPU服务器用于最大化机架的计算密度。
最初的腮红,一个公司最有吸引力的选择是在设备出现故障后仍然提供服务时部署Continuous Availability集群。 事实上,如果您需要维护计费系统的运行或自动化连续生产过程,则持续可用性是必须的。 然而,这种方法也有其陷阱和陷阱,这些陷阱和陷阱如下。
持续可用性
如果构建了具有此服务的物理或虚拟机的精确副本,则可以在任何给定时间提供服务的连续性。 这种冗余模型称为2N。 设备发生故障后创建服务器的副本需要时间,导致服务超时。 此外,在这种情况下,不可能从故障服务器检索RAM转储,这意味着包含的所有信息都将消失。
在硬件和软件层上有两种用于提供CA的方法。 让我们更详细地关注每个人。
硬件方法 表示双重服务器,其中所有组件都被复制,并且计算是同时且独立执行的。 通过使用专门的节点来检查来自两个部分的结果来实现同步。 如果节点检测到任何差异,它会尝试定义问题并修复错误。 如果无法修复错误,系统将关闭故障模块。
CA服务器制造商Stratus保证系统的整体停机时间每年不超过32秒。 这样的结果可以通过使用专用设备来实现。 据Stratus代表说,根据规格,每个同步模块的一个CA服务器具有双CPU的成本约为16万美元。 在这种情况下,整个CA集群的扩展价格将为$ 160万。
软件方法
在本文发布时,用于部署Continuous Availability集群的最流行的软件工具是VMware vSphere 。 该产品的连续可用性技术称为容错。
与硬件方法不同,该技术具有一定的要求,如:
- 物理主机上的CPU:
- 英特尔与Sandy Bridge架构(或更新)。 Avoton不支持。
- AMD推土机(或更新)。
- 具有容错能力的机器将以低延迟连接到一个10 Gb网络。 VMware强烈建议使用专用网络。
- 每个虚拟机不超过4个虚拟CPU。
- 每个物理主机不超过8个虚拟CPU。
- 每个物理主机不超过4个虚拟机。
- 虚拟机快照不可用。
- 存储vMotion不可用。
有关限制和不兼容性的完整列表可以在官方文档中找到。
vSphere许可基于物理CPU。 价格从每个许可证1750美元+年度订阅和支持550美元。 集群管理自动化还需要VMware vCenter Server的成本超过8000美元。 2N模型用于提供连续可用性,因此需要购买10台具有许可证的复制服务器,以便构建具有虚拟机的10个节点的集群。
软件的总成本为2 [ 每台服务器的CPU数量 ] *(10 [ 具有虚拟机的节点数 ] +10 [ 复制节点数 ])*(1750 + 550)[ 每个CPU的许可证成本 ] +8000 [ VMware vCenter Server成本 ] = $ 100 000.所有价格都将四舍五入。
在本文中没有描述特定节点配置,因为服务器组件总是根据集群的目的而有所不同。 网络设备也没有描述,因为它们在每种情况下应该是相同的。 本文将重点介绍那些将会有所不同的组件,这是许可证成本。
提及不再开发和支持的产品也很重要。
称为Remus的产品基于Xen虚拟化。 它是一种利用微快照技术的免费开源解决方案。 不幸的是,它的文档长期以来还没有更新:安装指南提供了Ubuntu 12.10的说明,即在2014年宣布了生命周期。即使Google搜索没有找到任何使用Remus进行操作的公司。
尝试修改QEMU以构建该技术上的连续可用性集群。 有两个项目在这个方向宣布工作。
第一个是Kemari ,由田村由郎开创的开源产品。 该项目旨在使用现场QEMU迁移。 最后一次承诺是在2011年2月提出的,这表明发展陷入僵局,不会继续下去。
第二个产品是Micro Checkpointing ,由Michael Hines创立的开源项目。 在过去一年的变更记录中没有发现任何类似于Kemari项目的活动。
这些事实使我们得出结论,到目前为止,KVM虚拟化的连续可用性根本就没有可能。
尽管持续可用性系统的所有优点,在部署和运行这些解决方案方面存在许多障碍。 然而,在某些情况下,可能需要容错,但不需要持续使用。 这种情况允许使用具有高可用性的群集。
高可用性
高可用性集群通过自动检测硬件是否关闭并随后在可用节点上启动服务来提供容错能力。
高可用性不支持在节点上启动的CPU的同步,并不总是允许同步本地磁盘。 考虑到这一点,建议将节点使用的驱动器定位在单独的独立存储(如网络存储)中。
原因很清楚:故障后无法到达节点,无法检索其存储设备的信息。 数据存储系统也应该是容错的,否则高可用性是不可能的。 因此,高可用性群集由两个子集群组成:
- 由虚拟机组成的节点组成的计算集群
- 具有由计算节点使用的磁盘的存储集群。
目前,有以下解决方案用于在群集节点上实现具有虚拟机的高可用性群集:
- 心跳,版本1? 与DRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- OpenStack;
- oVirt;
- 红帽企业虚拟化;
- 具有Hyper-V服务器角色的Windows Server故障转移群集
- VMmanager云。
我们来看看VMmanager Cloud。
VMmanager云
VMmanager Cloud是一种产品,可以部署高可用性群集并使用QEMU-KVM虚拟化。 选择此技术是因为它被积极开发和支持,并允许在虚拟机上安装任何操作系统。 该产品使用Corosync来检测集群的可用性。 如果其中一台服务器关闭,VMmanager将逐个分发其余的节点之间的虚拟机。
简化后的机制如下:
- 系统识别虚拟机数量最少的群集节点。
- 它检查是否有足够的RAM来定位机器。
- 如果相关机器的节点上有足够的内存,VMmanager将在此节点上创建一个新的虚拟机。
- 如果没有足够的内存,系统将使用更多虚拟机检查其他节点。
测试一些硬件配置和许多当前VMmanager Cloud用户的查询,这些用户通常需要45-90秒的时间来根据设备性能从故障节点分发和恢复所有虚拟机的运行。
建议将一个或几个节点作为防范紧急情况的安全措施,而不是在常规操作期间在这些节点上部署虚拟机。 它可以最大限度地减少在实时群集节点上缺少从故障节点添加虚拟机的资源的可能性。 如果仅使用一个备份节点,则这种安全模型称为N + 1。
VMmanager Cloud支持以下存储类型:文件系统,LVM,网络LVM,iSCSI和Ceph [ 特别是RBD(RADOS Block Device),Ceph 实现之一 ]。 后三种用于高可用性。
一个10个操作节点和一个备份节点的终身许可费用为3520欧元,即此日期为3865美元(一个许可证费用为每个节点320欧元,无论CPU数量如何)。 许可证包括一年免费更新; 从第二年开始,更新每个订阅模式以整个集群的每年880欧元的价格提供。
我们来看一下VMmanager Cloud如何用于高可用性集群的部署。
FirstByte
FirstByte于2016年2月开始提供云托管。最初,他们的群集建立在OpenStack上; 然而,在系统的可用性和成本方面缺乏专家,迫使他们寻找替代解决方案。 构建高可用性集群的新系统满足以下要求:
- 能够部署KVM虚拟机。
- 与Ceph整合。
- 与提供现有服务的计费系统集成。
- 经济实惠的成本。
- 软件开发人员的支持。
VMmanager Cloud适合所有要求。
FirstByte集群的独特功能:
- 数据传输基于以太网技术和思科设备。
- 路由通过使用Cisco ASR9001执行。 集群使用大约50000个IPv6地址。
- 计算节点和交换机之间的链路速度为10 Gbps。
- 交换机和存储节点之间的数据传输速度为20 Gbps,两个组合通道为10 Gbps。
- 在具有存储节点进行复制的机架之间使用单独的20 Gbps链路。
- 与SSD相结合的SAS磁盘安装在所有存储节点上。
- 存储类型是RBD。
系统布局如下:
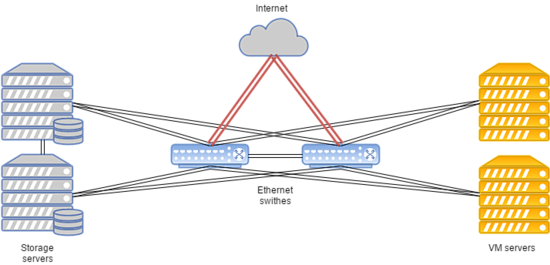
这样的配置适用于托管流行网站,游戏服务器和数据库,负载高于平均水平。
FirstVDS
FirstVDS提供了从2015年9月开始的容错群集服务。
由于以下因素,VMmanager Cloud被选为此群集:
- 使用ISP系统控制面板的丰富经验。
- 与默认的BILLmanager集成。
- 高品质的技术支持。
- 与Ceph整合。
它们的集群具有以下特点:
- 数据传输基于InfiniBand网络,连接速度为56 Gbps;
- Infiniband网络建立在Mellanox设备上;
- 存储节点具有SSD驱动器;
- 存储类型是RBD。
该系统可以按以下方式布置:
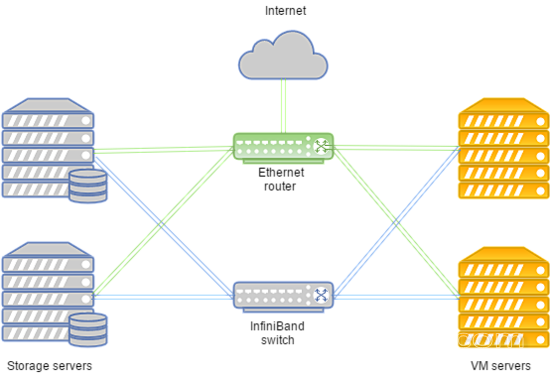
在Infiniband网络故障的情况下,VM磁盘存储和计算服务器之间的连接是通过部署在Juniper设备上的以太网进行建立的。 新连接将自动设置。
由于与存储器的高速通信,该集群可以非常适用于拥有超高流量,视频和内容流以及大数据的托管网站。
结论
我们来总结一下这篇文章的主要发现。
持续可用性集群是每隔一秒的停机时间带来巨大损失的必需品。 如果在备份节点上部署虚拟机时允许其中断5分钟,则高可用性集群可以降低硬件和软件成本。
同样重要的是要提醒,实现容错的唯一方法是过度的。 确保复制您的服务器,数据通信设备和链接,上网通道和电源。 复制一切你可以 这样的措施有可能消除瓶颈和潜在的故障点,这可能导致整个系统的停机。 通过采取上述措施,您可以确保您具有抵御故障的容错群集。
如果您认为高可用性模式符合您的要求,并且VMmanager Cloud是实现此目标的好工具,请参阅安装手册和文档以了解有关系统的更多信息。 祝你无故障,持续运作!







