虽然Linux是非常可靠的,明智的系统管理员应该找到一种方法来随时关注系统的行为和利用率。 确保接近100%越好,资源的可用性正常运行时间是在许多环境中的关键需求。 检查系统的过去和当前状态将允许我们预见并最有可能防止可能的问题。

Linux基础认证工程师 - 第9部分
Linux基础认证计划简介
在本文中,我们将介绍大多数上游分发版中可用的几个工具的列表,以检查系统状态,分析中断以及解决正在进行的问题。 具体来说,在无数的可用数据中,我们将关注CPU,存储空间和内存利用率,基本过程管理和日志分析。
存储空间利用率
在Linux中2熟知的命令,用于检查存储空间使用率:DF和杜 。
第一个,DF(代表盘免费),通常用于报告文件系统的总磁盘空间使用情况。
示例1:报告磁盘空间使用情况(以字节为单位)和人为可读格式
如果没有选择, 自由度报告以字节为单位的磁盘空间使用情况。 与-h标志会显示使用MB或GB,而不是相同的信息。 请注意,此报告还包括每个文件系统的总大小(1-K块),空闲和可用空间以及每个存储设备的安装点。
# df # df -h
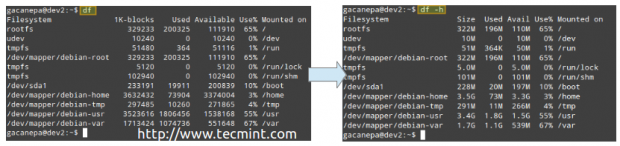
磁盘空间利用率
这当然很好 - 但有另一个限制,可以渲染文件系统不可用,并且正在运行inode。 文件系统中的所有文件都映射到包含其元数据的inode。
示例2:以可读格式检查文件系统的inode使用情况
# df -hTi
您可以看到已用和可用的inode的数量:
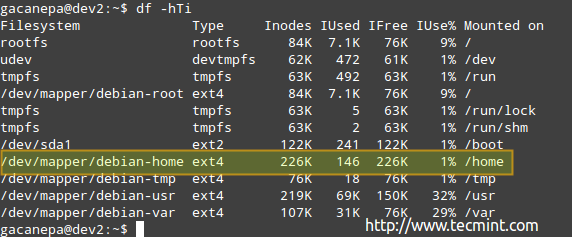
Inode磁盘使用率
根据上面的图片中,有146使用的索引节点(1%)在/ home,这意味着你仍然可以在该文件系统中创建226K的文件。
示例3:查找和/或删除空文件和目录
请注意,您可以在耗尽inode之前耗尽存储空间,反之亦然。 因此,您不仅需要监视存储空间利用率,还需要监视文件系统使用的索引节点数。
使用以下命令查找正在使用inode且没有原因的空文件或目录(占用0B):
# find /home -type f -empty # find /home -type d -empty
此外,您还可以在每个命令的末尾添加-delete标志,如果你也想删除这些空文件和目录:
# find /home -type f -empty --delete # find /home -type f -empty
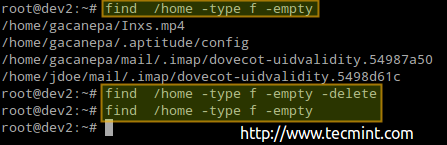
在Linux中查找和删除空文件
上一个过程删除了4个文件。 让我们再次检查/ home中的已用/可用节点数:
# df -hTi | grep home

检查Linux Inode使用情况
正如你所看到的,有142使用的索引节点现在(4比以前少了)。
示例4:按目录检查磁盘使用情况
如果使用特定的文件系统高于预定的百分比,您可以用杜 (简称磁盘使用情况)来找出哪些是占用了大部分空间的文件。
这个例子给出了/ VAR,正如你可以在上面的第一个图片中看到,在其67%的人使用。
# du -sch /var/*
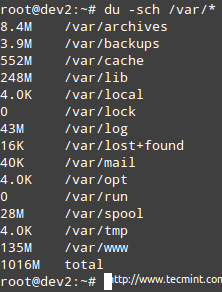
按目录检查磁盘空间使用情况
注意 :您可以切换到上述任何子目录找出到底什么在他们多少每个项目占用。 然后,您可以使用该信息删除某些文件(如果不需要)或在必要时扩展逻辑卷的大小。
阅读
内存和CPU利用率
在Linux中的经典工具,用于执行CPU /内存使用率和流程管理的全面检查是靠前指挥 。 此外,top显示正在运行的系统的实时视图。 可能被用于同样目的,如还有其他工具HTOP ,因为它已安装,但我已经解决了顶外的开箱任何Linux发行版。
示例5:使用顶部显示系统的实时状态
要开始,只需在命令行中键入以下命令,然后按Enter键。
# top
让我们来看一个典型的顶部输出:
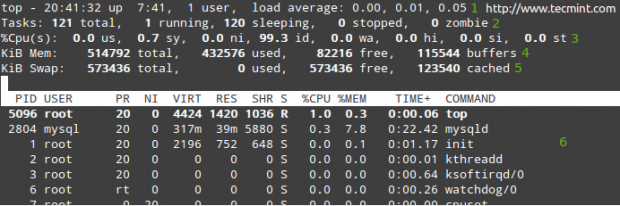
列出Linux中的所有运行进程
在行1到5中,显示以下信息:
1.当前时刻(下午8时41分32秒)和运行时间(7小时41分钟)。 只有一个用户登录到系统,并分别在最近1分钟,5分钟和15分钟内的平均负载。 0.00,0.01和0.05表示在这些时间间隔内,系统在0%的时间内空闲(0.00:没有进程等待CPU),然后过载1%(0.01:0.01个进程的平均值等待CPU)和5%(0.05)。 如果小于0并且数字越小(例如,0.65),则系统在最后1,5或15分钟期间空闲35%,这取决于0.65出现在哪里。
2.目前有121进程中运行的(你可以看到在6完整列表)。 只有其中一个正在运行(在这种情况下为顶部,正如您可以在%CPU列中看到的),剩余的120个在后台等待,但处于“睡眠”状态,直到我们调用它们。 怎么样? 您可以通过打开一个mysql提示并执行几个查询来验证这一点。 你会注意到运行进程的数量如何增加。
或者,您可以打开Web浏览器并导航到由Apache提供的任何给定页面,您将获得相同的结果。 当然,这些示例假设两个服务都安装在您的服务器中。
3.我们(运行时间与未改性的优先级用户的进程),SY(时间运行的内核进程),NI(改性时间优先运行的用户进程),华盛顿(时间等待I / O完成),喜(花在服务硬件中断时间),si(用于服务软件中断的时间),st(由虚拟机管理程序从当前vm中偷来的时间 - 仅在虚拟化环境中)。
4.物理内存使用情况。
5.交换空间使用率。
示例6:检查物理内存使用情况
要检查RAM内存和交换使用情况,您还可以使用免费的命令。
# free

检查Linux内存使用情况
当然,你也可以使用-m(MB)或-g(GB)切换到显示在人类可读的形式相同的信息:
# free -m

查看Linux内存使用情况
无论哪种方式,您都需要知道内核保留尽可能多的内存,并在进程请求时使内存可用。 特别是,“ - / +缓冲区/高速缓存 ”线显示I / O缓存是考虑到之后的实际值。
换言之,(在这种情况下,使用232 MB和270 MB可用,分别)的存储器进程和提供给其它进程的量的使用量。 当进程需要这个内存时,内核将自动减小I / O缓存的大小。
另请阅读 : 10有用的“免费”命令检查Linux的内存使用情况
仔细观察过程
在任何给定的时间,有许多进程在我们的Linux系统上运行。 有两个工具,我们将使用密切监视进程:ps和pstree。
示例7:使用ps(全标准格式)在系统中显示整个进程列表
使用-e和-f选项合并成一个(-ef),你可以列出当前系统中运行的所有进程。 你可以管这个输出到其它工具,如grep的 (说明的LFCS系列第1部分 ),以输出缩小到你想要的过程(ES):
# ps -ef | grep -i squid | grep -v grep
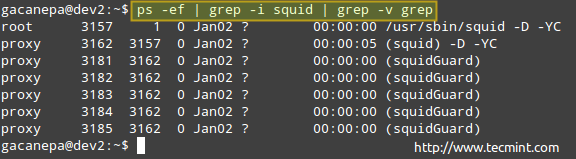
在Linux中监视进程
上面的过程列表显示以下信息:
PID,父PID(父进程),处理器利用率,命令启动时间,tty(?表示它是一个守护程序),累积的CPU时间和与进程相关的命令。
示例8:定制和排序ps的输出
然而,也许你不需要所有的信息,并想显示进程的所有者,启动它的命令,它的PID和PPID,以及它当前使用的内存的百分比,按顺序,并按排序内存使用按降序(注意ps默认是按PID排序)。
# ps -eo user,comm,pid,ppid,%mem --sort -%mem
其中%mem前面的减号表示按降序排序。
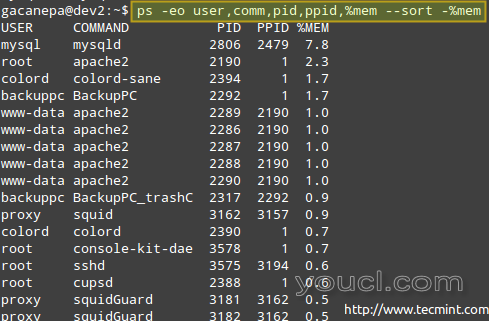
监控Linux进程内存使用情况
如果由于某种原因,过程开始服用过多的系统资源,很可能危及系统的整体功能,你将要停止或暂停其执行通过使用下列信号之一杀程序吧。 其他的原因,你会考虑这样做是当你在前台启动一个进程,但想暂停它,并在后台恢复。
| 信号名称 | 信号编号 | 描述 |
| 信号 | 15 | 优雅地杀死过程。 |
| SIGINT | 2 | 这是当我们按Ctrl + C时发送的信号。它旨在中断进程,但进程可能会忽略它。 |
| SIGKILL | 9 | 该信号也中断过程,但它无条件地使用(小心使用!),因为进程不能忽略它。 |
| SIGHUP | 1 | “Hang UP”的缩写,这个信号指示守护进程重新读取其配置文件,而不实际停止进程。 |
| SIGTSTP | 20 | 暂停执行并等待准备继续。 这是当我们键入Ctrl + Z组合键时发送的信号。 |
| SIGSTOP | 19 | 该过程暂停,在重新启动之前不再受CPU周期的影响。 |
| SIGCONT | 18 | 该信号指示进程在接收到SIGTSTP或SIGSTOP之后恢复执行。 这是当我们使用fg或bg命令时由shell发送的信号。 |
示例9:暂停正在运行的进程的执行并在后台恢复它
当某个进程的正常执行意味着没有输出将在屏幕运行时发送到屏幕,您可能想要在后台启动它(在命令结尾添加一个&符号)。
process_name &
要么,
一旦它开始在前台运行,暂停它,并将其发送到背景
Ctrl + Z
# kill -18 PID
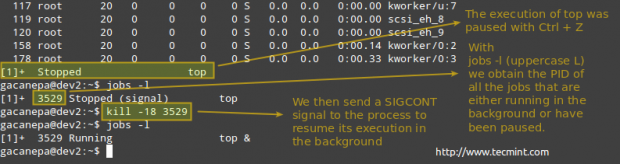
在Linux中杀死进程
实施例10:用力杀死“灭绝”
请注意,每个分布提供了工具来正常停止/启动/重新启动/重新加载共同服务,如基于SysV的系统服务或systemctl基于systemd系统。
如果进程不响应这些实用程序,您可以强制通过向其发送SIGKILL信号来终止它。
# ps -ef | grep apache # kill -9 3821
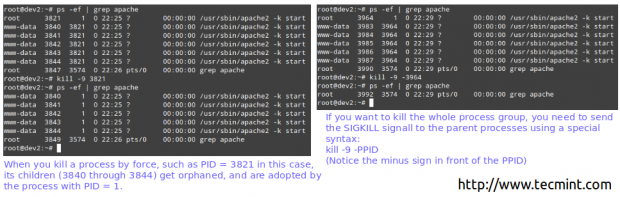
强制杀死Linux进程
所以..发生了什么/发生了什么?
当出现了任何故障的系统(无论是停电,硬件故障,一个过程的计划内或计划外的中断,或在所有任何异常),在/ var日志/日志是你最好的朋友确定发生了什么或可能导致您面临的问题。
# cd /var/log

查看Linux日志
一些在/ var / log中的项目是普通的文本文件,其他都是目录,还有一些是旋转(历史)日志的压缩文件。 你会想要检查那些在他们的名字有一个错误,但检查其余的也可以派上用场。
示例11:检查进程中错误的日志
图片这个场景。 您的LAN客户端无法打印到网络打印机。 第一步要解决这种情况是要在/ var /日志/ cups目录,看看里面有什么了。
您可以使用tail命令来显示最后10行的error_log文件,或者尾-f error_log中的日志的实时视图。
# cd /var/log/cups # ls # tail error_log
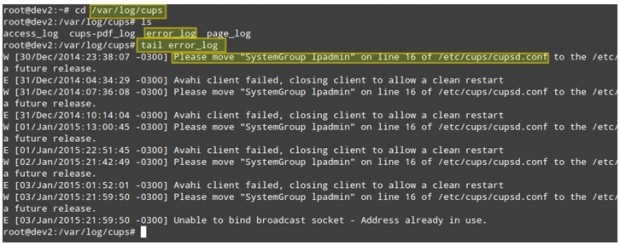
实时监视日志文件
上述屏幕截图提供了一些有用的信息,以了解可能导致您的问题的原因。 请注意,按照步骤或纠正进程的故障仍然可能无法解决整体问题,但如果您从一开始就使用,每次出现问题(无论是本地还是网络)时检查日志,您肯定会在正确的轨道上。
示例12:检查硬件故障的日志
虽然硬件故障可能会非常棘手排除故障,应检查dmesg的和消息日志和grep相关的字来推测故障的硬件部分。
下面的图片是在/ var / log / messages中所寻找使用下面的命令字错误后:
# less /var/log/messages | grep -i error
我们可以看到,我们遇到与两个存储设备的一个问题是:/ dev / sdb的和/ dev / sdc的 ,而这又导致一个问题的RAID阵列。

排除Linux问题
结论
在本文中,我们探讨了一些可以帮助您始终了解系统总体状态的工具。 此外,您需要确保您的操作系统和已安装的软件包已更新到最新的稳定版本。 永远不要忘记检查日志! 然后你将朝着正确的方向前进,找到任何问题的最终解决方案。
随时留下您的意见,建议或问题 - 如果你有任何 - 使用下面的表格。







