在此以前的文章RAID系列你从零到英雄RAID。 我们回顾了几个软件RAID配置,并解释了每一个的基本要素,以及根据您的具体情况,你会倾向于一个或另一个的原因。

恢复重建失败的软件RAID - 第8部分
在本指南中,我们将讨论如何在发生磁盘故障时重建软件RAID阵列,而不会丢失数据。 为简便起见,我们将只考虑一个RAID 1的设置-但其概念和命令适用于所有的一致好评案件。
RAID测试方案
在进一步讨论之前,请确保您已设置RAID 1阵列按照本系列的第3部分提供的说明: 如何组建RAID 1(镜像)在Linux中 。
我们目前情况下的唯一变化是:
1)的不同版本的CentOS(V7),比在第(V6.5使用的),并
2) 为/ dev / sdb的和/ dev / SDC不同的磁盘大小(8 GB每个)。
此外,如果是SELinux在执行模式下启用,您需要将相应的标签添加到目录中,你会安装RAID设备。 否则,在尝试安装时会遇到此警告消息:
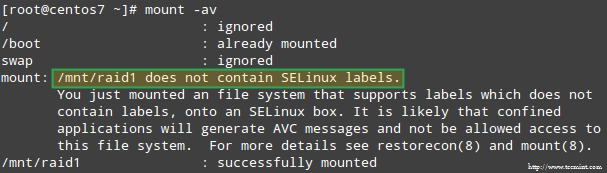
SELinux RAID装载错误
你可以通过运行:
# restorecon -R /mnt/raid1
设置RAID监控
存储设备可能出现故障的原因有很多种(虽然SSD已经大大降低了发生这种情况的可能性),但无论何种原因,您都可以确定问题可以随时发生,您需要准备更换故障部分并确保数据的可用性和完整性。
首先是建议。 即使你可以以检查你的RAID状态检查的/ proc / mdstat,有一个由运行在监控+扫描模式的mdadm,将通过电子邮件将警报发送到预定义的收件人更好的和节省时间的方法。
要这样设置,添加mdadm.conf中下面一行:
MAILADDR user@<domain or localhost>
在我的情况下:
MAILADDR gacanepa@localhost

RAID监视电子邮件警报
要运行监控+扫描模式的mdadm,添加以下crontab条目为根:
@reboot /sbin/mdadm --monitor --scan --oneshot
默认情况下, 的mdadm将检查RAID阵列每60秒,如果发现的问题发出警报。 您可以通过添加修改此行为--delay选项crontab条目上方伴随着秒为单位(例如, --delay 1800意味着30分钟)。
最后,确保你已经安装,如邮件用户代理 (MUA) 狗或mailx的 。 否则,您将不会收到任何警报。
在一分钟内,我们会看到什么样的mdadm通过发送警报的模样。
模拟和替换故障的RAID存储设备
到与RAID阵列中的存储设备中的一个模拟的问题中,我们将使用--manage和--set-faulty选项如下:
# mdadm --manage --set-faulty /dev/md0 /dev/sdc1
这将导致的/ dev / SDC1被标记为故障时,我们可以看到在/ proc / mdstat:
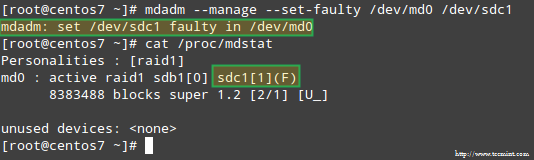
使用RAID存储来刺激问题
更重要的是,让我们看看我们是否收到了同样警告的电子邮件提醒:
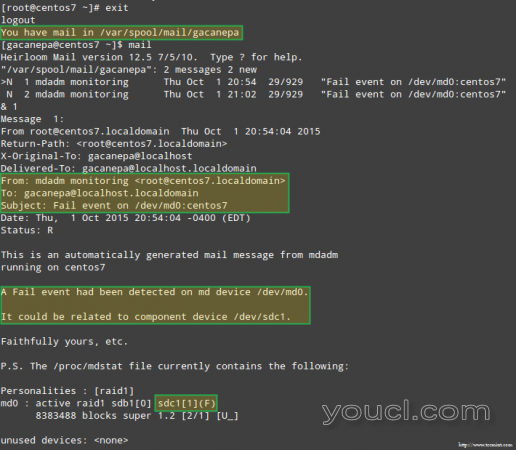
失败的RAID设备上的电子邮件警报
在这种情况下,您需要从软件RAID阵列中删除设备:
# mdadm /dev/md0 --remove /dev/sdc1
然后你可以从物理机中取出,并用零配件( 为/ dev / SDD,其中类型FD的分区已被以前创建)替换它:
# mdadm --manage /dev/md0 --add /dev/sdd1
幸运的是,对我们来说,系统将自动开始重建数组,并添加刚才添加的部分。 我们可以通过标记的/ dev / sdb1的出现故障,从阵列中取出,并确保该文件youcl.txt仍然是在/ mnt / RAID1访问的测试:
# mdadm --detail /dev/md0 # mount | grep raid1 # ls -l /mnt/raid1 | grep youcl # cat /mnt/raid1/youcl.txt
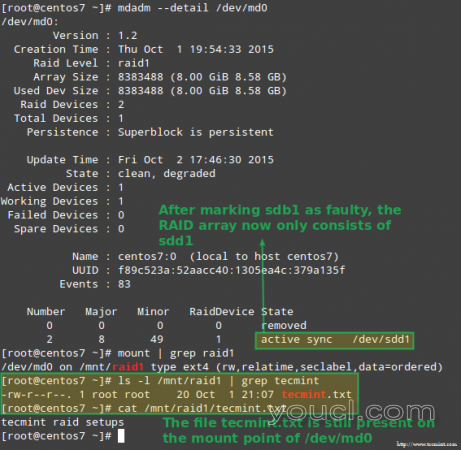
确认重建RAID阵列
上面清晰的图像显示,添加的/ dev / SDD1到阵列作为的/ dev / SDC1更换后,数据的重建是由系统自动无需我方介入进行。
尽管不是严格要求,但是有一个很好的想法是有一个备用设备,以便更换有故障的设备与一个良好的驱动器的过程可以快速完成。 要做到这一点,让我们重新添加/ dev / sdb1的和/ dev / SDC1:
# mdadm --manage /dev/md0 --add /dev/sdb1 # mdadm --manage /dev/md0 --add /dev/sdc1
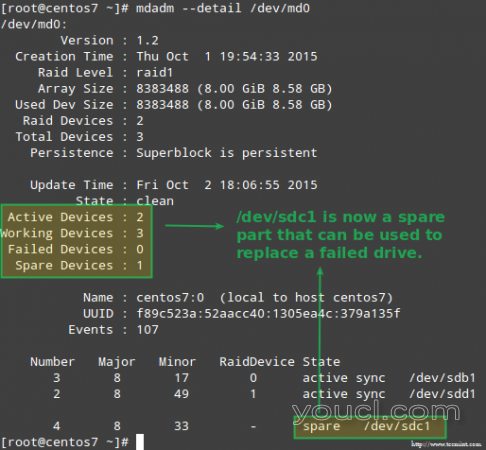
替换失败的Raid设备
从冗余丢失中恢复
如前面所解释的,当一个磁盘发生故障的mdadm将自动重建数据。 但是,如果阵列中的2个磁盘失败,会发生什么? 让我们通过标记的/ dev / SDB1和/ dev / SDD1出现故障模拟这样的场景:
# umount /mnt/raid1 # mdadm --manage --set-faulty /dev/md0 /dev/sdb1 # mdadm --stop /dev/md0 # mdadm --manage --set-faulty /dev/md0 /dev/sdd1
尝试重新创建阵列有人在这个时候(或使用创建的相同方式--assume-clean选项),可能会导致数据丢失,所以应该留下作为最后的手段。
让我们试着从/ dev / sdb1的恢复数据,例如,进入一个类似的磁盘分区( 的/ dev / SDE1 -注意,这需要你的/ dev / SDE继续前创建型FD的分区)使用ddrescue:
# ddrescue -r 2 /dev/sdb1 /dev/sde1
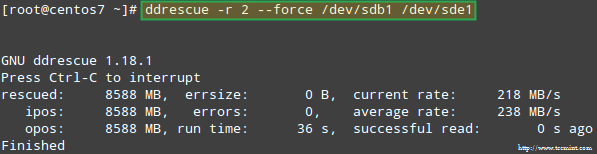
恢复RAID数组
请注意,到现在为止,我们还没有触及的/ dev / sdb的或/ dev / sdd的 ,是那样的RAID阵列的一部分的分区。
现在,让我们用重建阵列的/ dev / SDE1和/ dev / SDF1:
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[e-f]1
请注意,在真实的情况下,你通常会使用相同的设备名称与原来的数组,即中,/ dev /故障磁盘后SDB1和/ dev / SDC1都换成了新的。
在本文中,我选择使用额外的设备来重新创建具有全新磁盘的阵列,并避免与原始故障驱动器混淆。
当被问到是否会继续写下去阵列,键入Y,然后按Enter。 数组应该启动,你应该能够看到它的进展:
# watch -n 1 cat /proc/mdstat
过程完成后,您应该能够访问RAID的内容:
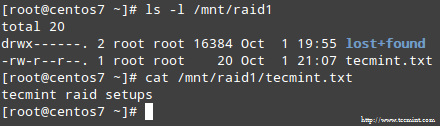
确认Raid内容
概要
在本文中,我们了解了如何从RAID故障和冗余的损失中恢复过来。 但是,你要记住,这个技术是一个存储解决方案,并不能取代备份。
本指南中解释的原则适用于所有RAID设置,以及我们将在本系列的下一篇和最终指南(RAID管理)中介绍的概念。
如果您对本文有任何疑问,请随时使用下面的评论表单给我们留言。 我们期待您的回音!







