介绍
如果你使用监控系统(如Zabbix或Nagios),那么你知道监控如何工作。简而言之,它可以描述如下:监控系统接收各种度量(CPU /内存使用,网络利用率等)。一个度量的值超出预定阈值,它将激活相应的触发器,监视系统会通知您其中一个度量超出正常限制。通常手动设置每个指标的阈值,这并不总是方便的。 在本教程中,您将学习如何安装和配置 Skyline -一个实时的异常检测系统。它能够实时分析一组度量,而无需设置或调整每个度量的阈值。它被设计为在需要持续监视的大量时间序列(几十万)的任何地方使用。阈值触发器
让我们看一个带有手动设置阈值的监控系统的示例。下图显示了CPU负载的图表。虚线表示触发器的阈值。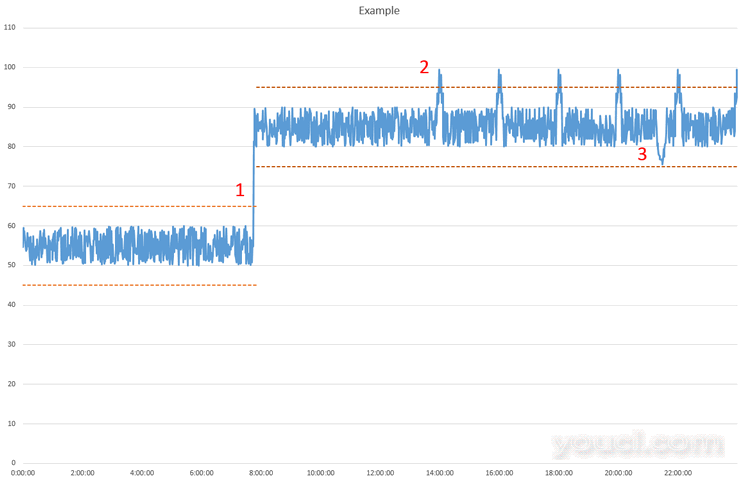 图1 在图1中的点1处,过程已经开始,并且CPU负载显着增加。触发器已激活,管理员注意到。管理员确定它在正常值内,并将触发阈值更改为显示为上部虚线的阈值。 经过一段时间后,触发器在图1中的点2再次触发。管理员发现第二个服务正在定期进行备份并导致负载增加。然后问题出现:你提高阈值更高还是保持原样,但只是忽略报警? 让我们来看看点3.在那一刻,事件负载下降,但是没有通知管理员,因为没有超过阈值。触发器未激活。 这个简单的例子告诉我们,当尝试设置阈值时有一些困难。很难调整阈值以捕获性能问题,而不会触发假阳性错误或假否定错误。 为了帮助解决这些问题,
Skyline已创建。它使用一组非参数算法来对异常度量进行分类。
图1 在图1中的点1处,过程已经开始,并且CPU负载显着增加。触发器已激活,管理员注意到。管理员确定它在正常值内,并将触发阈值更改为显示为上部虚线的阈值。 经过一段时间后,触发器在图1中的点2再次触发。管理员发现第二个服务正在定期进行备份并导致负载增加。然后问题出现:你提高阈值更高还是保持原样,但只是忽略报警? 让我们来看看点3.在那一刻,事件负载下降,但是没有通知管理员,因为没有超过阈值。触发器未激活。 这个简单的例子告诉我们,当尝试设置阈值时有一些困难。很难调整阈值以捕获性能问题,而不会触发假阳性错误或假否定错误。 为了帮助解决这些问题,
Skyline已创建。它使用一组非参数算法来对异常度量进行分类。
Skyline组件
Skyline由以下组件组成:Horizon Agent,Analyzer代理和Webapp。Horizon代理
Horizon Agent负责收集数据。它 的监听器 ,监听输入数据。 它接受在两种格式中的数据: pickle (TCP)和 MessagePack (UDP)。 它读取输入的指标,并把它们放在一个共享队列, 工人读取。 工作者将数据编码到Messagepack中,并将其附加到Redis数据库。 Horizon代理还定期修剪和清理使用 Roombas老指标。如果这没有完成,那么所有的空闲内存很快就会耗尽。分析器代理
分析器代理负责分析数据。它从Redis接收指标列表,运行多个进程,并为每个进程分配指标。每个过程使用几种算法分析数据。每个算法报告结果 - 数据是否异常。如果大多数的算法报告当前量度具有异常时,该数据被认为是 异常的 。 所有异常指标都写入文件。在此文件的基础上,将创建一个图像并显示在Web应用程序中。 分析器还可以发送通知:电子邮件,HipChat或PagerDuty。电子邮件通知在本文稍后配置。Webapp
Skyline提供了一个小型Web应用程序来显示异常指标。这是一个用Python编写的简单的web应用程序,带有Flask框架。上部显示两个图表 - 过去一小时和过去一天。图表下方是所有异常指标的列表。Redis数据库
Redis的是一个开源的键值缓存和存储数据库。 Skyline将所有度量和编码的时间系列存储在Redis数据库中。 当一个数据点进来,一Horizon工人包的数据点与架构[timestamp, value]成MessagePack编码的二进制串并追加此字符串与适当的衡量标准键。
图2显示了Horizon的组分的相互作用的图。
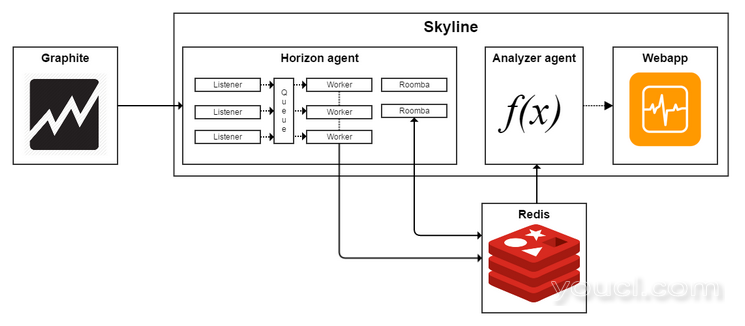 图2
图2
先决条件
在您可以安装Skyline之前,您需要完成以下先决条件:- 部署CentOS 7 Droplet。
- 通过遵循添加Sudo用户初始服务器设置教程。本教程中的所有命令都应以此非root用户身份运行。
- 添加交换空间到你的服务器。 4 GB是好的。
- 安装Graphite并按照中的说明collectd 如何保持有效的历史日志Graphite, Carbon,并在CentOS collectd 7教程。
第1步 - 安装Skyline和Redis
要安装Skyline,首先安装所需的应用程序,包括一些Python相关工具和Apache Web服务器:sudo yum install httpd gcc gcc-c++ git pycairo mod_wsgi python-pip python-devel blas-devel lapack-devel libffi-devel
cd /opt
sudo git clone https://github.com/etsy/skyline.git
cd /opt/skyline
sudo pip install -U six
sudo pip install -r requirements.txt
sudo pip install numpy
sudo pip install scipy
sudo pip install pandas
sudo pip install patsy
sudo pip install statsmodels
sudo pip install msgpack-python
msgpack-python包是必要的阅读和写作
MessagePack数据。 将示例Skyline设置文件复制到正确的文件位置:
sudo cp /opt/skyline/src/settings.py.example /opt/skyline/src/settings.py
sudo mkdir /var/log/skyline
sudo mkdir /var/run/skyline
sudo mkdir /var/log/redis
sudo mkdir /var/dump/
sudo yum install redis
cd /opt/skyline/bin
sudo redis-server redis.conf
sudo ./horizon.d start
sudo ./analyzer.d start
sudo ./webapp.d start
python /opt/skyline/utils/seed_data.py
Loading data over UDP via Horizon...
Connecting to Redis...
Congratulations! The data made it in. The Horizon pipeline seems to be working.
第2步 - 将数据导入Skyline
如前面提到的,Skyline接受两种格式的数据: pickle (TCP)和 MessagePack (UDP)。 您可以将自己的脚本或模块写入您喜爱的监视代理,并使用MessagePack对数据进行编码,以发送到Skyline进行分析。 Skyline接受通过UDP的MessagePack编码字符串形式的度量。 MessagePack是一个对象序列化规范,如JSON。格式为[<metric name>, [<timestamp>, <value>]] MessagePack对大多数编程语言都有一个API。 更多信息和API的例子可以找到关于
MessagePack官方网站 。 本教程将向您介绍如何将数据从Graphite和collectd发送到Skyline。
从Graphite获取数据
Graphite由几个部分组成,其中之一是 Carbon-中继服务。 Carbon中继将传入的度量转发到另一个Graphite实例以实现冗余。因此,您可以将 Carbon中继服务指向Skyline正在运行的主机。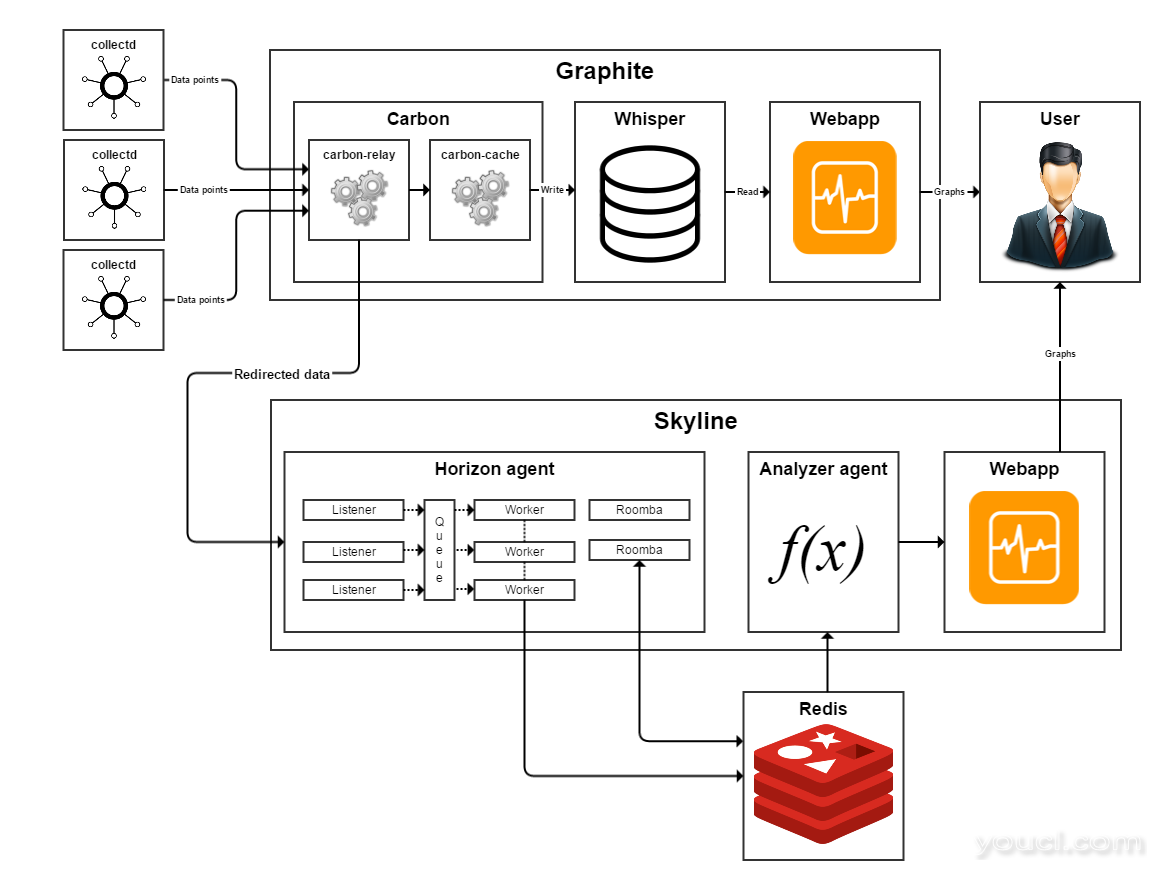 图3 图3示出了数据流的示意图。从外部监视代理(数据
collectd ,
diamond ,
statsd等)或系统(
Nagios ,
Icinga ,
Sensu等)被转移到Graphite。接下来, Carbon中继将数据转发到Skyline。 Carbon中继, Carbon缓存和Skyline可以在单个主机上运行,也可以在单独的主机上运行。 您需要配置Graphite,collectd和Skyline以使此数据流工作。 如果没有的例子复制
图3 图3示出了数据流的示意图。从外部监视代理(数据
collectd ,
diamond ,
statsd等)或系统(
Nagios ,
Icinga ,
Sensu等)被转移到Graphite。接下来, Carbon中继将数据转发到Skyline。 Carbon中继, Carbon缓存和Skyline可以在单个主机上运行,也可以在单独的主机上运行。 您需要配置Graphite,collectd和Skyline以使此数据流工作。 如果没有的例子复制
relay-rules.conf为早期 Carbon中继配置文件中的正确位置,你现在要做的是:
sudo cp /opt/graphite/conf/relay-rules.conf.example /opt/graphite/conf/relay-rules.conf
relay-rules.conf配置文件进行编辑:
sudo vi /opt/graphite/conf/relay-rules.conf
/opt/graphite/conf/relay-rules.conf
[default]
default = true
destinations = 127.0.0.1:2004, YOUR_SKYLINE_HOST:2024
relay-rules.conf也必须在限定
carbon.conf配置文件。 打开
carbon.conf配置文件进行更改:
sudo vi /opt/graphite/conf/carbon.conf
[relay]部分,并编辑
DESTINATIONS行:
/opt/graphite/conf/carbon.conf
[relay]
...
DESTINATIONS = 127.0.0.1:2004, YOUR_SKYLINE_HOST:2024
...
sudo systemctl start carbon-relay
允许Skyline访问Graphite-Web
在 如何保持有效的历史日志Graphite, Carbon和collectd在CentOS 7 ,如果你当选密码保护Graphiteweb界面,您 必须允许无密码,从本地主机访问的Skyline工作。 为此,请编辑Graphite配置文件:sudo vi /etc/httpd/conf.d/graphite.conf
<Location>块:
/etc/httpd/conf.d/graphite.conf
<Location "/">
AuthType Basic
AuthName "Private Area"
AuthUserFile /opt/graphite/secure/.passwd
Require user sammy
Order Deny,Allow
Deny from all
Allow from localhost
Satisfy Any
</Location>
sudo systemctl restart httpd
从Collectd获取数据
您还可以配置collectd将数据发送到Skyline。打开其配置文件:sudo vi /etc/collectd.conf
<Plugin write_graphite>块
2013 :
/etc/collectd.conf
<Plugin write_graphite>
. . .
Port "2013"
. . .
sudo systemctl restart collectd.service
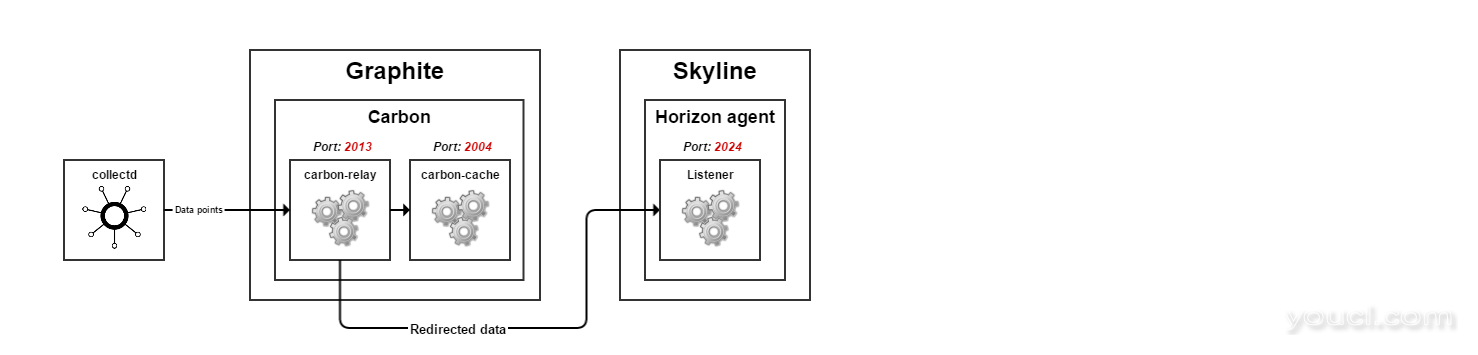 图4 正确的端口号如下:
图4 正确的端口号如下:
- Carbon继电器监听端口2013年明文格式输入数据
- Carbon中继发送数据格式咸菜
- Carbon缓存侦听端口2004年 pickle格式输入数据
- Horizon代理监听端口2024 pickle格式输入数据
第3步 - 设置Skyline
Skyline配置文件包含许多设置。打开文件进行编辑:sudo vi /opt/skyline/src/settings.py
GRAPHITE_HOST = ' YOUR_GRAPHITE_HOST 'HORIZON_IP = ' 0.0.0.0 'WEBAPP_IP = ' YOUR_SKYLINE_HOST_IP '
FULL_DURATION-这个选项指定的用于该数据将被存储在Redis的和分析的最大时间长度。 较长的持续时间需要较长的分析时间,但它们可以帮助降低噪声并提供更准确的异常检测。 默认值是86400秒。CARBON_PORT-此选项指定的 Carbon端口。 默认值是2003。ANALYZER_PROCESSES-此选项指定的Skyline分析仪将产生的进程数。 建议将此参数设置为小于主机上的CPU总数。 默认值为5。WORKER_PROCESSES-此选项指定的工作进程将从Horizon队列消耗的数量。 默认值为2。PICKLE_PORT-此选项指定监听Graphite的pickle的TCP端口。 默认值是2024。UDP_PORT-此选项指定监听MessagePack编码数据包的UDP端口。 默认值是2025。WEBAPP_PORT-此选项指定的端口SkylineWeb应用程序。 默认值是1500。
sudo /opt/skyline/bin/horizon.d restart
sudo /opt/skyline/bin/analyzer.d restart
sudo /opt/skyline/bin/webapp.d restart
http:// your_server_ip :1500 ,看到Skyline的网页(图5)。它会显示异常的指标,因为它们被发现。
 图5 对于Skyline在满负荷运转,需要等到
图5 对于Skyline在满负荷运转,需要等到
FULL_DURATION秒钟已经过去了。 缺省情况下,
FULL_DURATION设定为1天(
86400秒)。 您应该至少等待一个小时才能开始跟踪异常情况。这将使Skyline时间累积有关正常负载水平的信息。当Skyline正在建立基线时,尽量不要在系统上创建额外的负载。
第4步 - 启用电子邮件警报
默认情况下,Skyline显示检测到的在其网站界面异常(http:// your_server_ip :1500 ),因为他们发现,虽然他们仍然发生。异常消失后,其对应的度量会从此界面中消失。因此,您必须监控网页以查看这些异常,这并不总是方便。 您可以配置电子邮件提醒,以便不要错过它们。 为此,请打开Skyline配置文件:
sudo vi /opt/skyline/src/settings.py
/opt/syline/src/settings.py
ENABLE_ALERTS = True
/opt/syline/src/settings.py
ALERTS = (
(^)("collectd", "smtp", 1800)(^),
)
collectd.架构的第二值是
smtp ,它代表电子邮件警报。 的最后一个值
1800是秒。这意味着即使检测到触发,警报也不会在30分钟(1800秒)内触发多次。修改此值以最好地满足您的需求。 还可以找到以下部分,并针对要使用的电子邮件地址进行修改。电子邮件警报将被发送到(^)
administrator@example.com从(^)(^)帐户
skyline-alerts@example.com (^)。
/opt/syline/src/settings.py
SMTP_OPTS = {
"sender": "(^)skyline-alerts@example.com(^)",
"recipients": {
"collectd": ["(^)administrator@example.com(^)"],
},
}
sudo /opt/skyline/bin/analyzer.d restart
第5步 - 测试Skyline
要测试Skyline,我们可以使用bash命令创建CPU峰值:dd if=/dev/zero of=/dev/null
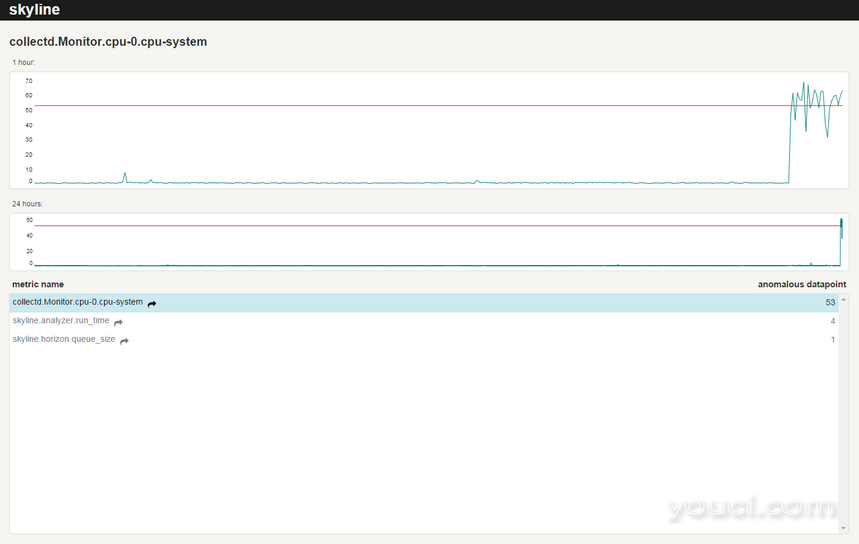 图6 您可以看到,由于高CPU负载,Skyline的组件速度降低。所有检测到的异常指标均以网页底部的列表形式显示。当您将鼠标悬停在某个指标的名称上时,在上面的图表中,您可以看到最近一小时和一天的相应时间系列。单击度量的名称以打开由Graphite生成的更详细的图(参见图7的示例)。
图6 您可以看到,由于高CPU负载,Skyline的组件速度降低。所有检测到的异常指标均以网页底部的列表形式显示。当您将鼠标悬停在某个指标的名称上时,在上面的图表中,您可以看到最近一小时和一天的相应时间系列。单击度量的名称以打开由Graphite生成的更详细的图(参见图7的示例)。
 图7 在此示例中,CPU负载没有达到极高值,并且未超过阈值。在这种情况下,经典的监测系统不能发现偏差。这种情况刚才提到(图1,点3)。 与经典监控系统不同,Skyline可以快速找到偏差并通知您。
图7 在此示例中,CPU负载没有达到极高值,并且未超过阈值。在这种情况下,经典的监测系统不能发现偏差。这种情况刚才提到(图1,点3)。 与经典监控系统不同,Skyline可以快速找到偏差并通知您。
第6步 - 调整算法(可选)
如前所述,Skyline正在使用一组算法来检测异常。当前实现了以下算法:- 平均绝对偏差
- 格鲁布斯测试
- 第一小时平均
- 与平均值的标准偏差
- 与移动平均值的标准偏差
- 最小二乘
- 直方图箱
- Kolmogorov-Smirnov试验
sudo vi /opt/skyline/src/analyzer/algorithms.py
/opt/skyline/src/analyzer/algorithms.py
def median_absolute_deviation(timeseries):
"""
A timeseries is anomalous if the deviation of its latest datapoint with
respect to the median is X times larger than the median of deviations.
"""
series = pandas.Series([x[1] for x in timeseries])
median = series.median()
demedianed = np.abs(series - median)
median_deviation = demedianed.median()
# The test statistic is infinite when the median is zero,
# so it becomes super sensitive. We play it safe and skip when this happens.
if median_deviation == 0:
return False
test_statistic = demedianed.iget(-1) / median_deviation
# Completely arbitary...triggers if the median deviation is
# 6 times bigger than the median
if test_statistic > 6:
return True
6到别的东西-
4 ,
5 ,
7等。 您也可以调整一些在设置
settings.py文件:
/opt/skyline/src/settings.py
ALGORITHMS = [
'first_hour_average',
'mean_subtraction_cumulation',
'stddev_from_average',
'stddev_from_moving_average',
'least_squares',
'grubbs',
'histogram_bins',
'median_absolute_deviation',
'ks_test',
]
CONSENSUS = 6
ALGORITHMS选项指定分析仪运行的算法。 您可以对其中任何一个进行注释,以禁用它们或添加新的算法。 该
CONSENSUS选项指定了必须返回算法的数字
True之前的指标被列为异常。要提高灵敏度,可以减少此选项,反之亦然。
结论
Skyline是很好的证明在复杂的动态变化的IT系统。对于经常对操作系统进行更改并希望在新软件版本之后快速检测系统指标中的异常的程序员可能是有用的。 其主要优点包括:- 高速分析大量数据
- 无需为每个指标设置单独的参数
- 能够添加自己的算法用于异常检测
- 通过需要大量计算系统资源的若干算法来分析每个度量的数据。
- 所有数据存储在RAM中,这使系统能够非常快速地操作。有了大量的指标和长时间的分析,你将需要大量的RAM。







