介绍
我们终于准备好为我们的生产应用程序设置设置集中日志记录。 集中日志记录是收集和可视化服务器日志的好方法。 一般来说,设置精细的日志记录系统并不像固定备份和监视设置那么重要,但在尝试识别应用程序的趋势或问题时非常有用。
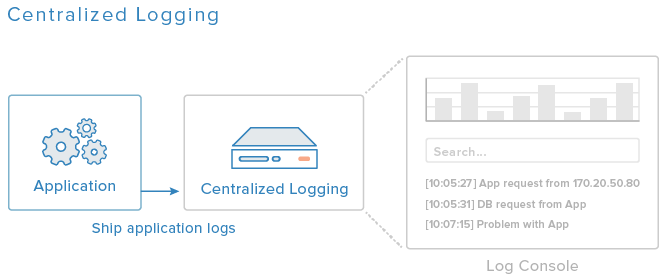
在本教程中,我们将设置一个ELK(Elasticsearch,Logstash和Kibana),并配置构成我们应用程序的服务器以将相关日志发送到日志记录服务器。 我们也将设立Logstash过滤器 ,它将分析和构建我们的日志,这将使我们能够轻松地搜索和筛选它们,并在可视化Kibana使用它们。
先决条件
如果你想通过域名访问你的日志仪表盘,创建一个记录你的站点上,像“logging.example.com”,它指向您的日志服务器的公网IP地址。 或者,您可以通过公共IP地址访问监控仪表板。 建议您将日志记录Web服务器设置为使用HTTPS,并通过将其置于VPN后限制对其的访问。
在日志服务器上安装ELK
按照本教程设置ELK你的日志服务器上: 如何在Ubuntu 14.04安装Elasticsearch,Logstash和Kibana 4 。
如果您使用的名称解析专用DNS,一定要按照方案2中生成SSL证书部分 。
当你到达设置Logstash代理部分停止。
在客户端上设置Logstash转发器
成立Logstash转发,日志发货,客户端服务器,即DB1,APP1,APP2和LB1上,遵循建立Logstash转发部分麋鹿教程。
当你完成,你应该能够通过日志服务器的公网地址登录到Kibana,并查看每台服务器的系统日志。
标识要收集的日志
根据您的确切应用程序和设置,不同的日志将可用于收集到ELK中。 在我们的示例中,我们将收集以下日志:
- MySQL缓慢查询日志(db1)
- Apache访问和错误日志(app1和app2)
- HAProxy日志(lb1)
我们选择了这些日志,因为它们可以在排除故障或尝试识别趋势时提供一些有用的信息。 您的服务器可能有您想要收集的其他日志,但这将有助于您开始。
设置MySQL日志
MySQL的慢查询日志通常位于/var/log/mysql/mysql-slow 。 它由运行时间足以被视为“慢查询”的日志组成,因此识别这些查询可以帮助您优化或排除应用程序故障。
启用MySQL慢查询日志
慢查询日志默认情况下不启用,所以让我们配置MySQL记录这些类型的查询。
打开MySQL配置文件:
sudo vi /etc/mysql/my.cnf
查找评论说:“登录慢查询”行,所以它看起来像这样取消其注释:
log_slow_queries = /var/log/mysql/mysql-slow.log
保存并退出。
我们需要重新启动MySQL以使更改生效:
sudo service mysql restart
现在MySQL会将其长时间运行的查询记录到配置中指定的日志文件中。
发送MySQL日志文件
我们必须配置Logstash转发器将MySQL缓慢查询日志发送到我们的日志记录服务器。
在数据库服务器db1上,打开Logstash Forwarder配置文件:
sudo vi /etc/logstash-forwarder.conf
在现有条目下的“文件”部分中添加以下内容,将MySQL慢查询日志作为类型“mysql-slow”发送到Logstash服务器:
,
{
"paths": [
"/var/log/mysql/mysql-slow.log"
],
"fields": { "type": "mysql-slow" }
}
保存并退出。 这将配置Logstash转发器以运送MySQL慢查询日志,并将其标记为“mysql-slow”类型日志,稍后将用于过滤。
重新启动Logstash转发器以开始发送日志:
sudo service logstash-forwarder restart
多行输入编解码器
MySQL慢查询日志是多行格式(即每个条目跨多行),因此我们必须使Logstash的多行编解码器能够处理这种类型的日志。
在ELK服务器, 日志 ,打开您的伐木工人输入定义配置文件:
sudo vi /etc/logstash/conf.d/01-lumberjack-input.conf
内的lumberjack输入定义,添加这些行:
codec => multiline {
pattern => "^# User@Host:"
negate => true
what => previous
}
保存并退出。 这将Logstash配置为在遇到包含指定模式的日志(即以“#User @ Host:”开头)时使用多行日志处理器。
接下来,我们将为MySQL日志设置Logstash过滤器。
MySQL日志过滤器
在ELK服务器, 日志 ,打开一个新的文件,以我们的MySQL日志过滤器添加到Logstash。 我们将其命名为11-mysql.conf ,所以它会在Logstash输入配置(在后读01-lumberjack-input.conf文件):
sudo vi /etc/logstash/conf.d/11-mysql.conf
添加以下过滤器定义:
filter {
# Capture user, optional host and optional ip fields
# sample log file lines:
if [type] == "mysql-slow" {
grok {
match => [ "message", "^# User@Host: %{USER:user}(?:\[[^\]]+\])?\s+@\s+%{HOST:host}?\s+\[%{IP:ip}?\]" ]
}
# Capture query time, lock time, rows returned and rows examined
grok {
match => [ "message", "^# Query_time: %{NUMBER:duration:float}\s+Lock_time: %{NUMBER:lock_wait:float} Rows_sent: %{NUMBER:results:int} \s*Rows_examined: %{NUMBER:scanned:int}"]
}
# Capture the time the query happened
grok {
match => [ "message", "^SET timestamp=%{NUMBER:timestamp};" ]
}
# Extract the time based on the time of the query and not the time the item got logged
date {
match => [ "timestamp", "UNIX" ]
}
# Drop the captured timestamp field since it has been moved to the time of the event
mutate {
remove_field => "timestamp"
}
}
}
保存并退出。 这将配置Logstash过滤mysql-slow在指定的神交模式日志类型match的指令。 在apache-access日志类型正在由默认的Apache日志消息格式相匹配的Logstash提供神交模式解析,而apache-error日志类型正在被写入到匹配的缺省错误日志格式的神交过滤器解析。
要使这些过滤器工作,让我们重新启动Logstash:
sudo service logstash restart
此时,您需要确保Logstash正常运行,因为配置错误将导致Logstash失败。
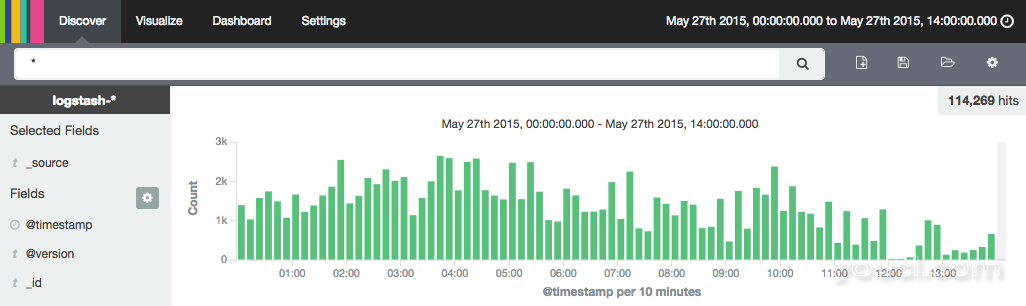
您还需要确认Kibana能够查看过滤的Apache日志。
Apache日志
Apache的日志通常位于/var/log/apache2 ,命名为“access.log的”和“error.log中”。 收集这些日志将允许您查看谁正在访问您的服务器,他们请求,以及他们正在使用哪些操作系统和Web浏览器的IP地址,以及Apache正在报告的任何错误消息。
运送Apache日志文件
我们必须配置Logstash转发器将Apache访问和错误日志发送到我们的日志记录服务器。
在应用程序服务器上,app1和app2,打开Logstash转发器配置文件:
sudo vi /etc/logstash-forwarder.conf
在现有条目下的“文件”部分中添加以下内容,将Apache日志(作为适当的类型)发送到Logstash服务器:
,
{
"paths": [
"/var/log/apache2/access.log"
],
"fields": { "type": "apache-access" }
},
{
"paths": [
"/var/log/apache2/error.log"
],
"fields": { "type": "apache-error" }
}
保存并退出。 这将配置Logstash转发器以运送Apache访问和错误日志,并将它们标记为它们各自的类型,这将用于过滤日志。
重新启动Logstash转发器以开始发送日志:
sudo service logstash-forwarder restart
现在,所有Apache日志都将有一个与HAProxy服务器的私有IP地址匹配的客户端源IP地址,因为HAProxy反向代理是从Internet访问应用程序服务器的唯一方式。 要改变这种以显示正在访问你的站点的实际用户的源IP,我们可以修改默认的Apache日志格式使用X-Forwarded-For这HAProxy的发送头。
打开Apache配置文件(apache2.conf):
sudo vi /etc/apache2/apache2.conf
找到看起来像这样的行:
[Label apache2.conf — Original "combined" LogFormat]
LogFormat "%h %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" combined
用%替换%H {X -转发,对于}我 ,所以它看起来是这样的:
[Label apache2.conf — Updated "combined" LogFormat]
LogFormat "%{X-Forwarded-For}i %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" combined
保存并退出。 这将配置Apache访问日志以包括实际用户的源IP地址,而不是HAProxy服务器的私有IP地址。
重新启动Apache以使日志更改生效:
sudo service apache2 restart
现在我们准备向Logstash添加Apache日志过滤器。
Apache日志过滤器
在ELK服务器, 日志 ,打开一个新的文件,以我们的Apache日志筛选器添加到Logstash。 我们将其命名为12-apache.conf ,所以它会在Logstash输入配置(在后读01-lumberjack-input.conf文件):
sudo vi /etc/logstash/conf.d/12-apache.conf
添加以下过滤器定义:
filter {
if [type] == "apache-access" {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
}
filter {
if [type] == "apache-error" {
grok {
match => { "message" => "\[(?<timestamp>%{DAY:day} %{MONTH:month} %{MONTHDAY} %{TIME} %{YEAR})\] \[%{DATA:severity}\] \[pid %{NUMBER:pid}\] \[client %{IPORHOST:clientip}:%{POSINT:clientport}] %{GREEDYDATA:error_message}" }
}
}
}
保存并退出。 这将配置Logstash过滤apache-access以及apache-error日志类型与在各自指定的神交模式match指令。 在apache-access日志类型正在由默认的Apache日志消息格式相匹配的Logstash提供神交模式解析,而apache-error日志类型正在被写入到匹配的缺省错误日志格式的神交过滤器解析。
要使这些过滤器工作,让我们重新启动Logstash:
sudo service logstash restart
此时,您需要确保Logstash正常运行,因为配置错误将导致Logstash失败。 您还需要确认Kibana能够查看过滤的Apache日志。
HAProxy日志
HAProxy的的日志通常位于/var/log/haproxy.log 。 收集这些日志将允许您查看谁正在访问您的负载均衡器的IP地址,他们请求,哪个应用服务器提供他们的请求以及关于连接的各种其他细节的IP地址。
发送HAProxy日志文件
我们必须配置Logstash转发器以运送HAProxy日志。
在您的服务器HAProxy的,LB1,打开Logstash转发器配置文件:
sudo vi /etc/logstash-forwarder.conf
在现有条目下的“文件”部分中添加以下内容,将类型为“haproxy-log”的HAProxy日志发送到Logstash服务器:
,
{
"paths": [
"/var/log/haproxy.log"
],
"fields": { "type": "haproxy-log" }
}
保存并退出。 这将配置Logstash代理出货,HAProxy的日志,并将它们标记为haproxy-log ,这将是用于过滤的日志。
重新启动Logstash转发器以开始发送日志:
sudo service logstash-forwarder restart
HAProxy日志过滤器
在ELK服务器, 日志 ,打开一个新的文件,我们HAProxy的日志过滤器添加到Logstash。 我们将其命名为13-haproxy.conf ,所以它会在Logstash输入配置(在后读01-lumberjack-input.conf文件):
sudo vi /etc/logstash/conf.d/13-haproxy.conf
添加以下过滤器定义:
filter {
if [type] == "haproxy-log" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:timestamp} %{HOSTNAME:hostname} %{SYSLOGPROG}: %{IPORHOST:clientip}:%{POSINT:clientport} \[%{MONTHDAY}[./-]%{MONTH}[./-]%{YEAR}:%{TIME}\] %{NOTSPACE:frontend_name} %{NOTSPACE:backend_name}/%{NOTSPACE:server_name} %{INT:time_request}/%{INT:time_queue}/%{INT:time_backend_connect}/%{INT:time_backend_response}/%{NOTSPACE:time_duration} %{INT:http_status_code} %{NOTSPACE:bytes_read} %{DATA:captured_request_cookie} %{DATA:captured_response_cookie} %{NOTSPACE:termination_state} %{INT:actconn}/%{INT:feconn}/%{INT:beconn}/%{INT:srvconn}/%{NOTSPACE:retries} %{INT:srv_queue}/%{INT:backend_queue} "(%{WORD:http_verb} %{URIPATHPARAM:http_request} HTTP/%{NUMBER:http_version})|<BADREQ>|(%{WORD:http_verb} (%{URIPROTO:http_proto}://))" }
}
}
}
保存并退出。 这将配置Logstash过滤haproxy-log ,在各自指定的神交模式日志类型match指令。 该haproxy-log日志类型正在由默认HAProxy的日志信息的格式相匹配的Logstash提供神交模式解析。
要使这些过滤器工作,让我们重新启动Logstash:
sudo service logstash restart
此时,您需要确保Logstash正常运行,因为配置错误将导致Logstash失败。
设置Kibana可视化
现在,您正在中央位置收集日志,您可以开始使用Kibana来可视化它们。 本教程可以帮助您开始使用的是: 如何使用Kibana仪表盘和可视化 。
一旦你与Kibana几分惬意,尝试本教程以可视化用户以有趣的方式: 如何映射用户位置与GeoIP的和麋鹿 。
结论
恭喜! 您已完成Production Web应用程序安装教程系列。 如果您遵循所有教程,您应该有一个看起来像我们在概述教程中描述的设置(使用私有DNS和远程备份):
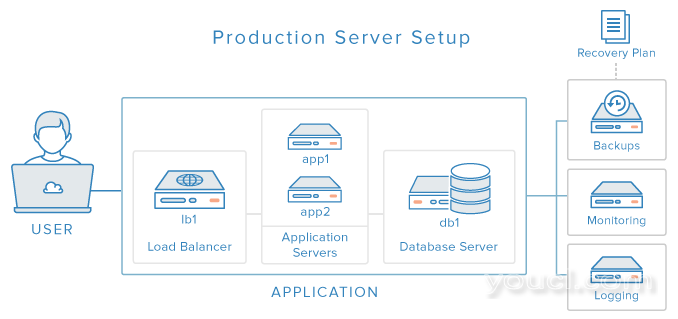
也就是说,您应该有一个具有解耦组件的工作应用程序,由备份,监视和集中式日志记录组件支持。 请务必测试您的应用程序,并确保所有组件按预期工作。







