我在以前的文章上“ 介绍GlusterFS(文件系统),并安装-第1部分 ”只是文件系统的简要概述,其优点描述了一些基本的命令。 值得一提的关于两个重要特征, 自我修复和重新平衡 ,在这篇文章中没有解释其中的GlusterFS将是没有用的。 我们熟悉的术语自我修复 和再平衡 。
我们在复制卷上的自我修复是什么意思?
此功能适用于复制卷。 假设,我们有一个复制卷[ 最小副本数2]。 假设由于一些故障,一个或多个砖在复制砖中下来一段时间,用户碰巧从安装点删除一个文件,将只受到在线砖上的影响。
当离线砖在稍后时间上线时,必须从该砖中移除该文件,也就是说,必须在被称为修复的副本砖之间进行同步。 在离线积木上创建/修改文件的情况也是如此。 GlusterFS有一个内置的self-heal守护进程,以处理这些情况时,每当砖变成在线。
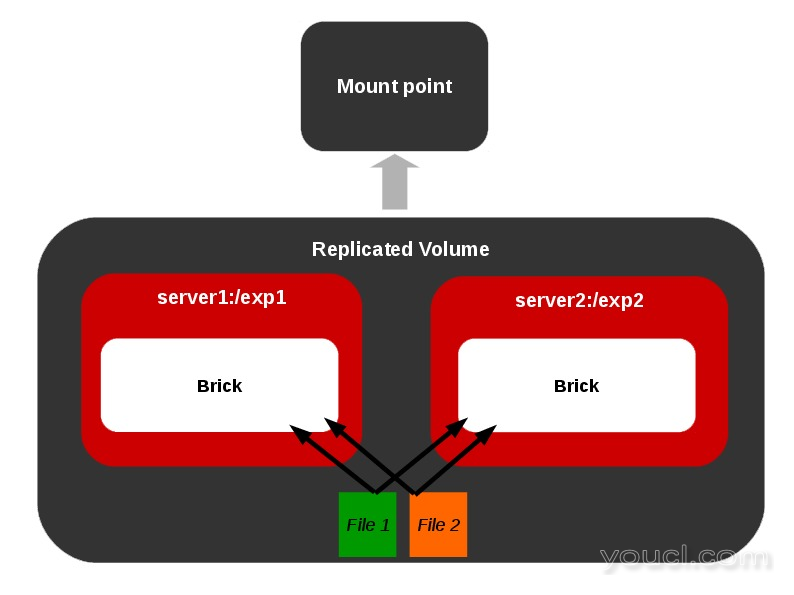
复制卷
我们的平衡是什么意思?
考虑一个只有一个砖的分布式卷。 例如,我们通过创建挂载点卷上的10个文件 。 现在所有的文件都驻留在同一个砖上,因为只有砖的体积。 在向卷添加一个砖块时,我们可能需要重新平衡两个砖块之间的文件总数。 如果在GlusterFS中扩展或缩小卷,则需要在卷中包含的各个块之间重新平衡数据。
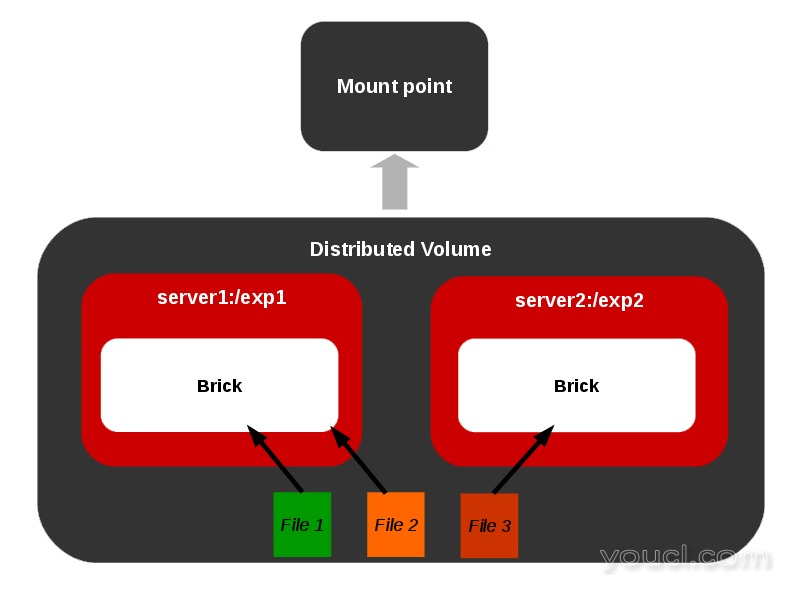
分布式卷
在GlusterFS中执行自愈
1.使用以下命令创建一个复制卷。
$ gluster volume create vol replica 2 192.168.1.16:/home/a 192.168.1.16:/home/b
注意 :用砖头在同一台服务器上复制卷的创建可以提高您拥有继续无视同样的警告。
2.启动并安装卷。
$ gluster volume start vol $ mount -t glusterfs 192.168.1.16:/vol /mnt/
3.从装载点创建文件。
$ touch /mnt/foo
4.在两个复制砖上验证相同。
$ ls /home/a/ foo $ ls /home/b/ foo
5.现在离线杀死使用PID从卷状态信息得到相应的glusterfs守护进程发送砖块之一。
$ gluster volume status vol
示例输出
Status of volume: vol Gluster process Port Online Pid ------------------------------------------------------------------------------ Brick 192.168.1.16:/home/a 49152 Y 3799 Brick 192.168.1.16:/home/b 49153 Y 3810 NFS Server on localhost 2049 Y 3824 Self-heal Daemon on localhost N/A Y 3829
注 :在服务器上看到自我修复守护进程的存在。
$ kill 3810
$ gluster volume status vol
示例输出
Status of volume: vol Gluster process Port Online Pid ------------------------------------------------------------------------------ Brick 192.168.1.16:/home/a 49152 Y 3799 Brick 192.168.1.16:/home/b N/A N N/A NFS Server on localhost 2049 Y 3824 Self-heal Daemon on localhost N/A Y 3829
现在第二块砖离线了。
6.删除从安装点的文件foo,并检查砖的内容。
$ rm -f /mnt/foo $ ls /home/a $ ls /home/b foo
你看富仍然存在第二砖。
7.现在带回砖在线。
$ gluster volume start force $ gluster volume status vol
示例输出
Status of volume: vol Gluster process Port Online Pid ------------------------------------------------------------------------------ Brick 192.168.1.16:/home/a 49152 Y 3799 Brick 192.168.1.16:/home/b 49153 Y 4110 NFS Server on localhost 2049 Y 4122 Self-heal Daemon on localhost N/A Y 4129
现在砖头在线。
8.检查砖的内容。
$ ls /home/a/ $ ls /home/b/
文件已被自愈合守护进程从第二砖删除。
注意 :在大文件的情况下,可能需要一段时间才能成功完成自我修复操作。 您可以使用以下命令检查治疗状态。
$ gluster volume heal vol info
在GlusterFS中执行重新平衡
1.创建一个分布式的体积。
$ gluster create volume distribute 192.168.1.16:/home/c
2.启动并安装卷。
$ gluster volume start distribute $ mount -t glusterfs 192.168.1.16:/distribute /mnt/
3.创建10个文件。
$ touch /mnt/file{1..10}
$ ls /mnt/
file1 file10 file2 file3 file4 file5 file6 file7 file8 file9
$ ls /home/c
file1 file10 file2 file3 file4 file5 file6 file7 file8 file9
4.添加另一块砖体积分布 。
$ gluster volume add-brick distribute 192.168.1.16:/home/d $ ls /home/d
5.做再平衡。
$ gluster volume rebalance distribute start volume rebalance: distribute: success: Starting rebalance on volume distribute has been successful.
6.检查内容。
$ ls /home/c file1 file2 file5 file6 file8 $ ls /home/d file10 file3 file4 file7 file9
文件已重新平衡。
注意 :您可以通过发出以下命令来检查再平衡的状态。
$ gluster volume rebalance distribute status
示例输出
Node Rebalanced-files size scanned failures skipped status run time in secs --------- ----------- --------- -------- --------- ------- -------- ----------------- localhost 5 0Bytes 15 0 0 completed 1.00 volume rebalance: distribute: success:
有了这个,我计划结束关于GlusterFS的这个系列。 随意评论这里与你的自我修复和重新平衡的特点的怀疑。







