介绍
Prometheus是一个开源监控系统和时间序列数据库。在
如何在Ubuntu 14.04第1部分查询Prometheus ,我们成立了三个示范服务实例揭露合成指标到Prometheus服务器。然后,我们使用这些指标,了解了如何使用Prometheus查询语言来选择和过滤时间序列,如何在维度上进行聚合,以及如何计算速率和导数。 在本教程的第二部分中,我们将从第一部分开始进行设置,并学习更高级的查询技术和模式。本教程后,您将了解如何应用基于值的过滤,设置操作,直方图等。
先决条件
本教程是基于安装中概述
了如何在Ubuntu的查询Prometheus14.04第1部分 。至少,你需要按照第1步和第2步,从该教程建立一个Prometheus服务器和三个监控演示服务实例。然而,我们还将基于第一部分中解释的查询语言技术,因此建议完全通过它。
第1步 - 按值过滤和使用阈值
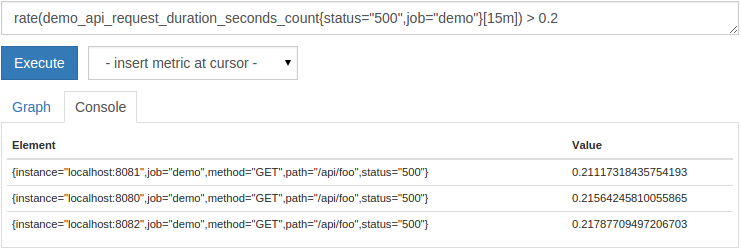
在本节中,我们将学习如何根据它们的值过滤返回的时间序列。 基于值的过滤的最常见用法是简单的数字警报阈值。 例如,我们可能希望找到具有较高的总HTTP路径
500 -status要求比0.2每秒率,平均为过去15分钟。 要做到这一点,我们只需查询所有
500 -status请求率再追加
> 0.2在表达式的末尾过滤器运算符:
rate(demo_api_request_duration_seconds_count{status="500",job="demo"}[15m]) > 0.2
在
控制台视图,其结果应该是这样的:
 然而,与二进制算术一样,Prometheus不仅支持通过单个标量数进行过滤。您还可以基于另一组系列过滤一组时间系列。同样,元素通过其标签集匹配,并且在匹配元素之间应用滤波器算子。仅从左侧上的右手侧匹配元素
并通过过滤器元件成为输出的一部分。 该
然而,与二进制算术一样,Prometheus不仅支持通过单个标量数进行过滤。您还可以基于另一组系列过滤一组时间系列。同样,元素通过其标签集匹配,并且在匹配元素之间应用滤波器算子。仅从左侧上的右手侧匹配元素
并通过过滤器元件成为输出的一部分。 该
on(<labels>)
group_left(<labels>)
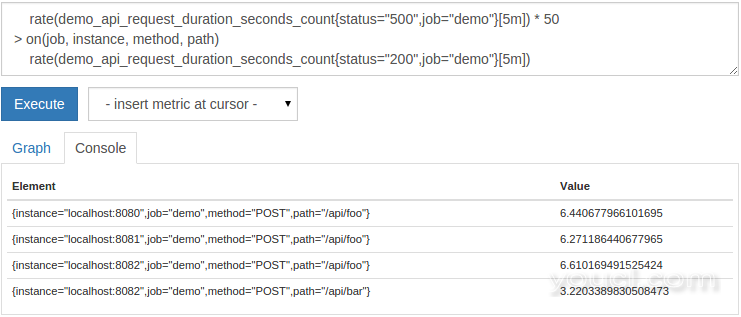
group_right(<labels>)子句的工作方式相同这里作为算术运算符。 例如,我们可以选择
500任何-status率
job ,
instance ,
method和
path的组合为其
200 -status率不高于50倍
500这样-status率:
rate(demo_api_request_duration_seconds_count{status="500",job="demo"}[5m]) * 50
> on(job, instance, method, path)
rate(demo_api_request_duration_seconds_count{status="200",job="demo"}[5m])
这将如下所示:
 此外
此外
> ,Prometheus还支持通常
>= ,
<=
< ,
!=和
==比较符用于过滤使用。 我们现在知道如何基于单个数值或基于具有匹配标签的另一组时间序列值来过滤一组时间序列。
第2步 - 使用集合运算符
在本节中,您将学习如何使用Prometheus的集合运算符来相互关联时间序列集。 通常,您想基于另一组过滤一组时间序列。对于这一点,Prometheus提供
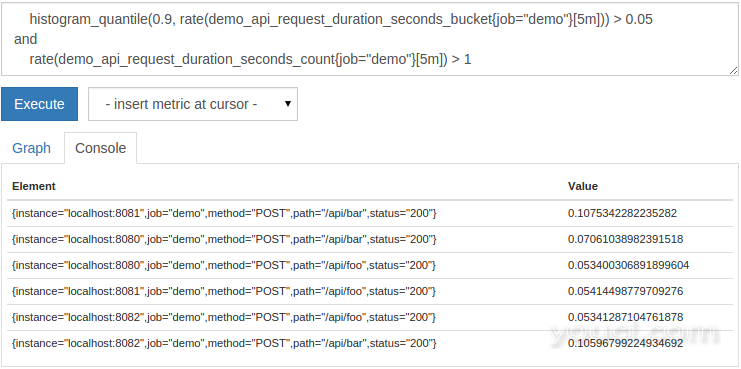
and设置运算符。对于操作员左侧的每个系列,它尝试在右侧查找具有相同标签的系列。如果找到匹配,则左侧系列成为输出的一部分。如果右侧没有匹配系列,则从输出中省略该系列。 例如,您可能需要选择第90百分位延迟高于50毫秒(0.05秒)的任何HTTP端点,但仅适用于每秒接收多个请求的维组合。我们将使用
histogram_quantile()此功能为百分制计算。我们将在下一节中解释这个函数的工作原理。现在,它只是计算每个子维度的第90百分位数延迟。要过滤生成的不良延迟并仅保留每秒接收多个请求的延迟,我们可以查询:
histogram_quantile(0.9, rate(demo_api_request_duration_seconds_bucket{job="demo"}[5m])) > 0.05
and
rate(demo_api_request_duration_seconds_count{job="demo"}[5m]) > 1
 而不是采取交集,有时你想建立从两组时间序列的联合。Prometheus提供
而不是采取交集,有时你想建立从两组时间序列的联合。Prometheus提供
or设置操作员这一点。它导致操作的左侧系列,以及右侧的任何系列,其左侧没有匹配的标签集。例如,要列出低于10或高于30的所有请求率,请查询:
rate(demo_api_request_duration_seconds_count{job="demo"}[5m]) < 10
or
rate(demo_api_request_duration_seconds_count{job="demo"}[5m]) > 30
结果将如图所示:
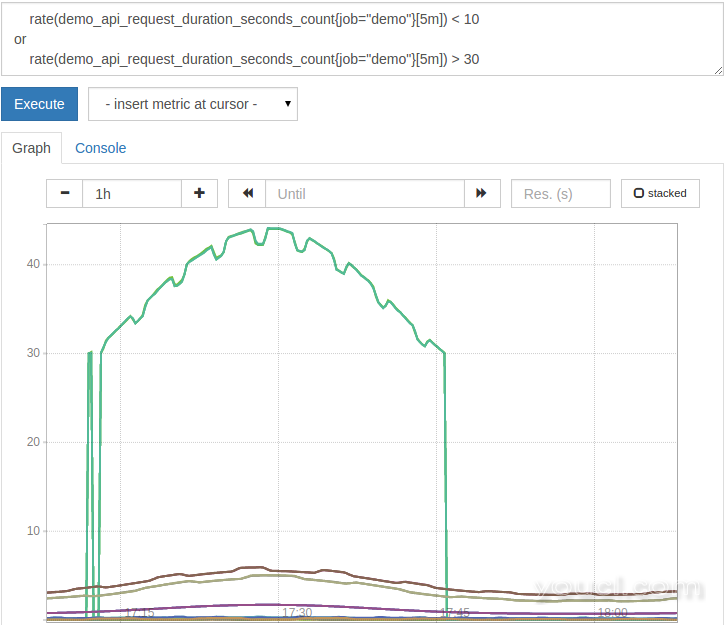 如您所见,在图表中使用值过滤器和设置操作可能会导致时间序列在同一个图形中显示和消失,具体取决于它们是否与图表上的任何时间步骤匹配过滤器。一般来说,使用这种过滤器逻辑仅推荐用于警报规则。 你现在知道如何建立交叉点和联合的标签时间序列。
如您所见,在图表中使用值过滤器和设置操作可能会导致时间序列在同一个图形中显示和消失,具体取决于它们是否与图表上的任何时间步骤匹配过滤器。一般来说,使用这种过滤器逻辑仅推荐用于警报规则。 你现在知道如何建立交叉点和联合的标签时间序列。
第3步 - 使用直方图
在本节中,我们将学习如何解释直方图度量,以及如何从中计算分位数(百分位数的一般形式)。 Prometheus支持直方图度量,这允许服务记录一系列值的分布。直方图通常跟踪测量,如请求延迟或响应大小,但可以从根本上跟踪根据一些分布在量值上波动的任何值。Prometheus直方图上的客户端
的样本数据,这意味着它们使用多个可配置的(例如,等待时间)的桶计数观察值,然后暴露这些桶作为单个的时间序列。 在内部,直方图被实现为一组时间序列,每个时间序列表示给定桶的计数(例如“10ms以下的请求”,“25ms以下的请求”,“50ms以下的请求”等等)。桶计数器是累积的,这意味着用于较大值的桶包括所有较低值桶的计数。在每个时间序列即直方图的一部分时,相应的桶是由特殊指示
le (低于或相等)的标签。这会为您已经跟踪的任何现有维度添加一个附加维度。 例如,我们的演示服务出口直方图
demo_api_request_duration_seconds_bucket ,跟踪API请求持续时间的分布。由于该直方图每个跟踪的子维度输出26个桶,所以该度量具有很多时间序列。让我们首先从一个实例中查看一种类型的请求的原始直方图:
demo_api_request_duration_seconds_bucket{instance="localhost:8080",method="POST",path="/api/bar",status="200",job="demo"}
您应该看到26系列,每个代表一个观察桶,经鉴定
le标签:
 直方图可以帮助您回答“我的多少请求需要超过100毫秒的时间来完成? (假设直方图具有配置为具有100ms边界的桶)。另一方面,你经常想回答一个相关的问题,“99%的查询完成了什么是延迟?如果你的直方图桶细粒度不够,你可以使用计算该
直方图可以帮助您回答“我的多少请求需要超过100毫秒的时间来完成? (假设直方图具有配置为具有100ms边界的桶)。另一方面,你经常想回答一个相关的问题,“99%的查询完成了什么是延迟?如果你的直方图桶细粒度不够,你可以使用计算该
histogram_quantile()函数。 此功能需要一个直方图指标(一组系列的
le斗标签)作为输入和相应的分位数输出。 在对比百分,其范围从第0到第100个百分,该目标位数规范
histogram_quantile()函数希望作为输入范围为
0至
1 (这样第90百分位数将对应于一个位数
0.9 )。 例如,我们可以尝试计算所有维度的所有时间的第90百分位数API延迟,如下所示:
# BAD!
histogram_quantile(0.9, demo_api_request_duration_seconds_bucket{job="demo"})
这不是很有用或可靠。当单个服务实例重新启动时,桶计数器重置,您通常想要查看延迟是“现在”(例如,在过去5分钟内测量),而不是在度量的整个时间。您可以通过应用实现这一
rate()函数底层直方图斗柜,这既涉及计数器复位,也只考虑增加在指定的时间窗口的每个桶的速度。 计算过去5分钟内的第90个百分位数的API延迟,如下所示:
# GOOD!
histogram_quantile(0.9, rate(demo_api_request_duration_seconds_bucket{job="demo"}[5m]))
这是更好的,将看起来像这样:
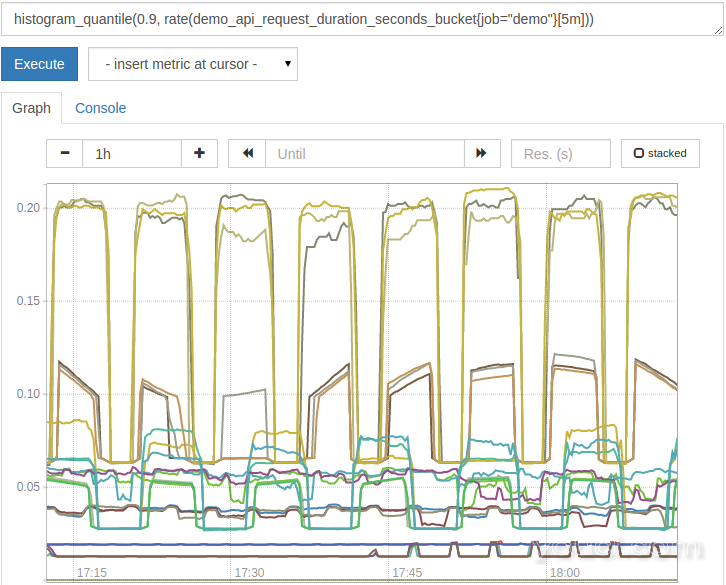 然而,这表明你对
每个子尺寸(第90百分位数
然而,这表明你对
每个子尺寸(第90百分位数
job ,
instance ,
path ,
method和
status )。 同样,我们可能不会对所有这些维度感兴趣,并希望将其中的一些聚合。 幸运的是,Prometheus的
sum集合运算符可以一起组成
histogram_quantile()函数,使我们能够在查询时间汇总了尺寸! 下面的查询计算出90个百分点的延迟,但只能通过拆分结果
job ,
instance和
path方面:
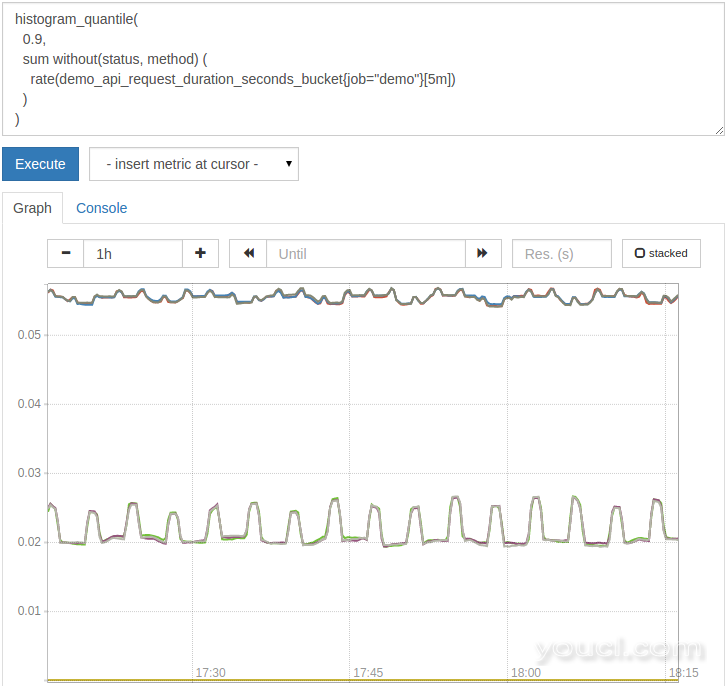
histogram_quantile(
0.9,
sum without(status, method) (
rate(demo_api_request_duration_seconds_bucket{job="demo"}[5m])
)
)
注意 :始终保持le应用之前任何聚合桶标签histogram_quantile()函数。
这确保它仍然可以对桶组进行操作并从它们计算分位数。 图表现在将如下所示:
 从直方图计算分位数总是引入一定量的统计误差。此错误取决于您的存储桶大小,观察值的分布以及要计算的目标分位数。要了解更多关于这一点,了解
位数估计错误的Prometheus文档中获得。 您现在知道如何解释直方图指标,以及如何根据不同的时间范围计算它们的分位数,同时还可以在一些维度上即时聚合。
从直方图计算分位数总是引入一定量的统计误差。此错误取决于您的存储桶大小,观察值的分布以及要计算的目标分位数。要了解更多关于这一点,了解
位数估计错误的Prometheus文档中获得。 您现在知道如何解释直方图指标,以及如何根据不同的时间范围计算它们的分位数,同时还可以在一些维度上即时聚合。
第4步 - 使用时间戳度量
在本节中,我们将学习如何利用包含时间戳的指标。 Prometheus生态系统中的组件经常暴露时间戳。例如,这可能是上次批处理作业成功完成,上次配置文件成功重新装入或机器启动时。按照惯例,时间被表示为
Unix的时间戳以秒为单位自1970年1月1日,UTC。 例如,演示服务公开了模拟批处理作业成功完成的最后时间:
demo_batch_last_success_timestamp_seconds{job="demo"}
此批处理作业被模拟为每分钟运行一次,但在所有尝试的25%中失败。在出现故障的情况下,
demo_batch_last_success_timestamp_seconds ,直到再次成功运行,则会出现指标保持其最后的值。 如果你绘制原始时间戳,它看起来会像这样:
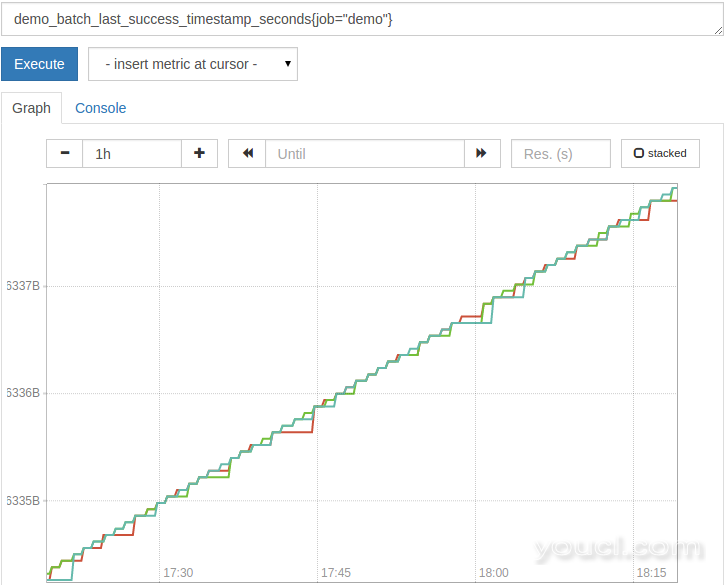 如您所见,原始时间戳值通常本身不是非常有用。相反,你经常想知道时间戳值的年龄。一个常见的模式是减去时间戳在从当前时间的度量,如通过提供
如您所见,原始时间戳值通常本身不是非常有用。相反,你经常想知道时间戳值的年龄。一个常见的模式是减去时间戳在从当前时间的度量,如通过提供
time()函数:
time() - demo_batch_last_success_timestamp_seconds{job="demo"}
这将产生自上次成功的批处理作业运行后的时间(以秒为单位):
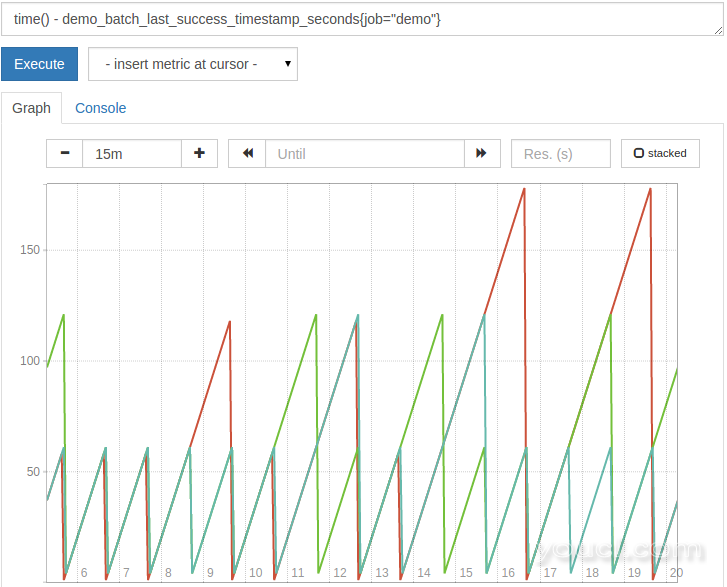 如果你想这个年龄秒转换成小时,你可以通过划分结果
如果你想这个年龄秒转换成小时,你可以通过划分结果
3600 :
(time() - demo_batch_last_success_timestamp_seconds{job="demo"}) / 3600
这样的表达式对于图形化和警报都是有用的。当可视化时间戳年龄像上面,您会收到一个锯齿图形,用线性增加线路和定期重置为
0批处理作业成功完成时。 如果锯齿尖峰太大,则表示批处理作业在很长时间内没有完成。 你也可以通过添加提醒这个
>阈值过滤器的表达和产生的时间序列警告(虽然我们将不包括在本教程的警报规则)。 要仅列出在最近1.5分钟内批处理作业尚未完成的实例,您可以运行以下查询:
time() - demo_batch_last_success_timestamp_seconds{job="demo"} > 1.5 * 60
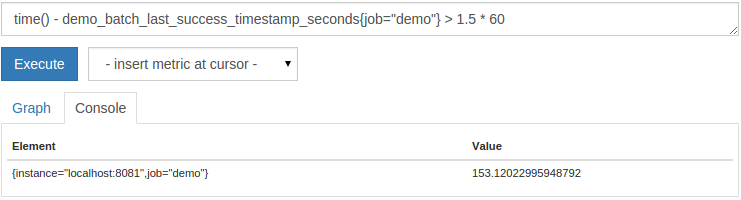 您现在知道如何将原始时间戳度量转换为相对的年龄,这对于绘图和警报都有帮助。
您现在知道如何将原始时间戳度量转换为相对的年龄,这对于绘图和警报都有帮助。
第5步 - 排序和使用topk / bottomk函数
在此步骤中,您将学习如何排序查询输出或仅选择一组系列的最大或最小值。 在表格
Console视图
中 ,它往往是有用的由自己的价值输出串联排序。 您可以通过实现这个
sort()升序排序)和
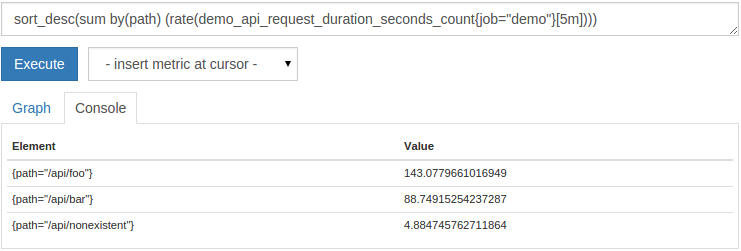
sort_desc()降序排序)功能。例如,要显示按其值(从最高到最低)排序的每路径请求率,可以查询:
sort_desc(sum by(path) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m])))
排序的输出将如下所示:
 或者你甚至不想显示所有的系列,但只有K最大或最小的系列。对于这一点,Prometheus提供
或者你甚至不想显示所有的系列,但只有K最大或最小的系列。对于这一点,Prometheus提供
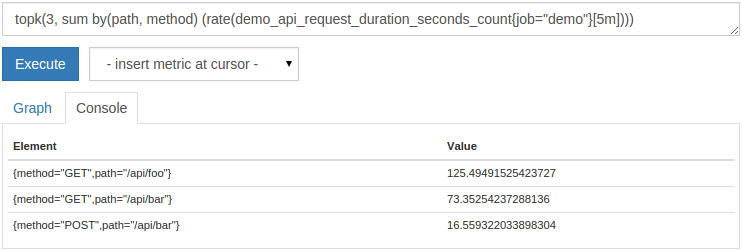
topk()和
bottomk()函数。它们各自取一个K值(要选择多少系列)和一个返回一组应该被过滤的时间系列的任意表达式。例如,要仅显示每个路径和方法的前三个请求率,您可以查询:
topk(3, sum by(path, method) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m])))
 而排序
仅在
控制台视图是有用的,
而排序
仅在
控制台视图是有用的,
topk()和
bottomk()还可以是在图有用。请注意,输出不会在整个图形时间范围内显示平均的顶部或底部K系列,而是输出将重新计算沿着图形的每个分辨率步骤的K顶部或底部输出系列。因此,您的顶部或底部K系列实际上可能在图形的范围内变化,并且您的图形可能总共显示超过K系列。 我们现在学习如何排序或只选择K个最大或最小的系列。
第6步 - 检查刮实例的健康
在这一步,我们将学习如何检查我们的实例随时间推移的健康状况。 为了使该部分更有趣,让我们终止你的三个后台演示服务实例中的第一个(监听端口8080的实例):
pkill -f -- -listen-address=:8080
当Prometheus擦伤一个目标,它会存储与度量名称合成样品
up和
job ,并
instance刮下实例的标签。 如果该刮是成功的,该样品的值被设置为
1 。 它被设置为
0 ,如果刮失败。因此,我们可以轻松地查询哪些实例当前是“向上”或“向下”:
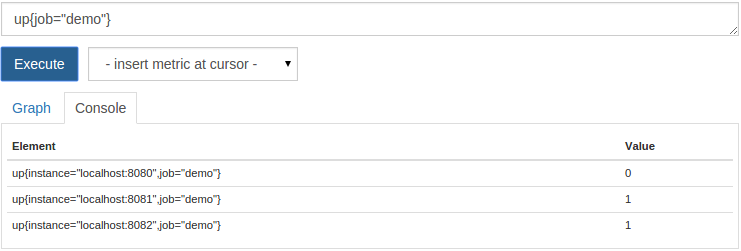
up{job="demo"}
现在应该将一个实例显示为down:
 要
仅显示下降的情况下,你可以筛选值
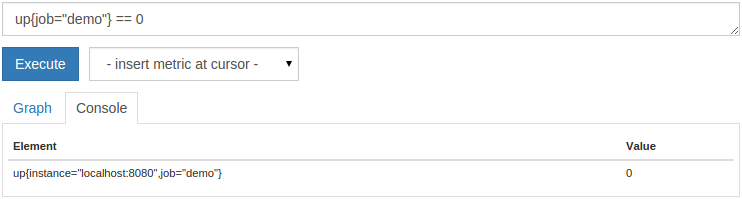
要
仅显示下降的情况下,你可以筛选值
0 :
up{job="demo"} == 0
您现在应该只看到终止的实例:
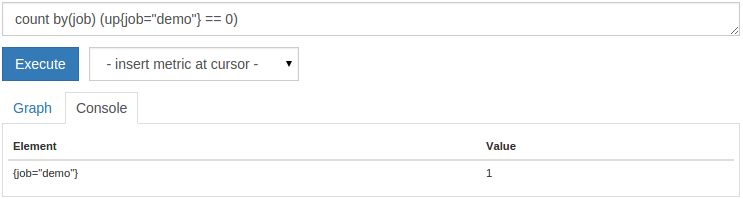
 或者,获取down实例的总数:
或者,获取down实例的总数:
count by(job) (up{job="demo"} == 0)
这将显示您的计数
1 :
 这些类型的查询对于基本的刮擦健康警报是有用的。
注 :当没有下降的情况下,该查询返回一个空的结果,而不是用的计数的单个输出一系列
这些类型的查询对于基本的刮擦健康警报是有用的。
注 :当没有下降的情况下,该查询返回一个空的结果,而不是用的计数的单个输出一系列0 。
这是因为, count()是期望的一组三维时间序列作为其输入的聚集操作者,并可以基根据一个输出系列by或without子句。
任何输出组只能基于现有的输入系列 - 如果根本没有输入系列,则不会产生输出。 您现在知道如何查询实例运行状况。
结论
在本教程中,我们建的进度
如何在Ubuntu 14.04第1部分查询Prometheus ,覆盖更先进的查询技术和模式。我们学习了如何根据它们的值过滤系列,从直方图计算分位数,处理基于时间戳的度量等等。 虽然这些教程无法涵盖所有可能的查询用例,但我们希望示例查询对您在使用Prometheus构建实际查询,仪表板和警报时非常有用。有关Prometheus的查询语言的更多详细信息,请参阅
Prometheus查询语言文档 。







