对于group by 的方式不再累赘,高级方式如下案例。
参考老师文章:http://blog.csdn.net/fu0208/article/details/7183258,向老师致敬,辛苦了
为了方便大家学习和测试,所有的例子都是在Oracle自带用户Scott下建立的。所用emp表,
如果没有此表请参考文章:http://blog.csdn.net/xiaokui_wingfly/article/details/43957003中拷贝
现在客户的需求是统计部门中每种工作的工资总额,最后还需要统计所有人的工资总数,相信这样的需求对大家来说还是比较简单的,很快就能写出SQL语句,如下:
select * from (select deptno, job, sum(sal) from emp group by deptno, job order by deptno) union all select null deptno, null job, sum(sal) from emp;
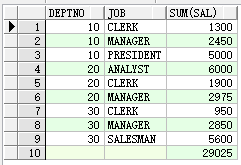
客户拍了一下脑袋瓜(当成西瓜拍了),再统计每个部门的工资数吧。tnnd,我加一个union all搞定,修改后的SQL语句如下:
----统计部门中每种工作的工资总额 , 还需要统计每个部门的工资数和统计所有人的工资总数 select * from (select deptno, job, sum(sal) from emp group by deptno, job order by deptno) union all select * from (select deptno, null job, sum(sal) from emp group by deptno order by deptno) union all select null deptno, null job, sum(sal) from emp;
其实还有一种简单的方式可以实现,如下函数 group by rollup(...)
select deptno, job, sum(sal) 工资 from emp group by rollup(deptno, job);
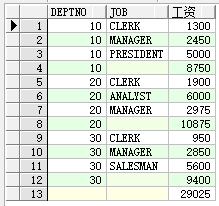
客户的需求就好像肾虚的人尿频一样(谁说客户是上帝,上帝哪来那么多的需求?),再统计每个工作类型的工资总额吧。tnnd,我再加一个union all再搞定,修改后的SQL语句如下:
----统计部门中每种工作的工资总额 , 还需要统计所有人的工资总数和统计每个部门的工资数,再统计每个工作类型的工资总额 select * from (select deptno, job, sum(sal) from emp group by deptno, job order by deptno) union all select * from (select deptno, null job, sum(sal) from emp group by deptno order by deptno) union all select null deptno, job, sum(sal) from emp group by job union all select null deptno, null job, sum(sal) from emp;
上面的方法还可以使用简单函数方法实现,修改sql如下
select grouping(job),deptno, job, sum(sal) from emp group by cube(deptno, job) order by deptno; select deptno, job, sum(sal) from emp group by cube(deptno, job) order by deptno; -- 简化上面代码
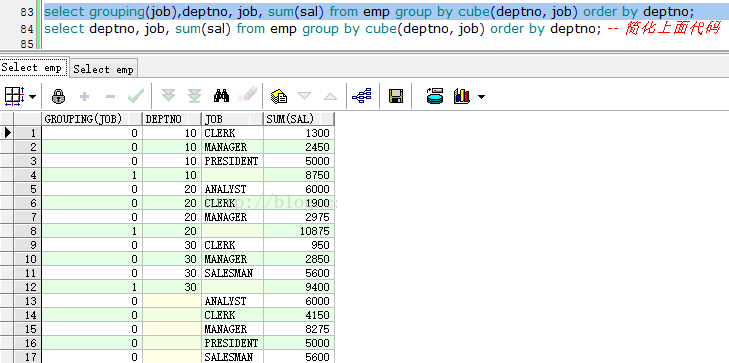
客户想了想说,只要统计部门工资总额和工作类型工资总额就可以了(我每天都徘徊在杀人和忍住不杀之间),我fucking减掉一个union all搞定,修改后的SQL语句如下:
-- 统计工作类型工资总额和部门工资总额 select null deptno, job, sum(sal) from emp group by job union all select deptno, null job, sum(sal) from emp group by deptno;
莫慌,这里还有一个大招,修改代码如下
select grouping(job), grouping_id(job), grouping(deptno), deptno, job, sum(sal) from emp group by grouping sets(deptno, job);
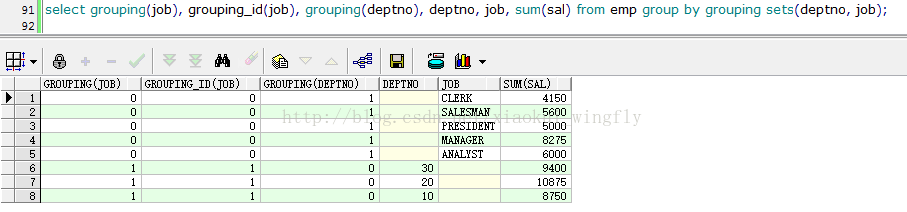
忙活半天总算把客户的需求都满足了,稍微松了一口气,不过既然学到新东西,我们有必要最后总结一下。
GROUP BY ROLLUP(A,B,C):首先对(A,B,C)进行GROUP BY,然后对(A,B)进行GROUP BY,然后是(A)进行GROUP BY, 最后对全表进行GROUP BY操作。
GROUP BY CUBE(A,B,C):首先对(A,B,C)进行GROUP BY,然后依次对(A,B)、(A,C)、(A)、(B,C)、(B)、(C)进行GROUP BY,最后对全表进行GROUP BY操作。
GROUP BY GROUPING SETS(A,B,C):依次对(C)、(B)、(A)进行GROUP BY。
对此三个函数详细使用方式参考文章:http://www.2cto.com/database/201204/127014.html







