介绍
Kubernetes是一个功能强大的容器编排系统,可以跨服务器集群管理容器化应用程序的部署和操作。 除协调容器工作负载外,Kubernetes还提供维护应用程序和服务之间可靠网络连接所需的基础结构和工具。
Kubernetes集群网络文档指出Kubernetes网络的基本要求是:
- 所有容器都可以与所有其他容器通信而无需NAT
- 所有节点都可以在没有NAT的情况下与所有容器通信(反之亦然)
- 容器看到的IP与其他人看到的IP相同
在本文中,我们将讨论Kubernetes如何满足集群中的这些网络要求:数据如何在pod内,pod之间以及节点之间移动。
我们还将展示Kubernetes 服务如何为应用程序提供单个静态IP地址和DNS条目,从而简化与可能分布在多个不断扩展和转移的容器之间的服务的通信。
如果您不熟悉Kubernetes pod和节点或其他基础知识的术语,我们的文章Kubernetes简介涵盖了所涉及的一般体系结构和组件。
我们先来看一个pod中的网络情况。
Pod网络
在Kubernetes中, pod是最基本的组织单元:一组紧密耦合的容器,它们都密切相关并执行单一功能或服务。
在网络方面,Kubernetes将pod视为类似于传统虚拟机或单个裸机主机:每个pod接收一个唯一的IP地址,并且pod中的所有容器共享该地址并通过lo loopback接口相互通信localhost主机名。 这是通过将所有pod的容器分配到同一网络来实现的。
对于在容器化之前在单个主机上部署多个服务的任何人来说,这种情况应该是熟悉的。 所有服务都需要使用唯一的端口来监听,否则通信不复杂且开销很低。
Pod到Pod网络
大多数Kubernetes集群都需要为每个节点部署多个pod。 Pod到pod通信可能发生在同一节点上的两个pod之间,或者发生在两个不同节点之间。
在一个节点上进行Pod到Pod通信
在单个节点上,您可以拥有多个需要直接相互通信的pod。 在我们跟踪pod之间的数据包路由之前,让我们检查一个节点的网络设置。 下图提供了一个概述,我们将详细介绍:
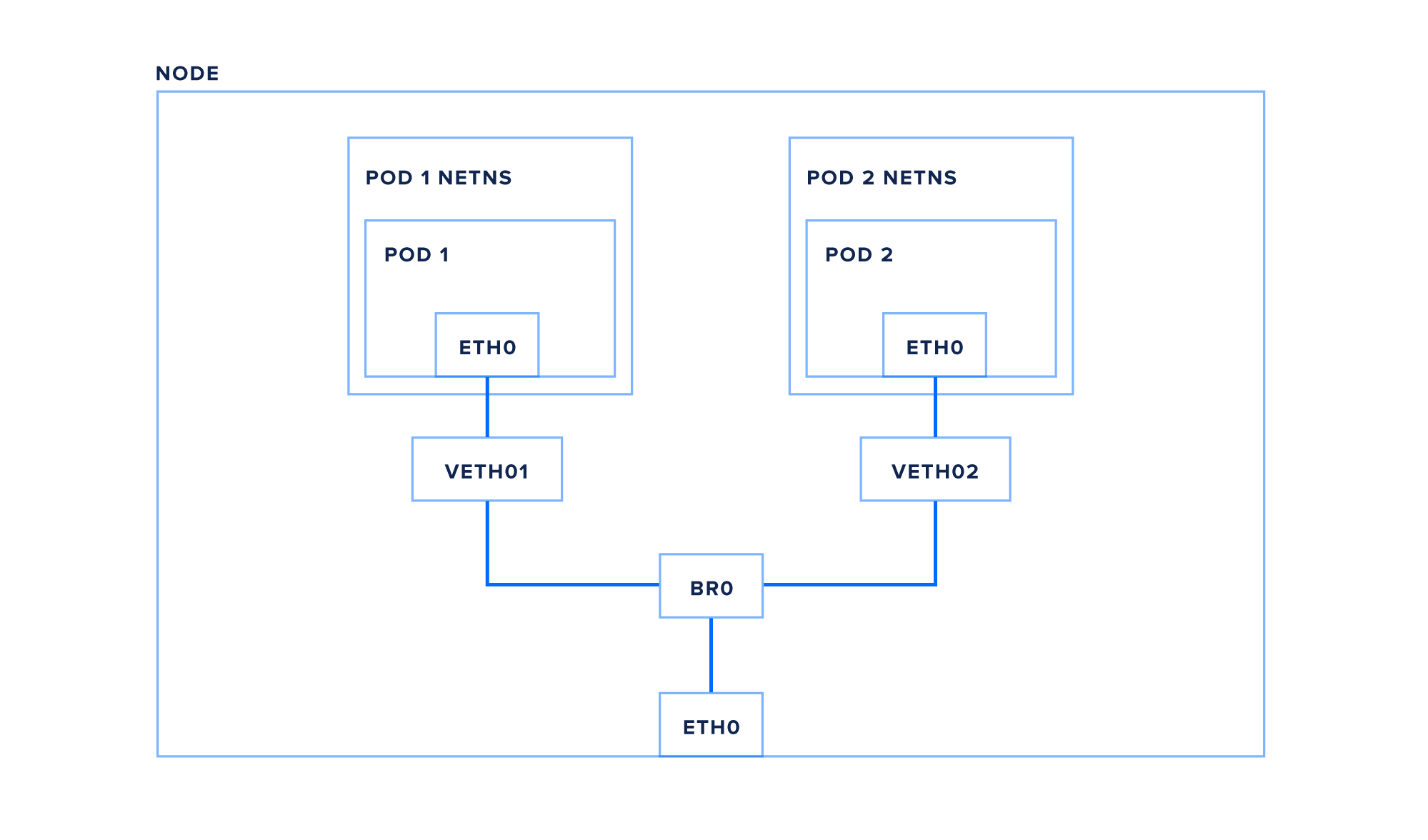
每个节点都有一个网络接口 - 本例中为eth0 - 连接到Kubernetes集群网络。 此接口位于节点的根网络命名空间内。 这是Linux上网络设备的默认命名空间。
正如进程命名空间使容器能够将运行的应用程序彼此隔离一样,网络命名空间也会隔离网络设备,例如接口和网桥。 节点上的每个pod都分配有自己的隔离网络命名空间。
Pod命名空间通过虚拟以太网对连接回根命名空间,实质上是两个命名空间之间的管道,每端都有一个接口(这里我们在根命名空间中使用veth1 ,在pod中使用eth0 )。
最后,pod通过桥接器br0 (您的节点可能使用类似cbr0或docker0之类的东西)相互连接并连接到节点的eth0接口。 桥本质上就像物理以太网交换机一样,使用ARP(地址解析协议)或基于IP的路由来查找其他本地接口以引导流量。
让我们现在跟踪从pod1到pod2的数据包:
- pod1创建一个包含pod2的IP作为其目的地的数据包
- 数据包通过虚拟以太网对传输到根网络命名空间
- 数据包继续到桥接器br0
- 由于目标pod位于同一节点上,因此网桥会将数据包发送到pod2的虚拟以太网对
- 数据包通过虚拟以太网对传输到pod2的网络命名空间和pod的eth0网络接口
现在我们已经在节点内跟踪从pod到pod的数据包,让我们看一下pod流量如何在节点之间传播。
两个节点之间的Pod到Pod通信
由于群集中的每个容器都具有唯一的IP,并且每个容器都可以直接与所有其他容器进行通信,因此在两个不同节点上的容器之间移动的数据包与之前的方案非常相似。
让我们跟踪一个从pod1到pod3的数据包,它位于不同的节点上:
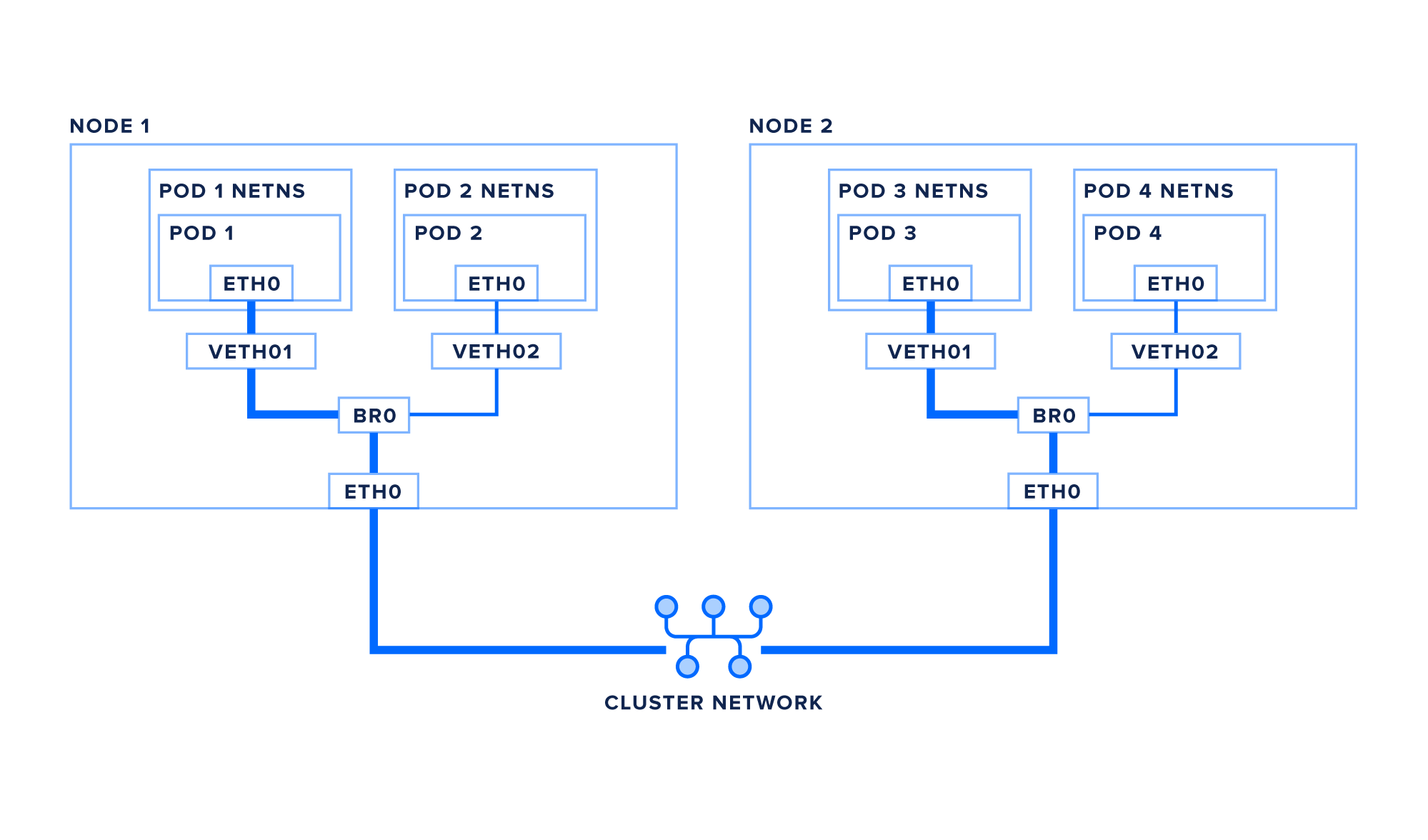
- pod1创建一个包含pod3的IP作为其目的地的数据包
- 数据包通过虚拟以太网对传输到根网络命名空间
- 数据包继续到桥接器br0
- 网桥找不到要路由到的本地接口,因此数据包将从默认路由发送到eth0
- 可选:如果您的群集需要网络覆盖以正确地将数据包路由到节点,则可以在前往网络之前将数据包封装在VXLAN数据包(或其他网络虚拟化技术)中。 或者,网络本身可以使用适当的静态路由进行设置,在这种情况下,数据包将传输到eth0并且不会改变网络。
- 数据包进入群集网络并路由到正确的节点。
- 数据包进入eth0上的目标节点
- 可选:如果您的数据包已封装,则此时将对其进行解封装
- 数据包继续到桥接器br0
- 网桥将数据包路由到目标pod的虚拟以太网对
- 数据包通过虚拟以太网对传递到pod的eth0接口
现在我们已经熟悉了如何通过pod IP地址路由数据包,让我们来看看Kubernetes 服务以及它们如何构建在这个基础架构之上。
Pod到服务网络
仅使用pod IP将流量发送到特定应用程序是很困难的,因为Kubernetes群集的动态特性意味着可以移动,重新启动,升级或缩放pod以及不存在。 此外,某些服务将有许多副本,因此我们需要一些方法来在它们之间进行负载平衡。
Kubernetes通过服务解决了这个问题。 服务是一个API对象,它将单个虚拟IP(VIP)映射到一组pod IP。 此外,Kubernetes为每个服务的名称和虚拟IP提供DNS条目,因此可以通过名称轻松解决服务问题。
群集内虚拟IP到pod IP的映射由每个节点上的kube-proxy进程协调。 此过程设置iptables或IPVS,以便在将数据包发送到群集网络之前自动将VIP转换为pod IP。 跟踪各个连接,以便数据包在返回时可以正确地解除转换。 IPVS和iptables都可以将单个服务虚拟IP负载平衡到多个pod IP中,尽管IPVS在其可以使用的负载平衡算法中具有更大的灵活性。
注意:此转换和连接跟踪过程完全在Linux内核中进行。 kube-proxy从Kubernetes API读取并更新iptables ip IPVS,但它不在单个数据包的数据路径中。 这比以前版本的kube-proxy更有效,性能更高,后者用作用户域代理。
让我们按照数据包从pod, pod1再到服务, service1的路由 :
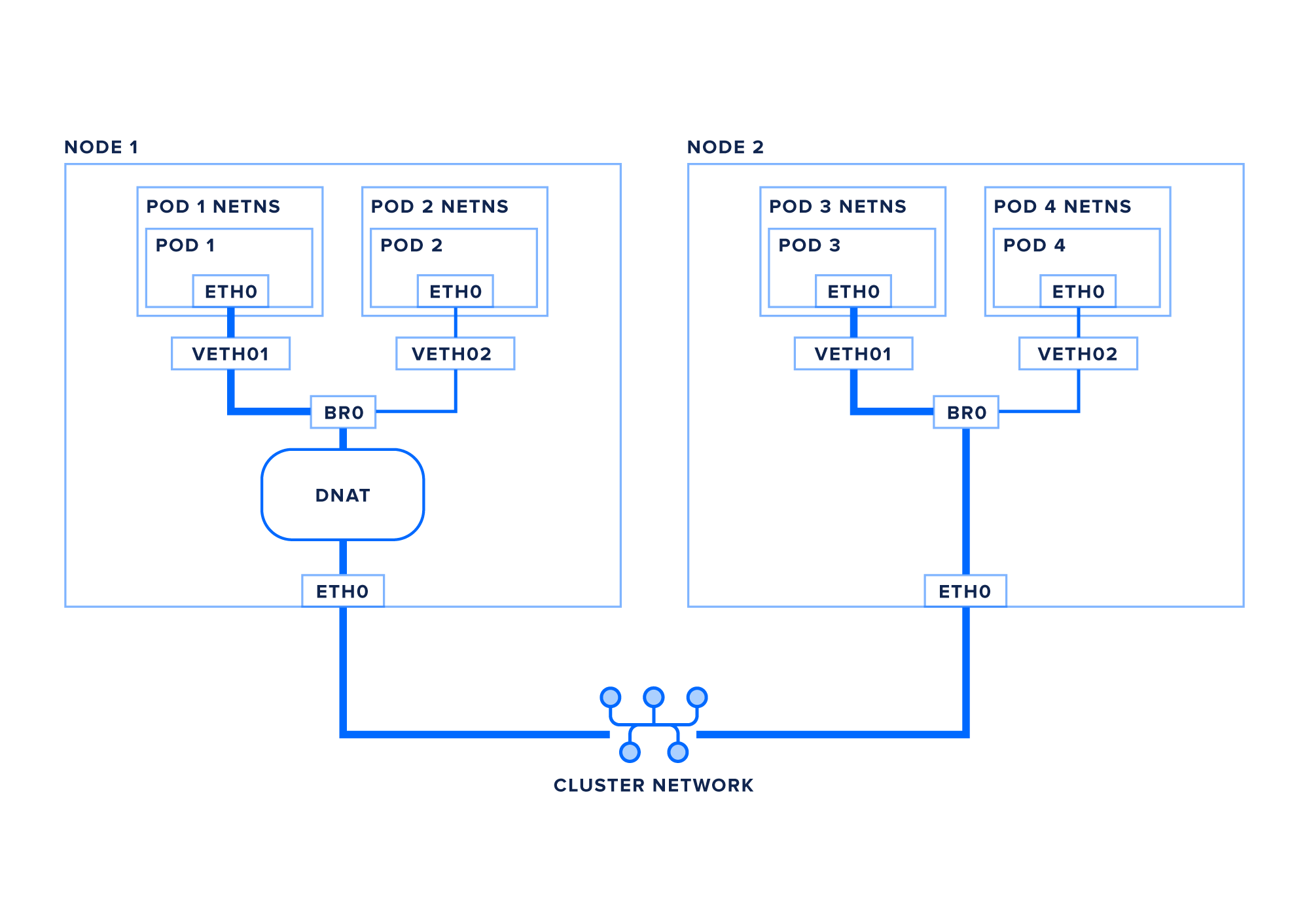
- pod1创建一个以service1的IP为目的地的数据包
- 数据包通过虚拟以太网对传输到根网络命名空间
- 数据包继续到桥接器br0
- 网桥找不到将数据包路由到的本地接口,因此数据包将从默认路由发送到eth0
- 由
kube-proxy设置的iptables或IPVS匹配数据包的目标IP,并使用任何可用或指定的负载平衡算法将其从虚拟IP转换为服务的pod IP之一 - 可选:此时可以封装您的数据包,如上一节中所述
- 数据包进入群集网络并路由到正确的节点。
- 数据包进入eth0上的目标节点
- 可选:如果您的数据包已封装,则此时将对其进行解封装
- 数据包继续到桥接器br0
- 数据包通过veth1发送到虚拟以太网对
- 数据包通过虚拟以太网对,并通过其eth0网络接口进入pod网络命名空间
当数据包返回到node1时 ,将转换VIP到pod IP转换,并且数据包将通过网桥和虚拟接口返回到正确的pod。
结论
在本文中,我们回顾了Kubernetes集群的内部网络基础架构。 我们已经讨论了构成网络的构建块,并详细介绍了不同场景下数据包的逐跳过程。
有关Kubernetes的更多信息,请查看我们的Kubernetes教程标签和官方Kubernetes文档 。







