使用Debian Lenny进行流量分析
通过使用我的网络监控设备,我们注意到MRTG中的链接总是在很大的负载下。 在这个链接上有很多不同的流量聚合,所以我们决定分析哪些数量的协议,因此累积流量所占的应用程序。
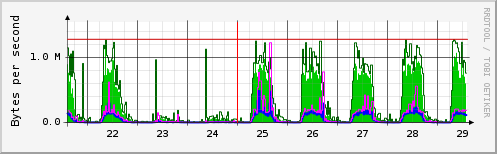
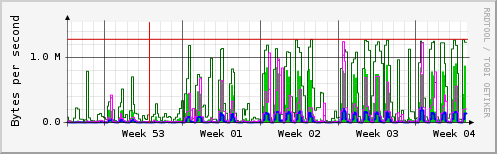
你可以很容易地看到,除了在周末和假期之外,每天都有很多交通。
一个可以做到这一点的OSS应用程序是ntop。 摘自www.ntop.org :
"ntop is a network traffic probe that shows the network usage, similar to what the popular top Unix command does. ntop is based on libpcap and it has been written in a portable way in order to virtually run on every Unix platform and on Win32 as well. ntop users can use a a web browser (e.g. netscape) to navigate through ntop (that acts as a web server) traffic information and get a dump of the network status. In the latter case, ntop can be seen as a simple RMON-like agent with an embedded web interface."
初步和免责声明
请注意,一些国家的合法权利可能会禁止在本文中提到的那些行为,不违反法定权利。 还要注意,以下收据描述了我们实施我们的解决方案的方式,我不会发出任何对您有帮助的担保。
链接
该链路具有10 MBit / s的有线速率,是位于距离几公里的两个站点之间的路由网关。 一个简短的计算,通过这个链接传输了多少数据,结果应该在〜25 GigaByte / Day的范围内。 在这一环节的一边大约有2000个系统,另一边约有200个系统,以及我们双方感兴趣的沟通关系。 后来我们注意到,每天上午7点至下午5点,每天有大约4千-50万包裹穿过这个链接。
由于ntop分析所有的流量并显示通信关系,例如在顶尖的人等的方式,我们假设ntop将使用大量的RAM来构建关于所有通信关系的表,我们认为探测器应该具有与RAM可能。
探头
我们决定使用一个旧的未使用的盒子,尽可能少的安装Debian Lenny并将其用作ntop探针。 我们只做了一个最小的安装,因为我们不想浪费X11或其他无用的应用程序的宝贵的RAM,对于这种用例是无用的。 我们决定使用Debian,因为它很容易适应我们的需求,而且它的稳定性是已知的。 但是您可以像您所熟悉的每一个其他Linux发行版一样构建一个探测器,同时* BSD也可能是一个很好的基础。
我们决定将此探头放置在处理此链接的路由器附近,并配置镜像端口以访问此链接上运行的整个流量。
由于我们需要一个NIC来进行流量捕获,因此我们配备了第二个NIC,因此希望通过SSH远程管理探测器。 第一个NIC(eth0)被配置为没有IP地址,因为它仅用于捕获来自路由器的镜像端口的流量,并且不进行任何活动通信。 此外,eth0必须进入混杂模式(以查看所有流量),这是由libpcap完成的。 仅用于远程管理的第二个NIC(eth1)配置了静态IP地址。
幸运的是,用作探头的旧盒子配备了2GB RAM(足够),AMD Athlon(tm)64处理器3800+和本地80GB光盘。 光盘是这样分配的:
# fdisk -l
Disk /dev/sda: 80.0 GB, 80026361856 bytes
255 heads, 63 sectors/track, 9729 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Disk identifier: 0x37aa37aa
Device Boot Start End Blocks Id System
/dev/sda1 1 131 1052226 83 Linux
/dev/sda2 132 162 249007+ 82 Linux swap / Solaris
/dev/sda3 163 9729 76846927+ 5 Extended
/dev/sda5 163 9729 76846896 83 Linux
/ dev / sda1是Lenny的1GB分区, / dev / sda2一个小型交换分区,和/ dev / sda5用于捕获文件。 文件系统是ext3,但xfs也可能是这种大文件的坚实候选。
3.离线报告
ntop能够快速分析流量,或者也可以读取pcap文件以供以后分析和报告。
我们决定首先使用离线方式,通过cron驱动的短shellscript从上午7点至下午5点捕获tcpdump链接上的流量,并在第二步进行分析。
shellcipt看起来像一个Sys-V initscript:
#!/bin/sh
PATH=/sbin:/usr/sbin:/bin:/usr/bin
do_start() {
ifconfig eth0 up;
tcpdump -i eth0 -w /media/capture/`date +%F_%R`_tcpdump.pcap &
}
do_stop() {
pkill -SIGTERM tcpdump;
ifconfig eth0 down;
}
case "$1" in
start)
do_start 2>&1
;;
stop)
do_stop
;;
*)
echo "Usage: $0 start|stop" >&2
exit 3
;;
esac
从上午7点到下午5点捕获流量产生大小为30GB的文件:
-rw-r--r-- 1 root root 32725662515 Jan 14 17:00 2020-01-14_07:00_tcpdump.pcap
读取一个捕获文件完成
ntop -m 10.80.192.0/18,10.81.20.0/24 -f /media/capture/2010-01-13_10\:30_tcpdump.pcap -n -4 -w3000 --w3c -p /etc/ntop/protocol.list
有关ntop的命令行开关和参数的详细说明,请查看其联机帮助页,并根据您的需要进行调整。
然后,您可以在运行ntop的系统的端口3000上检查web浏览器中的ntop报告。
4.在线报告
使用ntop的另一种可能性是,ntop本身捕获eth0上的流量,并在线报告,以便您可以在几秒钟后看到什么,并且(使用激活的rrd -plugin)可以获得非常好的,惊人的管理友好!)图,您可以用鼠标放大。
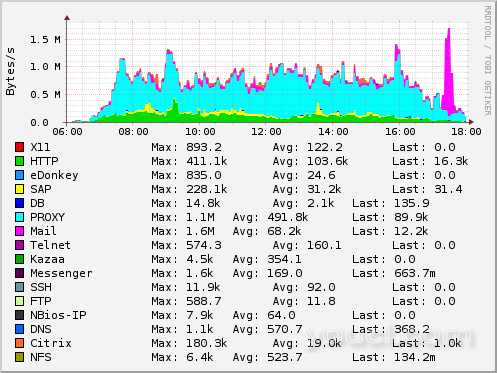
第一个结论
正如预期的那样,我们看到,大约70%的流量是由一个系统,互联网代理引起的。 与生产应用有关的流量在3-5%的范围内。 为了使情况更糟,此高效流量与交互式应用程序(如Citrix,Telnet和SAP)相关联。 我们决定下一步应该是在(例如)diffserv或TOS的帮助下对流量进行优先排序/整形。
ngrep
我们现在决定分析代理相关流量,哪些网站将是最受欢迎的流量。 对于ntop来说,这种更深入的分析是不可能的,但是通过ngrep,只能捕获到一个系统或者到一个端口的流量,或者更多的流量。 Ngrep还能够在有效载荷中搜索表达式,因此下一种方法是使用ngrep仅捕获与Internet Proxy相关的流量并对其进行分析。
这完成了
ngrep -d eth0 host 10.89.1.17 -O /media/capture/snap.pcap
不用说,这种简单的捕获也可以用tcpdump来完成。
从上午7点到下午5点完成,可以产生〜14GB的文件:
-rw-r--r-- 1 root root 14223354675 Jan 25 16:26 snap.pcap
现在这个文件必须进行分析。 这个想法是
*用tcpdump读取文件,将其转储到stdout,
* grep for“get http://”,
*剪出网站的FQDN,
*丢弃重复的条目,这是短串的(因为它们可能属于浏览器中的一次点击导致一连串的get)
*根据其发生情况对这些数据进行计数和排序。
这可以使用中间文件在几个步骤中完成,或者是一个命令,其中几个命令行工具被管道连接在一起:
tcpdump -r snap.pcap -A | grep -i "get http://" | awk '/http/ { print $2 }' | cut -d/ -f1-3 | grep http | sed '$!N; /^\(.*\)\n\1$/!P; D' | sort | uniq -c | sort -r > urls.txt
这运行一段时间后,您将按照降序的顺序排列捕获文件中发现的站点访问的文件。 我没有百分之百地确定所有我们上述做出的假设都是正确的,但文件中的数字看起来是可行的。
13418 http://www.gxxxxx.dx 10184 http://www.gxxxxx-axxxxxxxx.cxx 8281 http://www.fxxxxxxx.dx 5470 http://www.bxxx.dx 4269 http://www.sxxxxxx.dx 2550 http://www.gxxx.cxx 2047 http://www.bxxxxxxx-zxxxxxx.dx 2044 http://www.fxxxxxxx.cxx 1618 http://www.exxxxxxx.dx 1410 http://www.lx-bx.dx ....
获取关于访问网站的报告的另一种方法是解释Internet Proxy的日志文件,也许使用Calamaris (在Squid或代理生成Calamaris可处理日志的代理)中。 没有代理日志我不知道如何生成这样的报告。
最后但并非最不重要的是我们强调,在这个项目中没有对用户相关的信息进行评估。







