将Ubuntu景观与Opsview企业整合
最近,我们一直在看看今年由Mark Shuttleworth开幕的Openstack主题演讲中所述的Ubuntu工具集 - 特别感兴趣的是Ubuntu Landscape; 他们的系统和服务器管理工具,允许从单个控制台修补和管理1000个Ubuntu服务器。
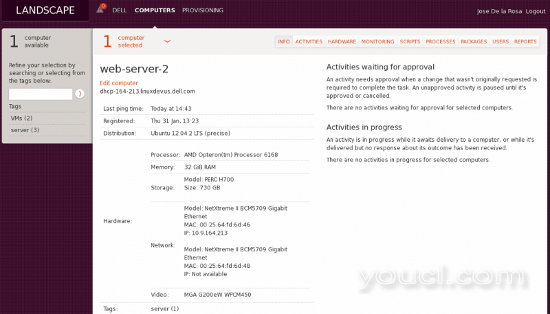
Landscape的优点是,如果您有1000个Ubuntu服务器,您可以从一个视图中随时更新软件并进行修补,甚至可以点击每个服务器获取硬件和软件清单,查看有关哪些进程的报告使用CPU等所有从一个单一的工具。
从Opsview角度来看,一个有趣的项目是它包含每个设备的“监控”选项卡。 该选项卡的基本原理是,它只显示了监控的基础知识(资源使用情况,网络吞吐量等),如下所示:
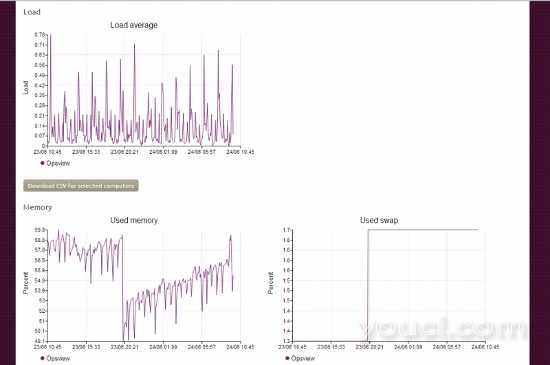
这可能是通过在Ubuntu服务器上运行的Landscape客户端吸取/查询,并使用正在解析和调用的通常的“加载”等输出。 这个细节是相当基础的,但是很多人不太可能会使用它作为监视的独立工具,而不是Opsview - 它更多的是一个有用的附件,允许您在您进入Landscpae时检查'X'的健康状况大风帆
但是,这让我们有了想法 - 如果我们仍然可以使用Opsview作为主要的监控工具,通过仪表板,电子邮件报告,发送短信提醒等方式登录,查看系统,然后将Opsview数据整合到景观信息中心 - 所以可以在Opsview中单击“Server100”,在Landscape中单击“Server100”,并查看相同的图表。 这可以让我们看到服务器的健康状况,无论我们使用哪种工具。
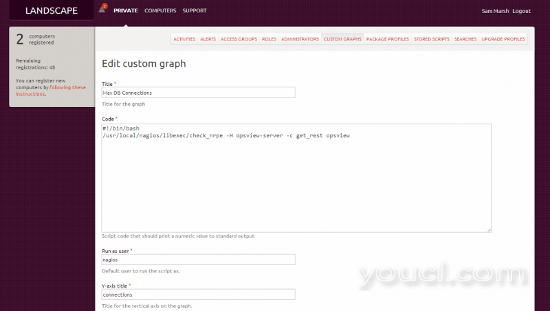
要在Landscape中做到这一点,实际上相当简单(一旦习惯了系统的细微差别)。 首先,从我们的主控台我们必须导航到“自定义图表”如下:
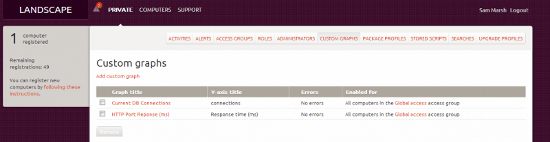
接下来,我们必须点击“添加自定义图表”,其中显示如下所示的页面(我们已经通过填充该字段节省了时间):
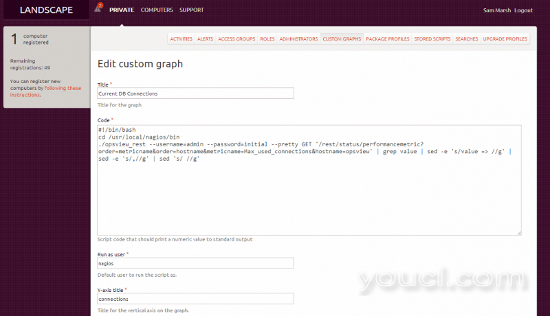
由于可能难以在图像上阅读,所以“代码”粘贴在下面:
#!/bin/bash cd /usr/local/nagios/bin ./opsview_rest --username=admin --password=initial --pretty GET '/rest/status/performancemetric?order=metricname&order=hostname&metricname=Max_used_connections&hostname=opsview' | grep value | sed -e 's/value => //g' | sed -e 's/,//g' | sed 's/ //g'
这基本上使用opsview_rest命令连接到Opsview监控系统,并从主机“opsview”获取度量“max_used_connections”,然后执行一些sedding / grepping给我们一个可绘制的值,即“28”,而不是“value => 28; 21; s ...“Ubuntu不喜欢:)
这使我们能做的是将我们的Opsview监控系统作为景观主机添加,并允许我们通过景观监视监控系统的健康状况,以及Opsview系统监控的任何其他主机的健康状况以及任何服务检查反对它。 我们可以通过运行命令获取此信息:
opsview_rest --username=admin --password=initial --pretty GET /rest/status/performancemetric/?hostname=opsview
其中“?hostname”是我们试图查看的性能数据的主机。 一旦按照上一屏幕截图进行配置和保存,我们需要设置“运行为用户:”(根或不同的用户)和“Y轴标题”(秒,数据库连接,温度等)。 一旦完成,我们点击“保存”,这将被应用到所有主机(如果你勾选了框)。
然后,一天以后,我们可以去主机并查看“监控”选项卡,看看我们的自定义图表:
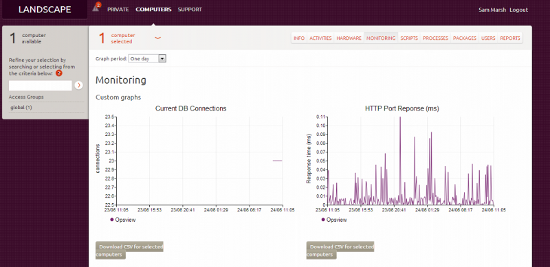
...这就是我们如何将Opsview与Ubuntu Landscape集成。
挑战
接下来面临的挑战是Landscape管理的设备运行命令:
./opsview_rest --username=admin --password=initial --pretty GET '/rest/status/performancemetric?order=metricname&order=hostname&metricname=Max_used_connections&hostname=opsview'
它通过bash使用“opsview_rest”并在本地运行。 最理想的是从任何地方(即我们在Landscape中管理的服务器)运行它,但仍然对我们的Opsview系统运行。 后者很容易 我们可以添加一个前缀如下:
./opsview_rest --url-prefix=monitoringtool.company.com --username=admin --password=initial --pretty GET '/rest/status/performancemetric?order=metricname&order=hostname&metricname=Max_used_connections&hostname=opsview'
...但是这仍然依赖于命令“opsview_rest”,这显然必须在本地框中可用,因为自定义图表在Ubuntu Landscape管理系统上本地运行脚本。 而且,这会将用户名和密码暴露给主机服务器,即您的Web服务器现在具有Opsview的登录详细信息。 但是,我们可以通过允许该角色非常具体的访问权限只读只读,只读一些特定的项目来限制后一个问题。
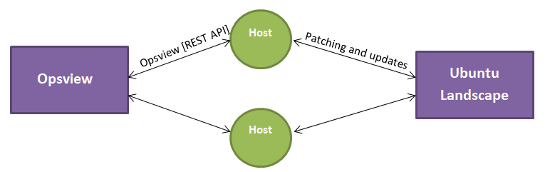
我们需要的是能够通过Opsview监视并由Ubuntu Landscape管理的主机,以便能够通过REST API查询Opsview关于其自身的健康状况,以便它可以将此信息提供给Landscape进行绘图。 但是,由于Perl问题,依赖关系等问题,我们不能分配opsview_rest,所以我们该怎么办?
似乎工作或满足我们标准的唯一项目是使用check_nrpe“非传统方式”。 我的意思是,传统上,NRPE是一个客户端程序,由Opsview查询获取信息,即“你的CPU有多忙? 磁盘有多满?“ 然后将这些值传回给Opsview,并存储用于报告,仪表板和类似设置,并用于警报。
在这个例子中我们发现,我们可以在监控/管理的主机上安装NRPE Client(Opsview Agent),并使用它来查询在Opsview主机上运行的NRPE。
在这个Opsview主机上,我们将在“/usr/local/nagios/etc/nrpe_local/overrides.cfg”中指定我们的NRPE命令(此文件不存在,您需要创建它),并添加如下行:
############################################################################ # Additional NRPE config file for Opsview ############################################################################ check_command[get_rest]=/usr/local/nagios/bin/landscape_monitor.pl $ARG1$ $ARG2$
其中“get_rest”是我们将远程调用的命令,任何“东边的equals”都是本地运行的实际命令。
您可以从上面看到,我们正在运行一些名为“landscape_monitor.pl”的东西 - 一个Perl脚本,我们写入主机参数(即$ ARG1 $可以是“server00156”或“networkswitch-X624”在Opsview中(“主机名'))。 这意味着不必为每个ie创建一个check_command:
check_command[get_rest]=/usr/local/nagios/bin/landscape_monitor.pl server1 check_command[get_rest2]=/usr/local/nagios/bin/landscape_monitor.pl server2 check_command[get_rest3]=/usr/local/nagios/bin/landscape_monitor.pl server3
我们可以使用$ ARG1 $,并且我们的Perl脚本期望它。 接下来,我们有实际的脚本(这使用JSON和IPC,所以我们需要在Opsview系统上安装以下软件包:libipc-run-perl libjson-any-perl)
#!/usr/bin/perl Shell
use strict;
use warnings;
use IPC::Run qw(run);
use JSON;
my $hostname = $ARGV[0] || '';
my $perf_metric = $ARGV[1] || '';
my @cmd = qw(/usr/local/nagios/bin/opsview_rest --username admin --password initial --data-format json GET);
push @cmd, '/rest/status/performancemetric?order=metricname&order=hostname&metricname='. $perf_metric .'&hostname='. $hostname;
run \@cmd, \undef, \my $out;
my $data = decode_json($out);
print $data->{list}->[0]->{value};
我们可以从上面看到一个变量(主机名),并添加到我们构建的opsview_rest命令中。 我们还采用性能指标,并在运行内置命令后,我们然后在我们的示例中打印JSON格式的命令输出“23”。 这样可以让我们不得不grep / sed来处理它,以获得Landscape可以使用的实际价值。
所以,一旦你把你的脚本“landscape_monitor.pl”添加到/ usr / local / nagios / bin /,并且chmod / chown'd它就可以继续创建overrides.cfg文件并添加上面的行。
最后,在监控/管理的设备上启动NRPE,我们准备好休息如下。
情景
阶段1:我们有标准的监控环境; Opsview监控“服务器A”,并询问DB统计信息,apache统计信息等信息,并通过GUI将信息显示给用户,并在出现问题时发送电子邮件/短信,警报等。
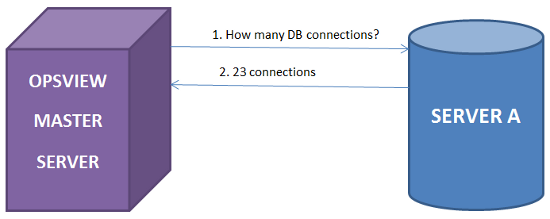
第2阶段:现在,Opsview正在从我们的服务器收集数千个指标和统计信息,我们可以使用REST API从监控的服务器(即“服务器A”)中使用上面的perl脚本查询这些统计信息。 为此,我们只需运行如下命令:
./check_nrpe -H opsview-master-server -c get_rest -a serverA Max_used_connections
ubuntu@serverA:/usr/local/nagios/libexec$ ./check_nrpe -H opsview-master-server -c get_rest -a serverA Max_used_connections
23
ubuntu@serverA:/usr/local/nagios/libexec$
通过在ServerA上使用check_nrpe并传递我们的主机名,即“ServerA”,我们可以看到Opsview为我们提供的max_db_connections值。
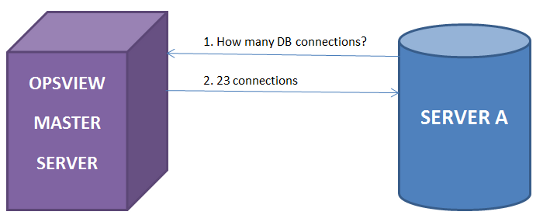
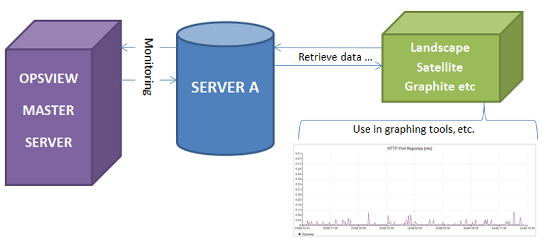
阶段3:因为我们现在有能力监控设备,要知道自己的指标 - 我们能做什么的可能性是无止境的。 在我们的例子中,我们只想使用Landscape来绘制我们的Opsview收集的指标,以便我们可以在我们的Landscape系统中查看图表“一目了然”,以及能够潜入Opsview查看报告/仪表板和更多监控具体项目。 然而,没有什么可以阻止我们使用这种技术将Opsview与其他图形工具集成在一起。
要将其与景观整合,这很简单。 我们只需要创建另一个“自定义图表”,如我们前面在文档中所述,在文本框中添加:
#!/bin/bash cd /usr/local/nagios/bin ./check_nrpe –H opsviewserver –c get_rest -a servername max_used_connections
最后,我们将这个图表应用到我们想要的一个主机上,而且我们现在正在通过Landscape监视服务器的“最大数据库连接”。 然后,我们可以在此基础上改变度量,所以本质上你可以看到所有的Opsview收集的指标,从Ubuntu Landscape,RH Satellite等。
最后的样子
所以在理论上,我们现在有以下情况:
- Ubuntu Landscape管理和修补100个Ubuntu服务器。
- Opsview Enterprise对100台Ubuntu服务器进行监控和提醒。
我们会将主机添加到Landscape和Opsview中,我们将使用Opsview来监视,警报,报告,仪表板,NetFlow等更细致的级别,然后吸引特别有趣的“一目了然”的指标风景页。
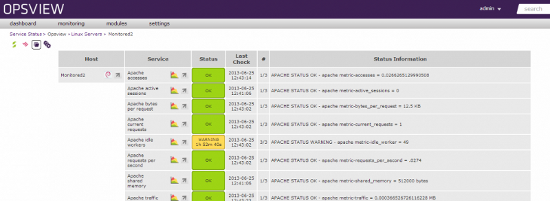
主机在Opsview
主持人如上所述添加在Opsview中 - 我们可以看到所有的指标,图表,控制监视时间,根据时间段更改指标等。
主机在风景
我们也有景观主机 - 从这个角度来看,我们可以看到资产(硬件等),更新包,查看系统运行状况的报告等。我们也可以点击“监控”,看看我们的Opsview收集“一目了然”信息,从景观内,如下:
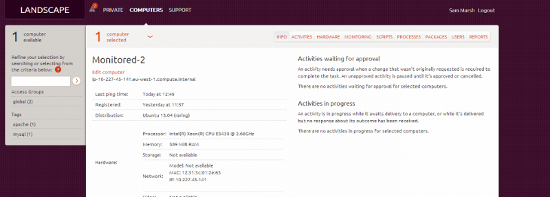
(虽然Apache Apache服务器不足啊^ ^ ^)。







