如果您是Linux命令行用户,并且您的工作涉及到使用文本文件,您应该知道(如果尚未),有许多命令行实用程序可能会在不同情况下对您有很大的帮助。 例如,存在一个名为“uniq”的工具,报告甚至删除文件中的重复行。
在这篇文章中,我们将通过简单易懂的例子来讨论'uniq'。 但在我们这样做之前,值得一提的是,本教程中提到的所有示例和说明都已在Ubuntu 16.04LTS上进行了测试。
Linux Uniq命令
如前所述,uniq命令报告或省略重复的行。 以下是此命令的一般语法:
uniq [OPTION] ... [INPUT [OUTPUT]]
根据实用程序的手册页:“从INPUT(或标准输入)中过滤相邻的匹配行,写入OUTPUT(或标准输出),没有选项,匹配行合并到第一次。
以下是一些有助于您更好地了解该工具的示例。
1.如何使用uniq命令删除重复行
假设文件包含以下行:
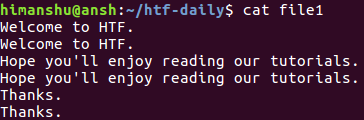
显然,每行重复。 现在让我们在这个文件上运行Uniq,看看会发生什么。
uniq file1

所以你可以看到,生成的命令的输出不包含重复的行。 请注意,原始文件 - 我们的案例中的'file1' - 不受影响。 您可以将工具的输出重定向到另一个文件,以防您想要保存并处理它。
2.如何显示每一行的重复次数
如果需要,也可以在输出中显示一行重复的次数。 这可以通过使用-c命令行选项来完成。 例如,以下命令:
uniq -c file1
产生以下输出:

所以你可以看到,每一行的重复次数在它的输出之前是前缀。
3.如何只使用uniq打印重复的行
要使uniq仅打印重复行,请使用-D命令行选项。 例如,假设file1现在在底部包含一个额外的行(请注意,此行不重复)。
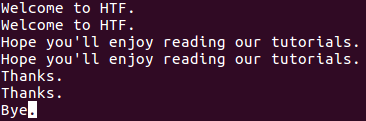
现在,当我运行以下命令:
uniq -D file1
产生以下输出:
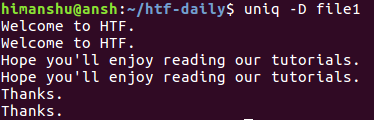
如您所见,-D选项使uniq显示输出中的所有重复行,包括所有重复的行。 为了更好地隔离,您可以在每组重复行之后有一个空行,可以使用--all-repeated选项来完成。
uniq --all-repeated[=METHOD] file1
此选项需要用户输入方法名称。 这些值可以是前面的 (添加空行)或单独的 (以追加空行)。 例如,这是使用前置方法的这个选项。
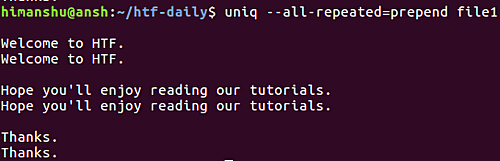
继续前进,如果您希望该工具只显示每个组中的一个重复行,则可以选择-d选项。 这是一个例子:

显然,输出中只显示了一组来自每个组的重复行。
4.如何使uniq避免比较前几个字段
有时,根据情况,两条线的相似性由这些线的一小部分定义。 例如,考虑以下文件的内容:
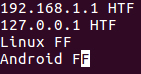
现在,假设根据第二个字段(HTF或FF),这些行被认为是相似或不同的,并且您想将其传达给uniq,那么可以使用-f命令行选项来完成。
uniq -f [number-of-fields-to-skip] [file-name]
-f选项需要传递一个数字,表示您希望跳过命令的字段数。 例如,在我们的例子中,我们可以将'1'作为参数传递给-f,因为它只是我们希望uniq跳过的第一个字段。
uniq -f 1 file1

输出清楚地表明,uniq考虑了基于它们各自的第二场重复的第一和第三行。
5.如何使uniq显示所有行,同时用空行分隔重复组
如果需要显示所有行,而用空行分隔重复的行组,则可以使用--group选项。 像我们之前讨论的 - 重复选项一样,-- group还要求你告诉空行( 前缀 , 附加或两者 )的位置。
以下是一个例子:
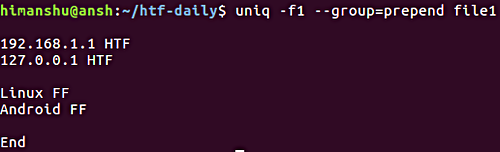
请注意,我们已在上一节中讨论过-f选项。
6.如何使uniq只打印非重复行
如你所了解的,默认情况下,uniq命令只在输出中显示重复的行。 但是,如果需要,您可以使其仅显示非重复或唯一的行。 这可以使用-u命令行选项完成。
uniq -u [file-name]
所以,在我们的情况下:
uniq -u file1
以下是一个例子:

请注意,我们已经在第4节中指出了-f选项。
7.如何使uniq避免比较初始字符的设置数
在我们之前的一个例子中,我们讨论了如何使uniq skip字段。 但是,如果需要,您也可以强制该工具跳过设定数量的初始字符。 可以使用-s命令行选项访问此功能。
uniq -s [number-of-char] filename
例如,假设该文件包含以下行:
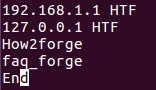
现在,如果希望uniq在比较之前跳过每行的前4个字符,则可以通过以下方式进行:
uniq -s 4 file1
以上是上述命令:
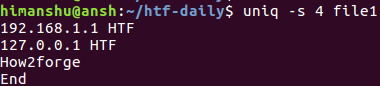
所以你可以看到原来在那里的第四行(faq_forge)在输出中被跳过了。 这是因为在跳过前四个字符之后,第三行和第四行都相同,因此被认为是由uniq重复的。
8.如何限制比较设定的字符数
与您跳过字符的方式类似,您也可以要求uniq将比较限制为一定数量的字符。 为此,您必须使用-w命令行选项。
uniq -w [num-of-chars] [file-name]
例如,假设该文件包含以下行:
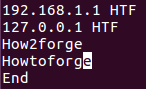
现在,如果要求比较前3个字符,那么可以通过以下方式进行:
uniq -w 3 file1
以上是上述命令:
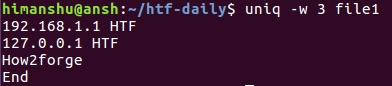
由于第三行和第四行的前3个字符相同,因此这些行被认为是重复的。 因此,输出中只显示第三个。
9.如何使uniq比较不区分大小写
默认情况下,比较uniq的执行是区分大小写的。 但是,您可以使用-i命令行选项使进程不区分大小写。
例如,考虑与上一节讨论的相同的情况,第四行以资本H,O和W开始。
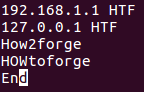
现在,如果您尝试运行与上一节中使用的相同的命令,您将看到输出不同:
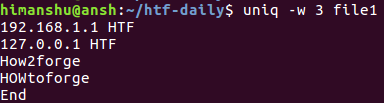
这是因为第三行和第四行的前三个字符因uniq而异。 在这些情况下,可以使用-i命令行选项对比较不区分大小写。
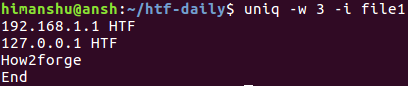
10.如何使uniq输出NUL终止
默认情况下,输出uniq生成是换行符。 但是,如果需要,可以使用NUL终止输出(在脚本中处理uniq时很有用)。 这可以使用-z命令行选项来实现。
uniq -z [file-name]
结论
我们已经覆盖了uniq命令提供的所有命令行选项,所以只需练习我们在这里讨论的任何内容,您应该了解uniq的工作原理及其提供的功能。 和往常一样,如果有任何疑问或疑问,请先执行命令的手册页 。







