介绍
MySQL集群是一种提供高可用性和吞吐量的软件技术。 如果您已经熟悉其他集群技术,您会发现MySQL集群与它们类似。 简而言之,存在控制数据节点(其中存储数据的)的一个或多个管理节点。 在咨询管理节点之后,客户端(MySQL客户端,服务器或本地API)直接连接到数据节点。
您可能想知道MySQL复制如何与MySQL集群相关。 对于集群,没有典型的数据复制,而是存在数据节点的同步。 为此,必须使用特殊的数据引擎 - NDBCluster(NDB)。 将集群视为具有冗余组件的单个逻辑MySQL环境。 因此,MySQL集群可以参与与其他MySQL集群的复制。
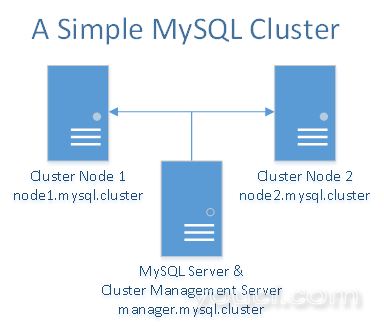
MySQL集群在无共享环境中工作最好。 理想地,没有两个组件应当共享相同的硬件。 为了简单和示范的目的,我们将限制自己只使用三个Droplet。 将有两个作为数据节点的Droplet,它们在它们之间同步数据。 第三个Droplet将用于集群管理器,同时用于MySQL服务器/客户端。 如果你有更多的Droplets,你可以添加更多的数据节点,将集群管理器与MySQL服务器/客户端分离,甚至添加更多的Droplet作为集群管理器和MySQL服务器/客户端。
先决条件
您将需要总共三个Droplet - 一个Droplet为MySQL集群管理器和MySQL服务器/客户端和两个Droplet为冗余MySQL数据节点。
在同DigitalOcean的数据中心 ,创建启用专用网络下列Droplet:
- 三Ubuntu的16.04Droplet用最少的1 GB RAM和专用网络启用
- 使用sudo权限的每个Droplet非root用户( 与Ubuntu 16.04初始服务器设置介绍了如何设置起来。)
MySQL集群在RAM中存储了大量信息。 每个Droplet应该至少有1GB的RAM。
正如提到的专用网络教程 ,一定要在3Droplet设置的自定义记录。 为了简单和方便起见,我们将使用下面的自定义记录在每个Droplet/etc/hosts文件:
10.XXX.XX.X node1.mysql.cluster
10.YYY.YY.Y node2.mysql.cluster
10.ZZZ.ZZ.Z manager.mysql.cluster
请将突出显示的IP替换为您的Droplet的专用IP。
除非另有说明,本教程中需要root权限的所有命令都应以具有sudo权限的非root用户身份运行。
第1步 - 下载和安装MySQL集群
在编写本教程的时候,MySQL集群的最新GPL版本是7.4.11。 该产品构建在MySQL 5.6之上,它包括:
- 集群管理器软件
- 数据节点管理器软件
- MySQL 5.6服务器和客户端二进制文件
您可以下载免费的,一般可用(GA)的MySQL集群从发布正式的MySQL集群下载页面 。 从这个页面,选择Debian Linux平台包,这也适用于Ubuntu。 还要确保选择32位或64位版本,具体取决于您的Droplet的体系结构。 将安装包上传到每个Droplet。
所有Droplet的安装说明相同,因此请在所有3个Droplet上完成这些步骤。
在你开始安装, libaio1必须安装软件包,因为它是一个依赖:
sudo apt-get install libaio1
之后,安装MySQL集群包:
sudo dpkg -i mysql-cluster-gpl-7.4.11-debian7-x86_64.deb
现在,你可以在目录中查找MySQL的群集安装/opt/mysql/server-5.6/ 。 我们将特别bin目录(合作/opt/mysql/server-5.6/bin/ ),所有的二进制文件。
应该对所有三个Droplet执行相同的安装步骤,而不管每个将具有不同的功能 - 管理器或数据节点。
接下来,我们将在每个Droplet上配置MySQL集群管理器。
第2步 - 配置和启动集群管理器
在这一步中,我们将配置MySQL集群管理器( manager.mysql.cluster )。 其正确的配置将确保数据节点之间的正确同步和负载分布。 所有的命令都应该在Droplet被执行manager.mysql.cluster 。
集群管理器是必须在任何集群中启动的第一个组件。 它需要一个配置文件作为参数传递到它的二进制文件。 为方便起见,我们将使用文件/var/lib/mysql-cluster/config.ini其配置。
在manager.mysql.clusterDroplet,首先创建这个文件将驻留(目录/var/lib/mysql-cluster ):
sudo mkdir /var/lib/mysql-cluster
然后创建一个文件并开始用nano编辑它:
sudo nano /var/lib/mysql-cluster/config.ini
此文件应包含以下代码:
[ndb_mgmd]
# Management process options:
hostname=manager.mysql.cluster # Hostname of the manager
datadir=/var/lib/mysql-cluster # Directory for the log files
[ndbd]
hostname=node1.mysql.cluster # Hostname of the first data node
datadir=/usr/local/mysql/data # Remote directory for the data files
[ndbd]
hostname=node2.mysql.cluster # Hostname of the second data node
datadir=/usr/local/mysql/data # Remote directory for the data files
[mysqld]
# SQL node options:
hostname=manager.mysql.cluster # In our case the MySQL server/client is on the same Droplet as the cluster manager
对上述各成分的我们已经定义了一个hostname的参数。 这是一个重要的安全措施,因为只有指定的主机名将被允许连接到管理器并按照其指定的角色加入集群。
此外, hostname参数上的服务将运行该界面中指定。 这一点很重要,而且是安全很重要,因为在我们的情况下,上述的主机名指向这是我们在指定私有地址/etc/hosts的文件。 因此,您不能从专用网络外部访问任何上述服务。
在上述文件中,您可以通过以完全相同的方式定义其他实例来添加更多冗余组件,如数据节点(ndbd)或MySQL服务器(mysqld)。
现在,您可以通过执行启动首次经理ndb_mgmd二进制文件,并指定与配置文件-f这样的说法:
sudo /opt/mysql/server-5.6/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.ini
您应该看到一条关于成功启动的消息,类似于此:
Output of ndb_mgmdMySQL Cluster Management Server mysql-5.6.29 ndb-7.4.11
您可能希望使用服务器自动启动管理服务。 GA群集版本没有合适的启动脚本,但有几个在线。 对于一开始你只需要添加启动命令到/etc/rc.local文件和服务将在启动时自动启动。 不过,首先你必须确保/etc/rc.local在服务器启动过程中被执行。 在Ubuntu 16.04中,这需要运行一个附加命令:
sudo systemctl enable rc-local.service
然后打开该文件/etc/rc.local进行编辑:
sudo nano /etc/rc.local
在那里,前添加启动命令exit这样一行:
...
/opt/mysql/server-5.6/bin/ndb_mgmd -f /var/lib/mysql-cluster/config.ini
exit 0
保存并退出文件。
集群管理器不必一直运行。 可以在不停机的情况下启动,停止和重新启动集群。 仅在群集节点和MySQL服务器/客户端的初始启动期间需要。
第3步 - 配置和启动数据节点
下一步,我们将配置数据节点( node1.mysql.cluster和node2.mysql.cluster )来存储数据文件,支持正确的NDB引擎。 所有命令都应在两个节点上执行。 您可以先启动node1.mysql.cluster ,然后重复完全相同的相同的步骤node2.mysql.cluster 。
数据节点读取从标准MySQL配置文件中的配置/etc/my.cnf的行之后,更具体的部分[mysql_cluster] 使用nano创建此文件并开始编辑它:
sudo nano /etc/my.cnf
像这样指定管理器的主机名:
[mysql_cluster]
ndb-connectstring=manager.mysql.cluster
保存并退出文件。
指定管理器的位置是节点引擎启动所需的唯一配置。 其余的配置将直接从管理器。 在我们的例子中,数据节点会发现,它的数据目录是/usr/local/mysql/data按经理的配置。 必须在节点上创建此目录。 你可以使用命令:
sudo mkdir -p /usr/local/mysql/data
之后,您可以使用以下命令第一次启动数据节点:
sudo /opt/mysql/server-5.6/bin/ndbd
成功启动后,您应该会看到类似的输出:
Output of ndbd2016-05-11 16:12:23 [ndbd] INFO -- Angel connected to 'manager.mysql.cluster:1186'
2016-05-11 16:12:23 [ndbd] INFO -- Angel allocated nodeid: 2
您应该使用服务器自动启动ndbd服务。 GA集群发行版没有适当的启动脚本。 正如我们所做的群集管理器,让我们的启动命令添加到/etc/rc.local文件。 同样,你将不得不确保/etc/rc.local的命令服务器启动过程中执行:
sudo systemctl enable rc-local.service
然后打开该文件/etc/rc.local进行编辑:
sudo nano /etc/rc.local
在之前添加启动命令exit这样一行:
...
/opt/mysql/server-5.6/bin/ndbd
exit 0
保存并退出文件。
一旦与所述第一节点完成,重复完全相同的其他节点,该节点是在相同的步骤node2.mysql.cluster在我们的例子。
第4步 - 配置和启动MySQL服务器和客户端
一个标准的MySQL服务器,例如在Ubuntu的默认apt存储库中可用的服务器,不支持MySQL集群引擎NDB。 这就是为什么你需要一个自定义MySQL服务器安装。 我们已经在三个Droplet上安装的集群包也有一个MySQL服务器和一个客户端。 如前所述,我们将使用MySQL的服务器和客户端管理节点(在manager.mysql.cluster )。
配置被再次存储默认/etc/my.cnf文件。 在manager.mysql.cluster ,打开配置文件:
sudo nano /etc/my.cnf
然后添加以下内容:
[mysqld]
ndbcluster # run NDB storage engine
...
保存并退出文件。
按照最佳做法,MySQL服务器应该在自己的用户(运行mysql ),这属于它自己的组(再次mysql )。 所以让我们先创建组:
sudo groupadd mysql
然后创建mysql属于这个组的用户,并确保它不会被它的外壳路径设置使用的shell /bin/false像这样:
sudo useradd -r -g mysql -s /bin/false mysql
自定义MySQL服务器安装的最后一个要求是创建默认数据库。 你可以使用命令:
sudo /opt/mysql/server-5.6/scripts/mysql_install_db --user=mysql
为了启动MySQL服务器,我们将使用从启动脚本/opt/mysql/server-5.6/support-files/mysql.server 。 它复制到名下的默认启动脚本目录mysqld是这样的:
sudo cp /opt/mysql/server-5.6/support-files/mysql.server /etc/init.d/mysqld
启用启动脚本,并使用以下命令将其添加到默认运行级别:
sudo systemctl enable mysqld.service
现在我们可以使用命令手动启动MySQL服务器:
sudo systemctl start mysqld
作为MySQL客户端,我们将再次使用集群安装附带的自定义二进制。 它具有以下路径: /opt/mysql/server-5.6/bin/mysql 。 为方便起见,我们将创建默认的符号链接它/usr/bin的路径:
sudo ln -s /opt/mysql/server-5.6/bin/mysql /usr/bin/
现在,你可以通过简单地键入以下命令启动命令行客户端mysql是这样的:
mysql
您应该看到类似于以下内容的输出:
Output of ndb_mgmdWelcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.6.29-ndb-7.4.11-cluster-gpl MySQL Cluster Community Server (GPL)
要退出MySQL提示,只需键入quit或同时按下CTRL-D
上面是第一个检查,以显示MySQL集群,服务器和客户端都工作。 接下来,我们将通过更详细的测试来确认集群是否正常工作。
测试集群
在这一点上,我们的简单MySQL集群应该完成一个客户端,一个服务器,一个管理器和两个数据节点。 从集群管理器Droplet( manager.mysql.cluster )打开的命令管理控制台:
sudo /opt/mysql/server-5.6/bin/ndb_mgm
现在提示应该更改到集群管理控制台。 它看起来像这样:
Inside the ndb_mgm console-- NDB Cluster -- Management Client --
ndb_mgm>
一旦控制台中执行命令SHOW是这样的:
SHOW
你应该看到类似下面的输出:
Output of ndb_mgmConnected to Management Server at: manager.mysql.cluster:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=2 @10.135.27.42 (mysql-5.6.29 ndb-7.4.11, Nodegroup: 0, *)
id=3 @10.135.27.43 (mysql-5.6.29 ndb-7.4.11, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @10.135.27.51 (mysql-5.6.29 ndb-7.4.11)
[mysqld(API)] 1 node(s)
id=4 @10.135.27.51 (mysql-5.6.29 ndb-7.4.11)
上面显示了有两个ids 2和3的数据节点。它们是活动的和连接的。 也有ID为1和ID 4.您可以找到有关通过使用命令键入编号每个ID的更多信息的一个MySQL服务器一个管理节点STATUS是这样的:
2 STATUS
上述命令将显示节点2及其MySQL和NDB版本的状态:
Output of ndb_mgmNode 2: started (mysql-5.6.29 ndb-7.4.11)
要退出管理控制台类型quit 。
管理控制台非常强大,并为您提供了管理集群及其数据的许多其他选项,包括创建在线备份。 欲了解更多信息,查看官方文档 。
现在让我们使用MySQL客户端进行测试。 从Droplet的同时,开始与客户端mysql为MySQL的root用户命令。 请记住,我们早前创建了一个符号链接。
mysql -u root
\您的控制台将更改为MySQL客户端控制台。 一旦进入MySQL客户端,运行命令:
SHOW ENGINE NDB STATUS \G
现在您应该看到有关NDB群集引擎的所有信息,从连接详细信息开始:
Output of mysql
*************************** 1. row ***************************
Type: ndbcluster
Name: connection
Status: cluster_node_id=4, connected_host=manager.mysql.cluster, connected_port=1186, number_of_data_nodes=2, number_of_ready_data_nodes=2, connect_count=0
...
从上面的最重要的信息是就绪节点的数量 - 2.这种冗余将允许您的MySQL集群继续操作,即使一个数据节点失败。 同时,您的SQL查询将被负载平衡到两个节点。
您可以尝试关闭其中一个数据节点以测试集群稳定性。 最简单的事情就是重新启动整个Droplet,以便对恢复过程进行完整测试。 你会看到的价值number_of_ready_data_nodes更改为1 ,并回到2作为节点重新启动一次。
使用NDB引擎
为了看看集群是如何工作的,让我们使用NDB引擎创建一个新表,并在其中插入一些数据。 请注意,为了使用集群功能,引擎必须是NDB。 如果使用InnoDB(默认)或除NDB之外的任何其他引擎,则不会使用群集。
首先,让我们创建一个名为数据库cluster的命令:
CREATE DATABASE cluster;
接下来,切换到新数据库:
USE cluster;
现在,创建一个名为简单的表cluster_test是这样的:
CREATE TABLE cluster_test (name VARCHAR(20), value VARCHAR(20)) ENGINE=ndbcluster;
我们已经在发动机以上明确指定ndbcluster为了利用集群。 接下来,我们可以开始用这样的查询插入数据:
INSERT INTO cluster_test (name,value) VALUES('some_name','some_value');
要验证数据是否已插入,请运行如下所示的选择查询:
SELECT * FROM cluster_test;
当插入和选择这样的数据时,您将在所有可用的数据节点之间负载平衡查询,这在我们的示例中是两个。 随着这种向外扩展,您在稳定性和性能方面都受益匪浅。
结论
正如我们在本文中所看到的,设置MySQL集群可以简单和容易。 当然,还有许多更先进的选项和功能,在将集群带到生产环境之前是值得掌握的。 一如往常,确保有足够的测试过程,因为一些问题可能很难解决。 欲了解更多信息,并进一步阅读,请去作的官方文档的MySQL集群 。








