ElasticSearch是灵活的、功能强大的开源分布式实时搜索和分析引擎。使用一个简单的API集,它提供了全文搜索的能力。弹性搜索免费提供Apache 2许可,它提供了很大的灵活性。
 本文将帮助你在CentOS,RHEL,Ubuntu和Debian系统配置ElasticSearch多节点群集。在ElasticSearch多节点群集配置只在同一个网络同一个集群名称的多个单节点集群。
本文将帮助你在CentOS,RHEL,Ubuntu和Debian系统配置ElasticSearch多节点群集。在ElasticSearch多节点群集配置只在同一个网络同一个集群名称的多个单节点集群。
网络情况
我们有三个服务器以下IPS和主机名。所有服务器在同一个局域网上运行,并使用IP和主机都已经完全进入对方的服务器。
192.168.10.101 NODE_1
192.168.10.102 NODE_2
192.168.10.103 NODE_3
验证Java(所有节点)
Java是用于安装ElasticSearch的主要要求。因此,请确保你已经在所有节点上安装了Java。
# java -version
java version "1.8.0_31"
Java(TM) SE Runtime Environment (build 1.8.0_31-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.31-b07, mixed mode)
如果你的任何节点系统上没有安装Java,使用下面的一个环节先安装它。
在CentOS / RHEL 7/6/5安装Java 8
在Ubuntu上安装Java 8
下载ElasticSearch(所有节点)
现在下载从它的所有节点系统的最新ElasticSearch存档
官方下载页面 。在这篇文章中ElasticSearch 1.4.2版本最后一次更新的时间是最新的版本可供下载。使用以下命令下载ElasticSearch 1.4.2。
$ wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.2.tar.gz
现在,提取文件对所有节点系统ElasticSearch。
$ tar xzf elasticsearch-1.4.2.tar.gz
配置ElasticSearch
现在,我们需要设置ElasticSearch上的所有节点的系统。 ElasticSearch使用“elasticsearch“作为默认群集名称。我们建议改变它,根据你的命名。
$ mv elasticsearch-1.4.2 /usr/share/elasticsearch
$ cd /usr/share/elasticsearch
要更改的每个节点和更新下列值集群命名,编辑
config/elasticsearch.yml 文件。节点名称是动态生成的,但为了保持一个固定的用户友好的名称更改它。
在NODE_1上
编辑在NODE_1(192.168.10.101)系统elasticsearch群集配置。
$ vim config/elasticsearch.yml
cluster.name: youclCluster
node.name: "NODE_1"
在NODE_2上
编辑在NODE_2(192.168.10.102)系统elasticsearch群集配置。
$ vim config/elasticsearch.yml
cluster.name: youclCluster
node.name: "NODE_2"
在Node_3上
编辑Node_3上(192.168.10.103)系统elasticsearch群集配置。
$ vim config/elasticsearch.yml
cluster.name: youclCluster
node.name: "NODE_3"
安装 ElasticSearch-Head 插件(所有节点)
elasticsearch-head 是一个Web前端浏览和有弹性的搜索集群互动。使用以下命令在所有节点的系统上安装这个插件。
$ bin/plugin --install mobz/elasticsearch-head
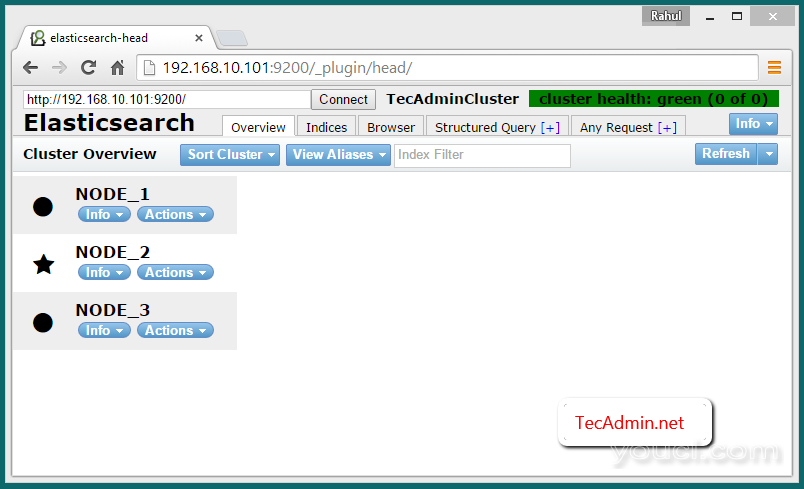
开始ElasticSearch集群(所有节点)
由于ElasticSearch群集安装已经完成。让所有节点上使用以下命令启动ElasticSearch集群。
$ ./bin/elasticsearch &
默认情况下elasticserch监听端口9200和9300。所以,连接到
NODE_1端口9200像下面的网址,你会看到集群中的所有三个节点。
http://NODE_1:9200/_plugin/head/
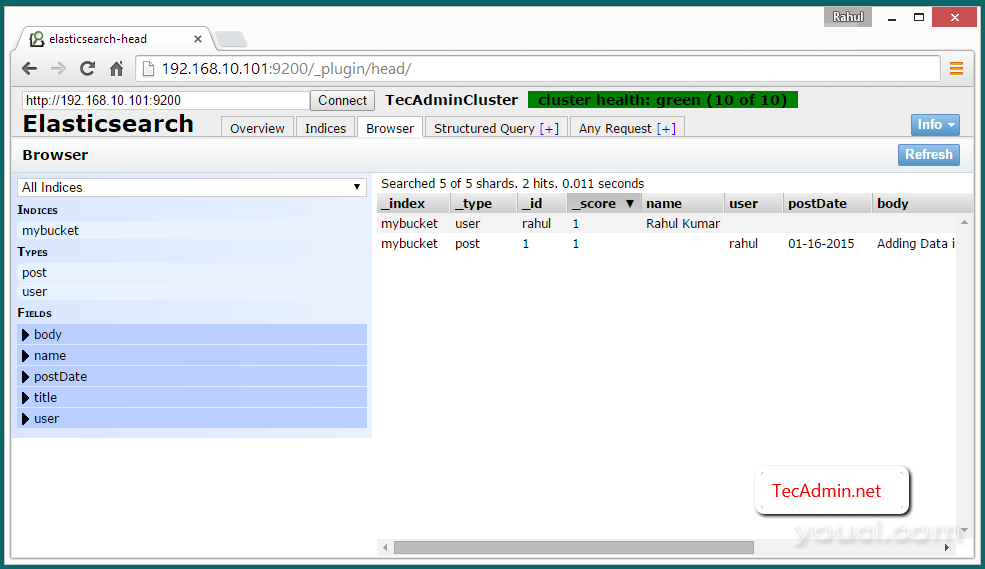
验证多节点群集
要验证群集正常工作。插入一些数据中的一个节点,并且如果相同的数据中的其它节点都有这些数据,这意味着集群正常运行。
在NODE_1插入数据
为了验证集群创建
NODE_1一个桶,并添加一些数据。
$ curl -XPUT http://NODE_1:9200/mybucket
$ curl -XPUT 'http://NODE_1:9200/mybucket/user/rahul' -d '{ "name" : "Rahul Kumar" }'
$ curl -XPUT 'http://NODE_1:9200/mybucket/post/1' -d '
{
"user": "rahul",
"postDate": "01-16-2015",
"body": "Adding Data in ElasticSearch Cluster" ,
"title": "ElasticSearch Cluster Test"
}'
在所有节点上的搜索数据
现在搜索从
NODE_2和
Node_3访问相同的数据,并检查是否相同的数据被复制到集群中的其他节点。按照上面的命令,我们已经创建了一个用户名为rahul并增加了一些数据存在。因此,使用下面的命令来搜索与用户rahul相关的数据。
$ curl 'http://NODE_1:9200/mybucket/post/_search?q=user:rahul&pretty=true'
$ curl 'http://NODE_2:9200/mybucket/post/_search?q=user:rahul&pretty=true'
$ curl 'http://NODE_3:9200/mybucket/post/_search?q=user:rahul&pretty=true'
你将得到的结果类似下面对所有上述命令。
{
"took" : 69,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [ {
"_index" : "mybucket",
"_type" : "post",
"_id" : "1",
"_score" : 1.0,
"_source":
{
"user": "rahul",
"postDate": "01-16-2015",
"body": "Adding Data in ElasticSearch Cluster" ,
"title": "ElasticSearch Cluster Test"
}
} ]
}
}
查看Web浏览器Cluster数据
要在以下网址查看使用群集IP之一elasticsearch-head 插件ElasticSearch访问数据。然后点击
浏览器标签上。
http://NODE_1:9200/_plugin/head/