Linux基金会宣布LFCS(Linux基金会认证的系统管理员 )的认证,一项新计划,旨在帮助个人在世界各地得到基本为Linux系统中间系统管理任务的认证。 这包括支持运行系统和服务,以及第一手故障排除和分析,以及将问题升级到工程团队的智能决策。

Linux基础认证Sysadmin - 第1部分
请观看以下介绍Linux基础认证计划的视频。
该系列将通过10被名为为LFCS(Linux基金会认证的系统管理员 ) 第1部分准备并覆盖的Ubuntu,CentOS的,和openSUSE以下主题:
重要提示 :由于在LFCS认证要求有效二月变化 2,2016年 ,我们将主要包括以下必要的主题在这里公布的LFCS系列。 为了准备这场考试,你是高度鼓励使用联邦经济竞争法系列为好。
这个职位是一个20教程系列 ,将覆盖所需的LFCS认证考试必要的领域和能力第一部分。 话虽这么说,火了你的终端,让我们开始。
在Linux中处理文本流
Linux将对程序的输入和输出视为字符流(或序列)。 为了开始理解重定向和管道,我们必须首先理解三种最重要的I / O(输入和输出)流,它们实际上是特殊文件(按照惯例在UNIX和Linux中,数据流和外围设备或设备文件,也被视为普通文件)。
>(重定向操作)之间的差|(管道操作者)的是,虽然在第一次连接用的文件的命令,后者与另一命令的命令的输出连接。
# command > file # command1 | command2
由于重定向操作符以静默方式创建或覆盖文件,因此我们必须非常小心地使用它,并且不要将其误认为是管道。 Linux和UNIX系统上的管道的一个优点是没有管道涉及的中间文件 - 第一个命令的stdout未写入文件,然后由第二个命令读取。
对于下面的实践练习,我们将使用诗“ 一个快乐的孩子 ”(匿名者)。
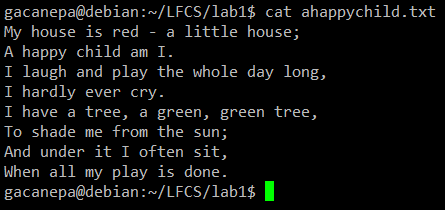
cat命令示例
使用sed
sed的名字是短期的流编辑器。 对于那些不熟悉该术语的人,使用流编辑器对输入流(来自管道的文件或输入)执行基本文本转换。
sed的最基本(和流行)用法是替换字符。 我们将通过改变小写字母y以大写的Y每发生和将输出重定向到ahappychild2.txt开始。 G标志表明,中美战略经济对话应在文件的每一行执行的期限的所有实例替代。 如果省略此标志,sed将仅替换每行上第一次出现的term。
基本语法:
# sed ‘s/term/replacement/flag’ file
我们的例子:
# sed ‘s/y/Y/g’ ahappychild.txt > ahappychild2.txt
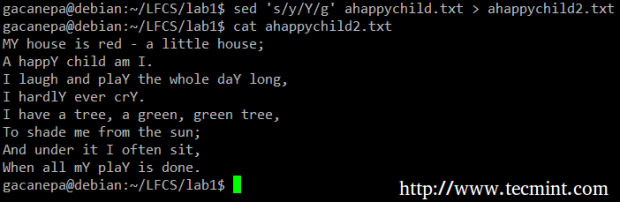
sed命令示例
如果你要搜索或替换特殊字符(如/,\,&),你需要逃避它,在任期或者替换字符串,用一个反斜杠。
例如,我们将替换这个词和一个和号。 与此同时,我们将在第一个是在一行的开头发现你取代我的词。
# sed 's/and/\&/g;s/^I/You/g' ahappychild.txt
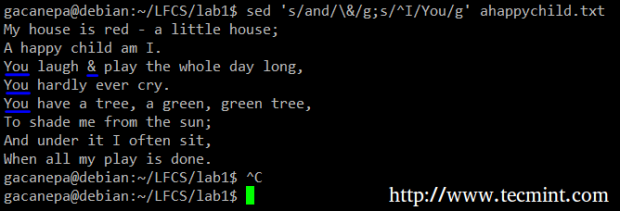
sed替换字符串
另外,在上述命令,一个^(插入符号)是用于表示一个行的开始公知的正则表达式。
正如你可以看到的,我们可以组合两个或更多的替换命令(并在其中使用正则表达式),用分号分隔它们,并用单引号将集合包围起来。
sed的另一个用途是显示(或删除)文件的所选部分。 在下面的例子中,我们将显示前5行的/ var /从06月08日log / messages中 。
# sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p
注意,默认情况下,sed打印每一行。 我们可以覆盖这个行为与-n选项,然后告诉SED打印(用P表示)的文件(或管道)的只有一部分在第一种情况和线条图案(6月8日在行的开头匹配1至5包括在第二种情况中)。
最后,在检查脚本或配置文件以检查代码本身并省略注释时可能很有用。 下面的sed单行删除(D)空行或那些开始#(|字符表示布尔或两个正则表达式之间)。
# sed '/^#\|^$/d' apache2.conf
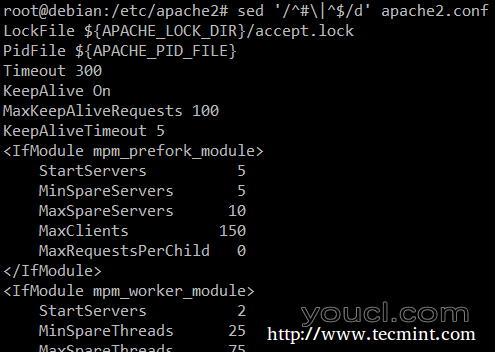
sed匹配字符串
uniq命令
uniq命令允许我们报告或文件中删除重复的行,写入默认标准输出。 我们必须注意到,uniq的不检测重复行,除非它们是相邻的。 因此,uniq的通常与前面的排序 (这是用于排序的文本文件中的行),用于沿。 默认情况下,采取排序的第一个字段(用空格隔开)作为重点领域。 要指定一个不同的密钥领域,我们需要使用-k选项。
例子
杜- SCH /路径/到/目录/ *命令返回每人类可读格式的指定目录中的子目录和文件的磁盘空间使用情况(也显示每个目录总),不按大小的输出,但通过子目录和文件名。 我们可以使用以下命令按大小排序。
# du -sch /var/* | sort –h
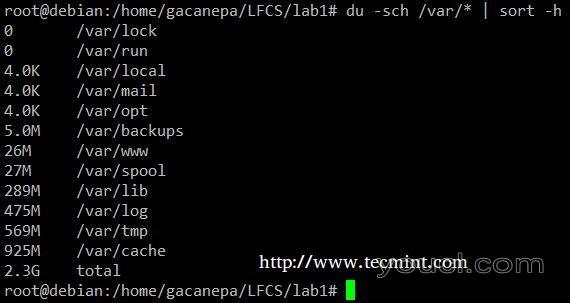
排序命令示例
可以通过告诉uniq的计数在日志按日期的事件数使用每行(其中,被指定的日期)的前6个字符(-w 6)执行的比较,并通过发生的次数前缀每个输出线(-c)用下面的命令。
# cat /var/log/mail.log | uniq -c -w 6

文件中的计数
最后,你可以结合sort和uniq(因为他们通常是)。 请考虑以下文件,其中包含捐赠者名单,捐赠日期和金额。 假设我们想知道有多少独特的捐赠者。 我们将使用以下命令剪切第一个字段(字段由冒号分隔),按名称排序,并删除重复行。
# cat sortuniq.txt | cut -d: -f1 | sort | uniq
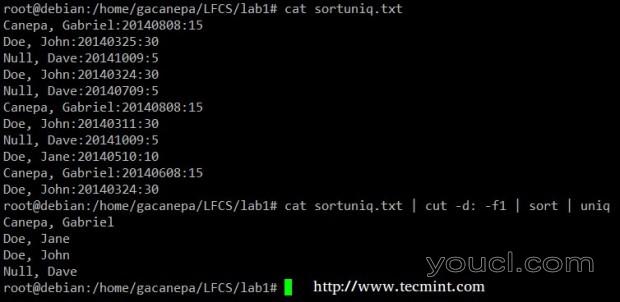
在文件中查找唯一记录
另请阅读 : 13“猫”命令实例
grep命令
grep的搜索文本文件或(命令输出)用于指定正则表达式的发生,并输出包含匹配到标准输出的任何行。
例子
从显示的/ etc / passwd文件的用户gacanepa,忽略大小写的信息。
# grep -i gacanepa /etc/passwd

grep命令示例
显示在/ etc名称以RC后跟任意单个数字的所有内容。
# ls -l /etc | grep rc[0-9]
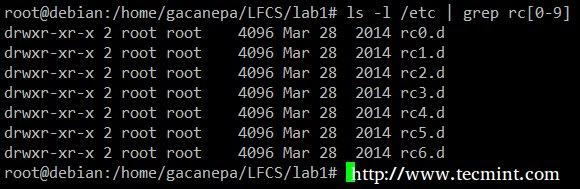
列表内容使用grep
另请阅读 : 12的“grep”命令实例
tr命令用法
tr命令可以用来翻译(其他城市)或者从标准输入删除字符,并将结果写入到stdout。
例子
在sortuniq.txt文件中将所有小写更改为大写。
# cat sortuniq.txt | tr [:lower:] [:upper:]
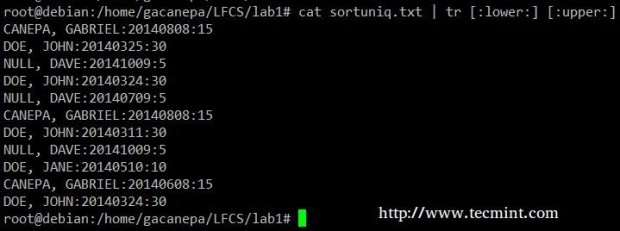
在文件中排序字符串
挤进LS -l的输出分隔符只有一个空间。
# ls -l | tr -s ' '
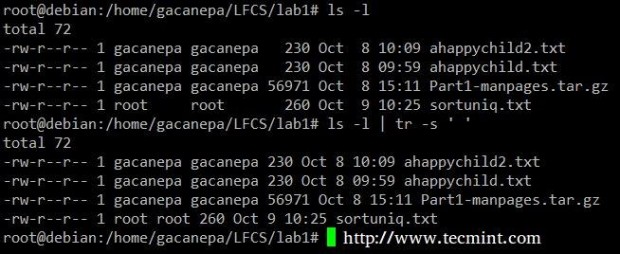
挤压分隔符
cut命令用法
cut命令提取的输入线部分(从标准输入或文件),并显示在标准输出,基于字节数(-b选项)的结果,字符(-c)或者字段(-f)。 在后一种情况下(基于域),默认的分隔符是标签,但不同的分隔符可以使用-d选项来指定。
例子
提取用户帐户和从/ etc / passwd文件分配给它们的默认外壳(-d选项允许我们指定字段分隔符,和-f开关指示哪些字段(S)将被提取。
# cat /etc/passwd | cut -d: -f1,7
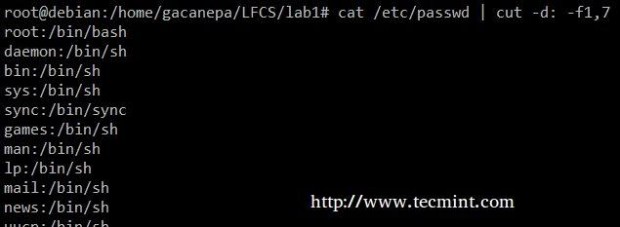
提取用户帐户
综上,我们将建立一个由最后一个命令的输出的第一和第三非空文件的文本流。 我们将使用grep作为第一个过滤器来检查用户gacanepa的会话,再挤分隔符只有一个空格(TR -s'')。 接下来,我们将通过第二场(在这种情况下,IP地址)表示独特提取与切割第一和第三场,最后的排序。
# last | grep gacanepa | tr -s ' ' | cut -d' ' -f1,3 | sort -k2 | uniq
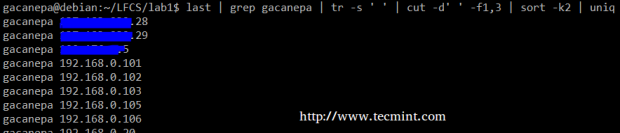
最后一个命令示例
上述命令显示如何组合多个命令和管道,以便根据我们的需要获得过滤的数据。 随意也可以通过部件运行它,帮助您看到从一个命令到下一个命令的流水线输出(这可以是一个伟大的学习经验,顺便!)。
概要
虽然这个例子(以及当前教程中的其余示例)看起来可能看起来不是非常有用,但是它们是一个很好的起点,开始尝试用于从Linux创建,编辑和操作文件的命令命令行。 请随时留下您的问题和意见,他们将非常感谢!







