来自第Prometheus联合创始人朱利叶斯·Volz的
介绍
Prometheus是一个开源监控系统和时间序列数据库。 Prometheus最重要的方面之一是其多维数据模型以及伴随的查询语言。 此查询语言允许您对维数据进行切片和切分,以便以特别的方式回答操作问题,在仪表板中显示趋势或生成系统故障的警报。
在本教程中,我们将学习如何查询Prometheus 0.17.0。 为了具有适合的示例数据,我们将设置三个相同的演示服务实例,导出各种合成度量。 然后我们将设置一个Prometheus服务器,以刮除和存储这些指标。 使用示例度量,我们将学习如何查询Prometheus,从简单的查询开始,到更高级的查询。
本教程之后,您将了解如何根据其维度,聚合和变换时间系列以及如何在不同度量之间进行算术来选择和过滤时间系列。 在后续的教程, 如何查询Prometheus在Ubuntu 14.04第2部分 ,我们将建立在知识,从本教程涉及了更高级的查询用例。
先决条件
要遵循本教程,您需要:
- Ubuntu 14.04 Droplet
- 非root用户( 与Ubuntu 14.04初始服务器设置介绍了如何设置起来。)
注:本文已经在1个CPU / 512 MB RAM的Ubuntu 14.04Droplet过测试。 应针对不同数量的可用资源调整Prometheus配置。
本教程中的所有命令都可以作为非root用户成功运行。 不需要Sudo访问。
第1步 - 安装Prometheus
在此步骤中,我们将下载,配置和运行Prometheus服务器,以刮除三个(尚未运行)演示服务实例。
首先,下载Prometheus:
wget https://github.com/prometheus/prometheus/releases/download/0.17.0/prometheus-0.17.0.linux-amd64.tar.gz
提取tarball:
tar xvfz prometheus-0.17.0.linux-amd64.tar.gz
在创建主机文件系统的最小Prometheus配置文件~/prometheus.yml :
nano ~/prometheus.yml
将以下内容添加到文件:
# Scrape the three demo service instances every 5 seconds.
global:
scrape_interval: 5s
scrape_configs:
- job_name: 'demo'
target_groups:
- targets:
- 'localhost:8080'
- 'localhost:8081'
- 'localhost:8082'
保存并退出nano。
这个示例配置使Prometheus抓取演示实例。 Prometheus使用pull模型,这就是为什么它需要配置为知道从哪个端点拉取指标。 演示实例尚未运行,但稍后将在端口8080,8081和8082上运行。
使用nohup启动Prometheus和作为后台进程:
nohup ./prometheus-0.17.0.linux-amd64/prometheus -storage.local.memory-chunks=10000 &
该nohup在命令开始发送输出到文件~/nohup.out ,而不是标准输出。 在&在命令年底将允许进程在后台继续运行,同时给你的额外的命令提示符后面。 为了使这一进程回到前面(回终端运行的进程),使用命令fg在同一个终端。
如果一切顺利,在~/nohup.out文件中,你应该会看到类似以下的输出:
prometheus, version 0.17.0 (branch: release-0.17, revision: e11fab3)
build user: fabianreinartz@macpro
build date: 20160302-17:48:43
go version: 1.5.3
INFO[0000] Loading configuration file prometheus.yml source=main.go:202
INFO[0000] Loading series map and head chunks... source=storage.go:299
INFO[0000] 0 series loaded. source=storage.go:304
WARN[0000] No AlertManager configured, not dispatching any alerts source=notification.go:165
INFO[0000] Starting target manager... source=targetmanager.go:114
INFO[0000] Target manager started. source=targetmanager.go:168
INFO[0000] Listening on :9090 source=web.go:239
在另一个终端中,您可以使用以下命令监视此文件的内容:
tail -f ~/nohup.out
当内容写入文件时,它将显示到终端。
默认情况下,Prometheus将加载从其配置prometheus.yml (我们刚刚创建),并在其存储度量数据./data在当前的工作目录。
该-storage.local.memory-chunks标志调整Prometheus的内存使用主机系统的极少量的RAM(只有512MB)和少数在本教程中存储的时间系列。
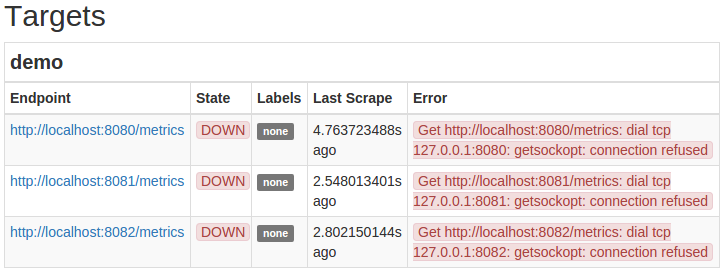
您现在应该能够到达你的Prometheus服务器http:// your_server_ip :9090/ 。 验证它被配置为通过标题来收集来自三个演示实例指标http:// your_server_ip :9090/status和定位三大目标端点的demo中的目标部分的工作。 国家列所有三项指标应该显示目标的状态下由于演示实例尚未开始,因此不能被刮掉:
第2步 - 安装演示实例
在本节中,我们将安装并运行三个演示服务实例。
下载演示服务:
wget https://github.com/juliusv/prometheus_demo_service/releases/download/0.0.4/prometheus_demo_service-0.0.4.linux-amd64.tar.gz
提取:
tar xvfz prometheus_demo_service-0.0.4.linux-amd64.tar.gz
在单独的端口上运行演示服务三次:
./prometheus_demo_service -listen-address=:8080 &
./prometheus_demo_service -listen-address=:8081 &
./prometheus_demo_service -listen-address=:8082 &
在&在后台启动演示服务。 他们将无法登录任何东西,但他们会露出Prometheus指标/metrics HTTP端点上的对应端口。
这些演示服务导出关于几个模拟子系统的合成度量。 这些是:
- 显示请求计数和延迟(由路径,方法和响应状态代码锁定)的HTTP API服务器
- 显示上次成功运行的时间戳和已处理字节数的周期性批处理作业
- 关于CPU数量及其使用的综合指标
- 关于磁盘的总大小及其使用的综合指标
各个指标在后面部分的查询示例中介绍。
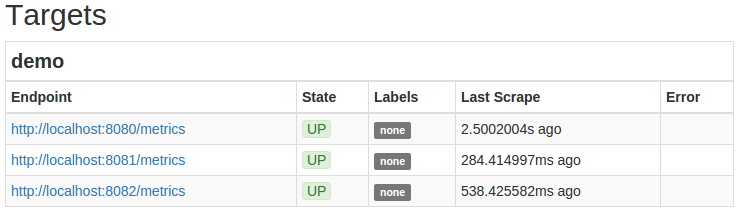
Prometheus服务器现在应该自动开始刮取您的三个演示实例。 前往您的Prometheus服务器状态页以http:// your_server_ip :9090/status ,并确认为目标demo工作目前表现出的状态UP:
第3步 - 使用查询浏览器
在这一步,我们将熟悉Prometheus的内置查询和图形Web界面。 虽然此界面非常适合用于ad-hoc数据探索和学习关于Prometheus的查询语言,但它不适合构建持久的仪表板,并且不支持高级可视化功能。 对于构建仪表盘,看到的例子如何添加Prometheus仪表板Grafana 。
转到http:// your_server_ip :9090/graph的Prometheus的服务器上。 它应该看起来像这样:
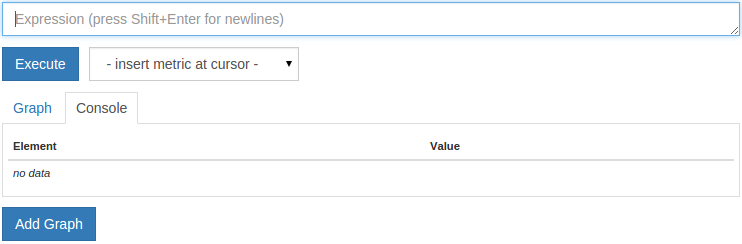
正如你所看到的,有两个标签: 图表和控制台 。 Prometheus允许您以两种不同的模式查询数据:
- 控制台选项卡,您可以在当前时间评估一个查询表达式。 运行查询后,表将显示每个结果时间系列的当前值(每个输出系列一个表行)。
- Graph选项卡,您可以在指定的时间范围内绘制查询表达式。
因为Prometheus可以扩展到数百万的时间序列,可以构建非常昂贵的查询(认为这类似于从SQL数据库中的大表中选择所有行)。 要避免的查询超时或超载您的服务器,建议开始探索,并在控制台中构建查询查看第一,而不是他们绘制图形马上。 在单个时间点评估潜在昂贵的查询将使用比在同一时间范围内绘制相同查询的资源少得多的资源。
一旦你已经足够缩小查询(在它选择装载系列而言,计算它需要执行和输出时间序列号),则可以切换到Graph选项卡,显示随着时间的推移计算的表达式。 知道查询何时足够便于绘制图表不是一个精确的科学,取决于您的数据,延迟要求和运行您的Prometheus服务器的机器的力量。 你会得到一个时间的感觉。
由于我们的测试Prometheus服务器不会刮除大量的数据,我们实际上不能在本教程中制定任何昂贵的查询。 例如,任何查询可能无论是在图形和没有风险的控制台视图中查看。
为了减少或增加图形的时间范围,单击-或+按钮。 要移动图形的结束时间,按<<或>>按钮。 你可以通过激活层叠复选框栈的图。 最后,RES。 (S)输入允许您指定自定义查询分辨率(不需要在本教程)。
第4步 - 执行简单的时间序列查询
在开始查询之前,让我们快速查看Prometheus的数据模型和术语。 Prometheus从根本上存储所有数据作为时间序列。 每次系列是度量名称,以及一组键值对Prometheus调用标签标识。 度量名称指示正在测量的系统的整体方面(例如,因为进程启动处理HTTP请求的数量, http_requests_total )。 标签用来区分度量这样的子维度的HTTP方法(例如, method="POST"或路径(如path="/api/foo" )。 最后,一系列样本形成一个系列的实际数据。 每个样本由时间戳和值组成,其中时间戳具有毫秒精度,值始终为64位浮点值。
最简单的查询可以返回具有给定度量标准名称的所有系列。 例如,演示服务导出度量demo_api_request_duration_seconds_count表示由虚拟服务处理合成的API的HTTP请求的数目。 你也许会奇怪,为什么度量名称包含字符串duration_seconds 。 这是因为,此计数器是一个较大的直方图度量命名的一部分demo_api_request_duration_seconds其中主要跟踪请求持续时间的分布,但也暴露跟踪请求的总数(由Stapling_count此处),为有用副产品。
确保控制台的查询选项卡中选择,在页面顶部输入的文本字段以下查询,然后单击执行按钮来执行查询:
demo_api_request_duration_seconds_count
由于Prometheus正在监视三个服务实例,因此您应该看到一个表格输出,其中包含27个带有此度量标准名称的结果时间系列,每个跟踪的服务实例,路径,HTTP方法和HTTP状态代码各一个。 除了由服务实例本身(设置标签method , path和status ),该系列将有适当的job和instance ,从彼此区分不同的服务实例的标签。 当存储来自被抓取目标的时间序列时,Prometheus会自动附加这些标签。 输出应如下所示:
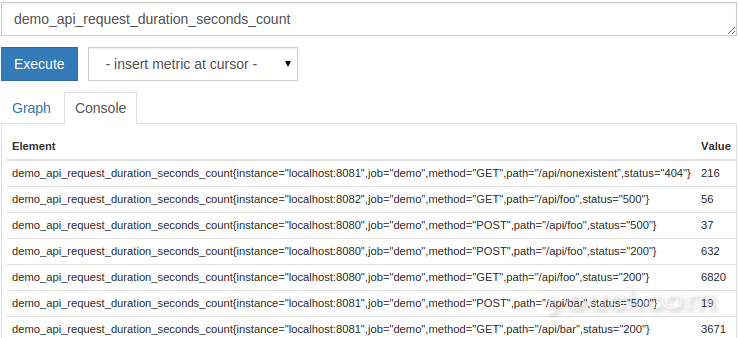
右侧表格列中显示的数值是每个时间系列的当前值。 随意绘制输出(单击图表选项卡,然后再次单击执行 ),这和随后的查询,看看这些数值随着时间的发展。
我们现在可以添加标签匹配器,以根据其标签限制返回的系列。 标签匹配器直接跟随大括号中的度量名称。 在最简单的形式中,它们对具有给定标签的精确值的系列进行过滤。 例如,下面的查询只显示任何请求计数GET请求:
demo_api_request_duration_seconds_count{method="GET"}
匹配器可以使用逗号组合。 例如,我们还可以只从实例指标筛选localhost:8080和作业demo :
demo_api_request_duration_seconds_count{instance="localhost:8080",method="GET",job="demo"}
结果将如下所示:
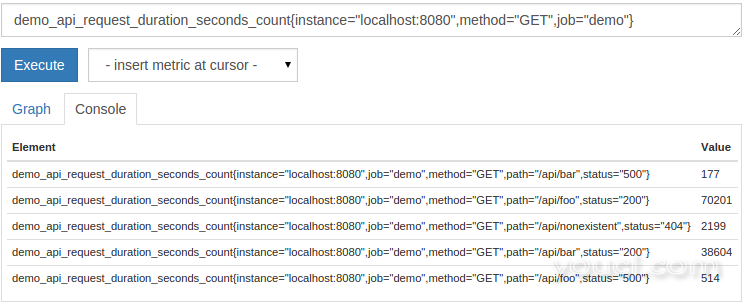
当组合多个匹配器时,它们都需要匹配以选择一个系列。 上述返回表达式仅API请求计数端口8080上与那里的HTTP方法是运行服务实例GET 。 我们还确保我们只选择属于指标demo工作。
注 :建议始终指定job选择的时间序列时的标签。 这可以确保您不会意外地从不同的工作中选择具有相同名称的指标(当然,这当然是您的目标!)。 虽然我们在本教程中只监控一个作业,但在下面的大多数示例中,我们仍然会根据作业名称来选择,以强调这种做法的重要性。
此外平等匹配,Prometheus支持非相等匹配( != ),正则表达式匹配( =~以及负正则表达式匹配( !~ 也可以完全省略度量标准名称,并且只使用标签匹配器进行查询。 例如,要列出所有系列(无论哪个指标名称或作业),其中的path标签开头/api ,你可以运行此查询:
{path=~"/api.*"}
上述正则表达式需要结束与.*因为正则表达式匹配总是在一个Prometheus满弦。
所得的时间序列将是具有不同度量名称的系列的混合:
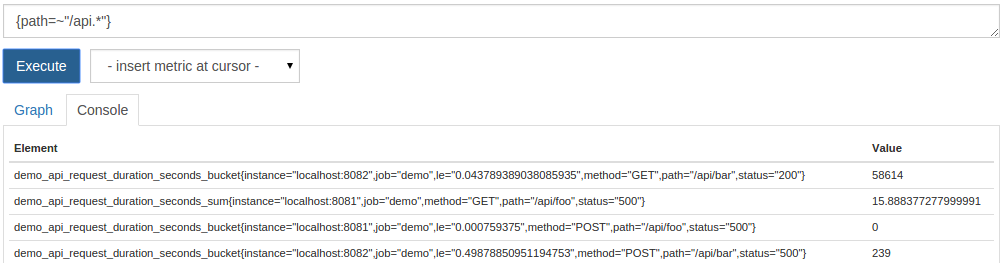
现在,您知道如何通过其度量标准名称以及其标签值的组合来选择时间系列。
第5步 - 计算利率和其他衍生工具
在本节中,我们将了解如何计算指标随时间的速率或增量。
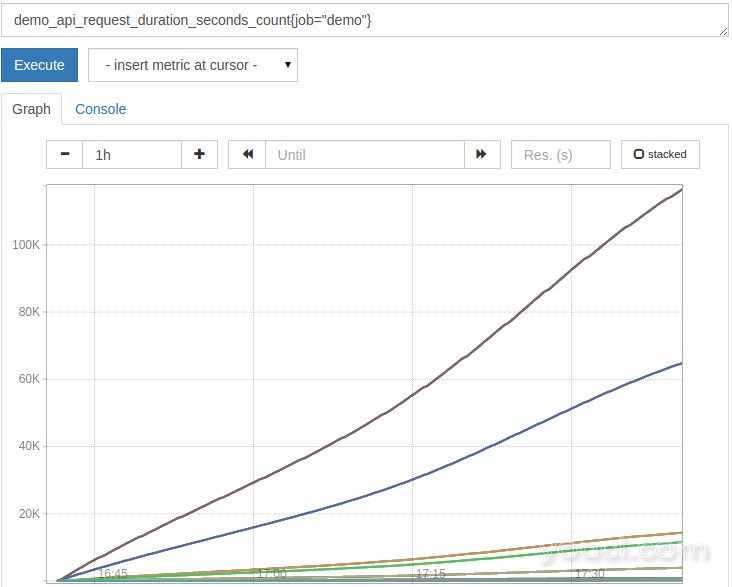
你们中的一个将在Prometheus使用最频繁的功能之一是rate() 在Prometheus中,通常使用原始计数器跟踪事件,并让Prometheus服务器在查询时间内计算ad-hoc速率(这有许多优点,例如不丢失速率尖峰在刮擦之间,以及能够在查询时间选择动态平均窗口)。 柜台开始0时,监控服务启动并在服务过程中的续航时间不断得到增加。 偶尔,当监视进程重新启动,其计数器复位到0 ,并开始从那里再度攀升。 绘制原始计数器通常不是非常有用,因为您将只看到不断增加的线,偶尔重置。 您可以看到,通过绘制演示服务的API请求计数:
demo_api_request_duration_seconds_count{job="demo"}
它看起来有点像这样:
为了使计数器有用的,我们可以使用rate()函数来计算其每秒的速度递增。 我们需要告诉rate()在该时间窗由一系列的匹配后提供一系列的选择,以平均速率(如[5m] )。 例如,要计算上述计数器指标的每秒增加量(如过去五分钟的平均值),请绘制以下查询:
rate(demo_api_request_duration_seconds_count{job="demo"}[5m])
结果现在更有用:
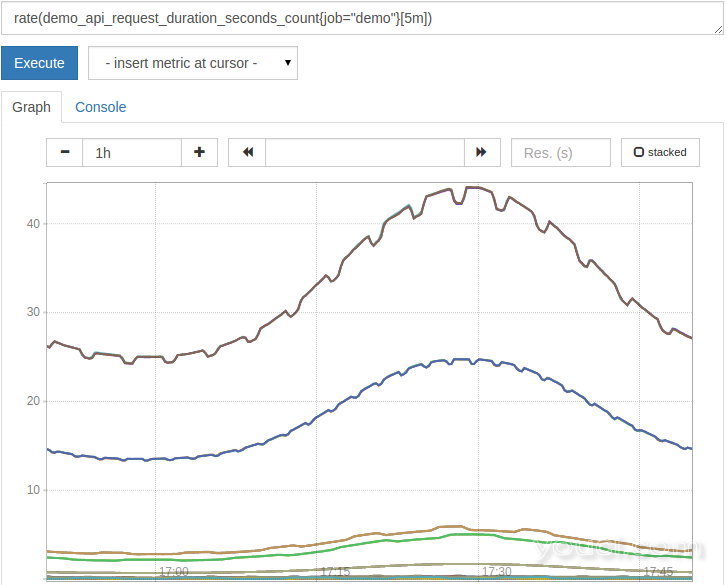
rate()很聪明,通过假设一个计数器值的任何降低是一个复位计数器复位自动调整。
的一个变型rate()为irate() 而rate()平均速率超过在给定时间窗口中的所有样本(在这种情况下,5分钟), irate()只会回顾两个样本到过去。 它仍然需要你指定的时间窗口(如[5m] )知道多远,最大限度地回头看,及时为这两个样本。 irate()会更快地响应率的变化,因此,通常建议在使用图形。 相比之下, rate()将提供平滑的利率,并建议在警报表达式中使用(因为短期利率峰值将挫伤,晚上没有吵到你)。
随着irate()上面的图是这样的,在请求速率揭露短间隔逢低:
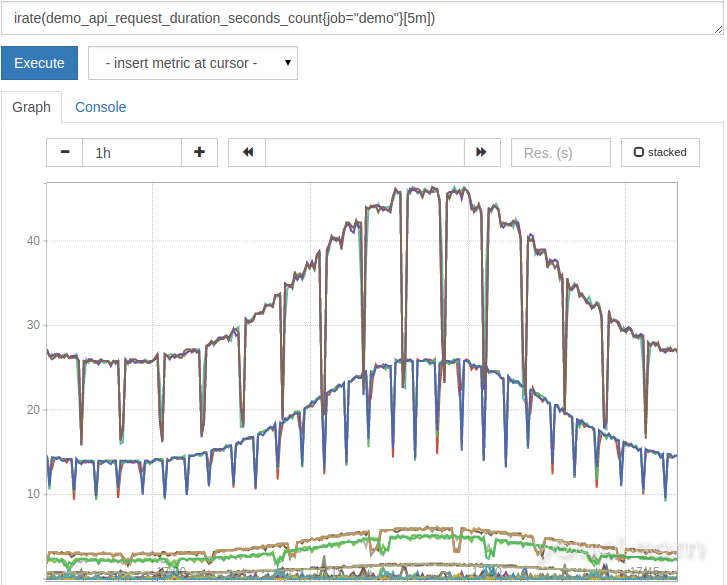
rate()和irate()总是计算每秒的速率。 有时你会想知道由计数器增加了一个时间窗口,但对于计数器复位还是正确的总量 。 可以用实现这种increase()函数。 例如,要计算最近一小时处理的请求总数,请查询:
increase(demo_api_request_duration_seconds_count{job="demo"}[1h])
除了计数器(只能增加),还有计量指标。 测量仪是可以随时间上升或下降的值,如温度或可用磁盘空间。 如果我们希望随着时间的推移来计算仪表的变化,我们不能用rate() / irate() / increase()系列函数。 这些都是面向计数器的,因为它们将度量值的任何减少解释为计数器复位并对其进行补偿。 相反,我们可以使用deriv()函数,其计算基于线性回归计的每秒衍生物。
例如,要查看我们的演示服务导出的虚构磁盘使用情况基于最近15分钟的线性回归增加或减少(以每秒MiB为单位),我们可以查询:
deriv(demo_disk_usage_bytes{job="demo"}[15m])
结果应如下所示:
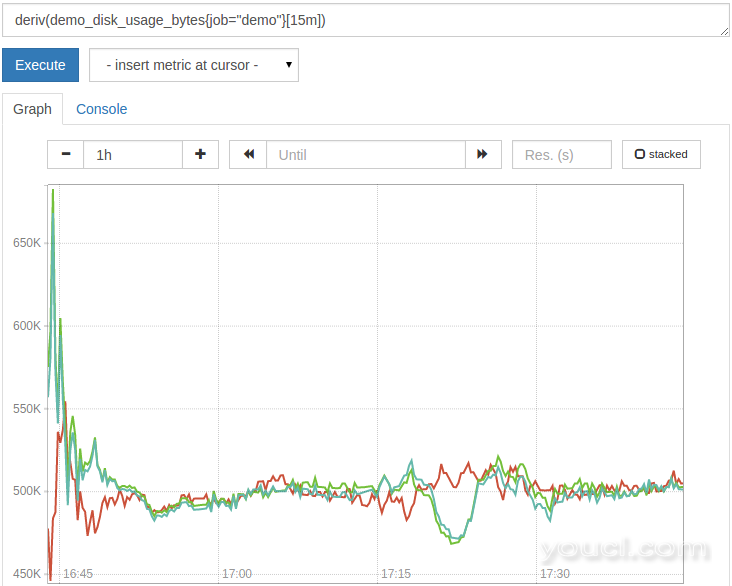
要了解更多关于计算仪表三角洲和趋势,也看到了delta()和predict_linear()函数。
我们现在知道如何使用不同的平均行为来计算每秒速率,如何在速率计算中处理计数器重置,以及如何计算量规的导数。
第6步 - 随时间聚集
在本节中,我们将学习如何聚合各个系列。
Prometheus以高维度细节收集数据,这可能会导致每个指标名称的许多系列。 然而,通常你不关心所有维度,你甚至可能有太多的系列,以一个合理的方式一次性绘制所有的图。 解决方案是聚合一些维度,并只保留你关心的。 例如,在演示服务跟踪由API HTTP请求method , path ,和status 。 Prometheus从节点出口商拼抢时,增加了进一步维度这个指标:该instance和job跟踪其处理的指标是从哪里来的标签。 现在,看到总请求率在所有维度,我们可以使用sum()集合运算符:
sum(rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
然而,这种聚集在所有维度,并创建一个单一的输出系列:
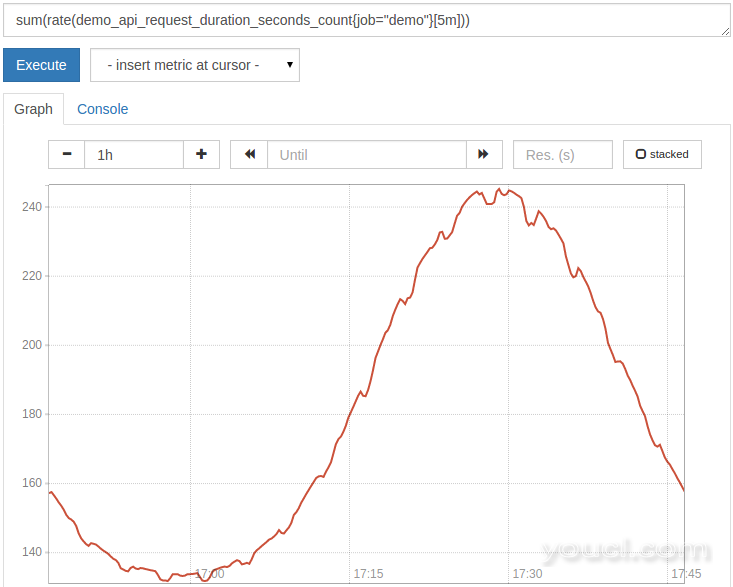
通常不过,你会想保留一些在输出的尺寸。 对于这一点, sum()以及其他聚合支持without(<label names>)指定的尺寸聚集了条款。 也有另一种相反的by(<label names>)子句,可以指定哪些标签名称保存。 如果我们想知道在所有三个服务实例和所有路径上求和的总请求率,但是通过方法和状态代码分解结果,我们可以查询:
sum without(method, status) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
这相当于:
sum by(instance, path, job) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
该结果和现在由分组instance , path和job :
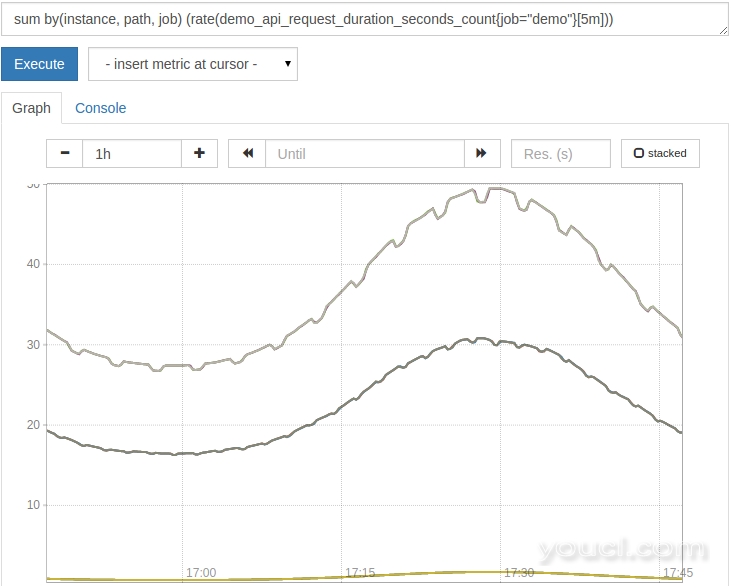
注意 :始终计算rate() irate()或increase()应用任何聚合之前 。 如果您首先应用聚合,它将隐藏计数器重置,这些功能将无法正常工作。
Prometheus支持以下聚合运营商,每一个支持它by()或without()子句选择保留哪些维度:
-
sum:聚合组内的款项的所有值。 -
min:选择一个聚合组内的最小的所有值。 -
max:选择一个聚合组内的所有最高值。 -
avg:计算一个聚合组内的所有值的平均值(算术平均)。 -
stddev:计算标准偏差的所有值的汇总组内。 -
stdvar:计算标准差的所有值的汇总组内。 -
count:计算一个聚合组内串联的总数量。
您现在已经学习了如何聚合系列列表,以及如何仅保留您关心的维度。
第7步 - 执行算术
在本节中,我们将学习如何在Prometheus中进行算术。
作为最简单的算术示例,您可以使用Prometheus作为数字计算器。 例如,运行在控制台视图以下查询:
(4 + 7) * 3
您将获得一个标产值33 :
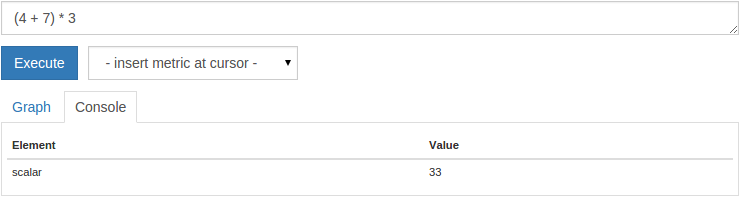
标量值是一个没有任何标签的简单数值。 为了使这更加有用,Prometheus让你共同算术运算符适用于( + , - * , / , % ),以整个时间序列矢量。 例如,以下查询通过运行到MiB的模拟的上一批作业转换处理的字节数:
demo_batch_last_run_processed_bytes{job="demo"} / 1024 / 1024
结果将以MiB显示:
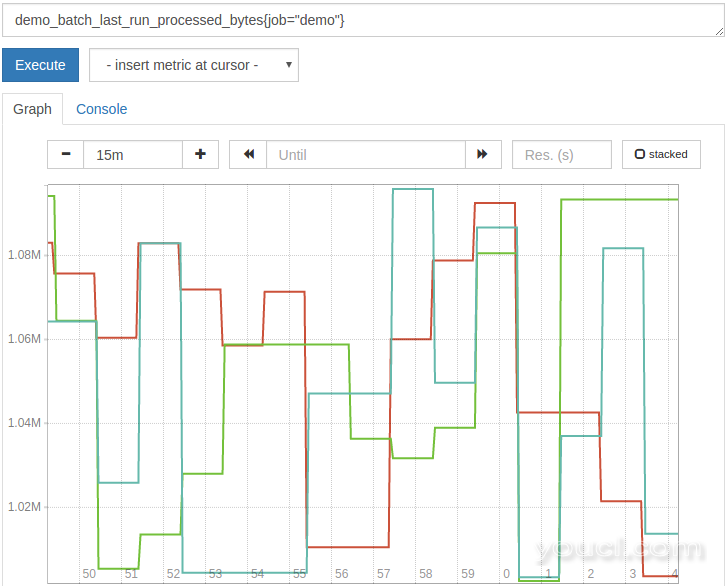
对于这些类型的单位转换,通常使用简单的算术,虽然好的可视化工具(如Grafana)也为您处理转换。
Prometheus的专长(和Prometheus真正闪耀!)是两组时间序列之间的二进制算术。 当在两组系列之间使用二进制运算符时,Prometheus自动匹配操作左侧和右侧具有相同标号集的元素,并将运算符应用于每个匹配对以生成输出系列。
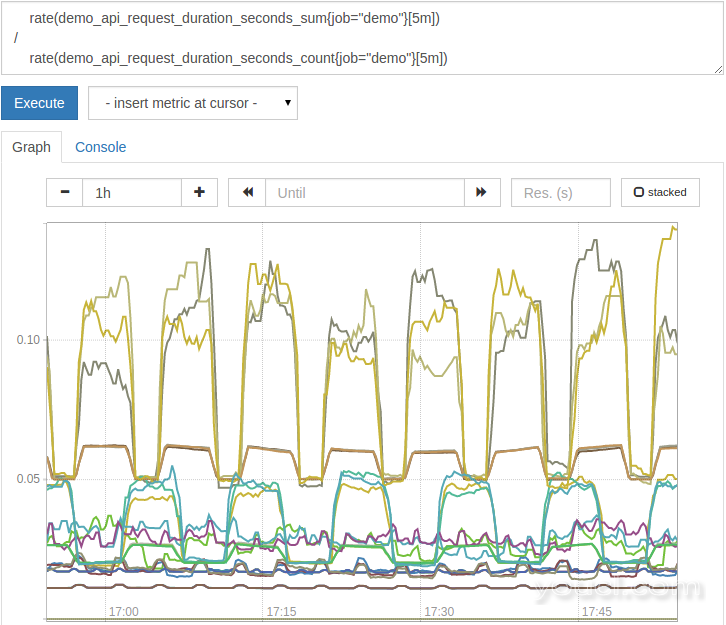
例如, demo_api_request_duration_seconds_sum指标告诉我们有多少秒都花了回答HTTP请求,而demo_api_request_duration_seconds_count告诉我们有多少个HTTP请求。 这两个指标具有相同的尺寸( method , path , status , instance , job )。 要计算每个维度的平均请求延迟,我们可以简单地查询花费在请求中的总时间除以请求总数的比率。
rate(demo_api_request_duration_seconds_sum{job="demo"}[5m])
/
rate(demo_api_request_duration_seconds_count{job="demo"}[5m])
请注意,我们也裹rate()手术区周围的每一侧的功能,只考虑在最后5分钟发生的请求延迟。 这还增加了抗计数器重置的弹性。
最终的平均请求延迟图应如下所示:
但是当标签不完全匹配两边时,我们该怎么办? 特别是当我们在操作的两侧具有不同大小的时间序列集时,因为一侧具有比另一侧更大的尺寸。 例如,在演示作业出口在各种模式(花费虚构CPU时间idle , user , system ),为度量demo_cpu_usage_seconds_total与mode标签尺寸。 它也出口CPU的一个虚构的总数为demo_num_cpus (对这个指标没有额外维度)。 如果您尝试用一个乘以另一个来达到三个模式中的每一个的百分比的平均CPU使用率,查询将不会产生输出:
# BAD!
# Multiply by 100 to get from a ratio to a percentage
rate(demo_cpu_usage_seconds_total{job="demo"}[5m]) * 100
/
demo_num_cpus{job="demo"}
在这些一对多或多对一匹配中,我们需要告诉Prometheus哪个标签子集用于匹配,我们还需要指定如何处理额外的维度。 为了解决匹配,我们添加一个on(<label names>)子句的二元运算,指定标签匹配。 扇出和组计算通过较大的一侧额外维的各个值,我们添加一个group_left(<label names>)或group_right(<label names>)子句中列出的左侧或右侧的额外维度, 分别。
在这种情况下,正确的查询将是:
# Multiply by 100 to get from a ratio to a percentage
rate(demo_cpu_usage_seconds_total{job="demo"}[5m]) * 100
/ on(job, instance) group_left(mode)
demo_num_cpus{job="demo"}
结果应如下所示:
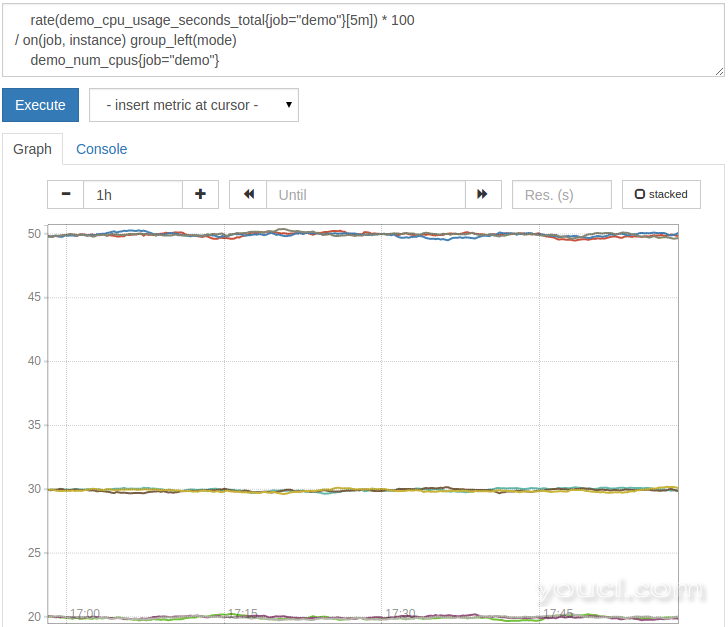
在on(job, instance)告诉操作员只匹配系列从左侧和右侧上的job和instance标签(并因此不是对mode标签,它不在右侧存在),而group_left(mode)第告诉操作员扇出并显示每模式CPU使用率平均值。 这是多对一匹配的情况。 为了做反向(一到多)的匹配,使用group_right(<label names>)以同样的方式条款。
您现在知道如何使用时间序列集之间的算术,以及如何处理不同的维度。
结论
在本教程中,我们设置了一组演示服务实例,并使用Prometheus监视它们。 然后,我们学习了如何对收集的数据应用各种查询技术来回答我们关心的问题。 您现在知道如何选择和过滤系列,如何聚合维度,以及如何计算费率或派生或算术。 您还学习了如何处理一般的查询构造,以及如何避免重载您的Prometheus服务器。
要了解更多有关Prometheus的查询语言,包括如何从直方图,如何处理基于时间戳的指标,或如何查询服务实例的健康,头做计算百分如何在Ubuntu 14.04第2部分查询Prometheus 。







