介绍
本教程是一个ELK(Elasticsearch,Logstash,Kibana)故障排除指南。 假定您遵循了如何在Ubuntu 14.04安装Elasticsearch 1.7,Logstash 1.5和4.1 Kibana(ELK)的教程,或它的CentOS的等价物 ,具有Logstash转发,但它可能是故障排除其他一般ELK设置非常有用。
本教程的结构为一系列常见问题,以及这些问题的潜在解决方案,以及帮助您验证ELK的各个组件是否正常工作的步骤。 因此,随时跳到与您遇到的问题相关的部分。
问题:Kibana没有默认指数模式警告
通过网络浏览器访问Kibana时,您可能会遇到包含此警告的页面:
Kibana warning:Warning No default index pattern. You must select or create one to continue.
...
Unable to fetch mapping. Do you have indices matching the pattern?
以下是警告的屏幕截图:
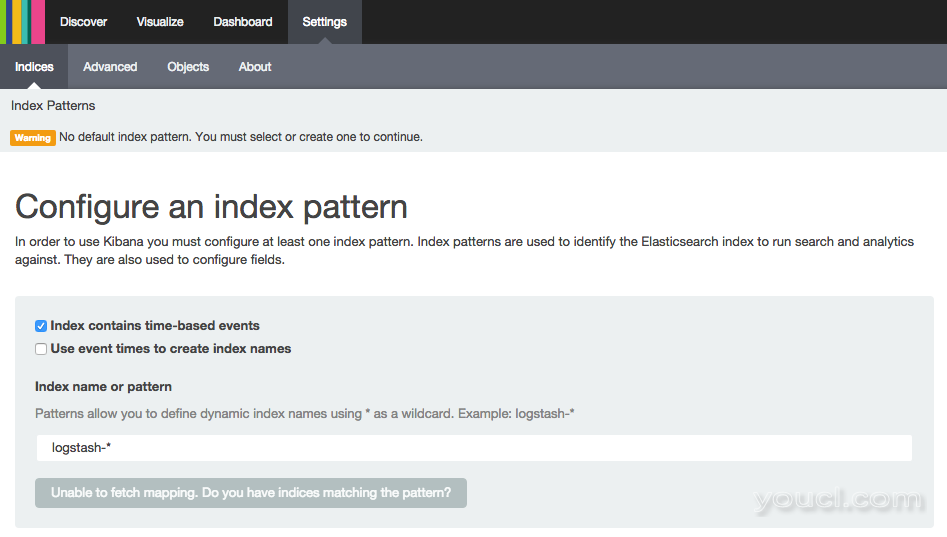
“无法获取映射”表示Elasticsearch不包含匹配默认的任何条目logstash-*格局。 通常,这意味着您的日志不会存储在Elasticsearch中,因为从Logstash到Elasticsearch的通信问题,和/或从您的日志发运器(例如Logstash转发器)到Logstash。 换句话说,你的日志不是通过从Logstash转发器到Logstash的链,到Elasticsearch的某些原因。
要解决Logstash和Elasticsearch之间的沟通问题,通过运行Logstash故障排除部分。 要解决Logstash转发和Logstash之间的沟通问题,通过运行Logstash转发故障排除部分。
如果将Logstash配置为使用非默认索引模式,则可以通过在文本框中指定正确的索引模式来解决该问题。
问题:Kibana无法连接到Elasticsearch
当通过网络浏览器访问Kibana时,您可能会遇到一个出现此错误的页面:
Kibana error:Fatal Error
Kibana: Unable to connect to Elasticsearch
Error: Unable to connect to Elasticsearch
Error: Bad Gateway
...
这里是错误的屏幕截图:
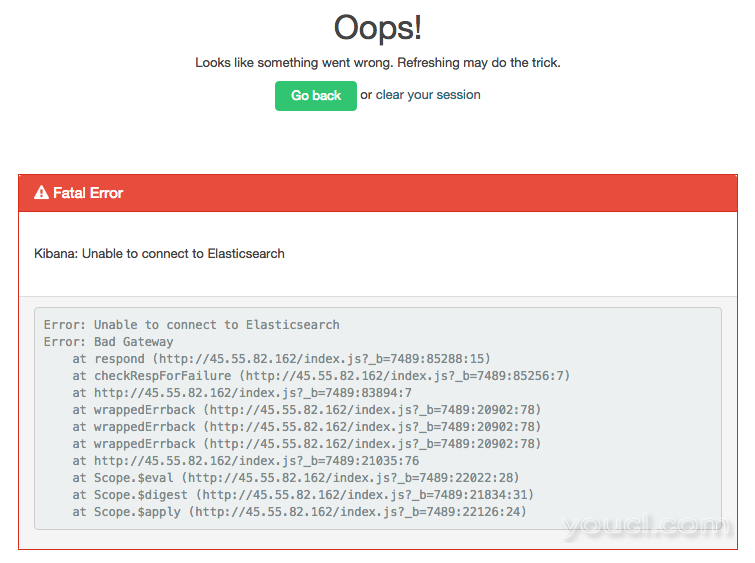
这意味着Kibana无法连接到Elasticsearch。 Elasticsearch可能未运行,或者Kibana可能配置为在错误的主机和端口上查找Elasticsearch。
要解决此问题,请按照Elasticsearch疑难解答部分确保Elasticsearch正在运行。 然后确保Kibana配置为连接到运行Elasticsearch的主机和端口。
例如,如果Elasticsearch上运行localhost端口9200 ,确保Kibana配置正确。
打开Kibana配置文件:
sudo vi /opt/kibana/config/kibana.yml
然后确保elasticsearch_url设置正确。
/opt/kibana/config/kibana.yml excerpt:# The Elasticsearch instance to use for all your queries.
elasticsearch_url: "http://localhost:9200"
保存并退出。
现在重新启动Kibana服务,将您的更改放置到位:
sudo service kibana restart
Kibana重新启动后,在Web浏览器中打开Kibana并验证错误是否已解决。
问题:Kibana不可访问
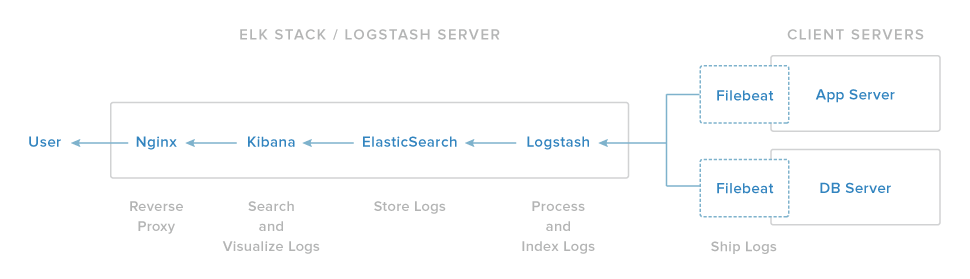
ELK的Nginx组件用作Kibana的反向代理。 如果Nginx未正确运行或配置,您将无法访问Kibana接口。 然而,由于其余的ELK组件不依赖于Nginx,它们可能很好地运行良好。
原因:Nginx不运行
如果Nginx没有运行,并且您尝试在Web浏览器中访问ELK,您可能会看到类似以下的错误:
Nginx Error:This webpage is not available
ERR_CONNECTION_REFUSED
这通常表明Nginx没有运行。
您可以使用此命令检查Nginx服务的状态:
sudo service nginx status
如果报告该服务未运行或不被认可,遵循的指示解决您的问题, 安装Nginx的部分麋鹿教程。 如果它报告服务正在运行,则需要按照相同的说明重新配置Nginx。
原因:Nginx正在运行,但无法连接到Kibana
如果Kibana无法访问,并且您收到一个502 Bad Gateway的错误,Nginx的运行,但它不能连接到Kibana。
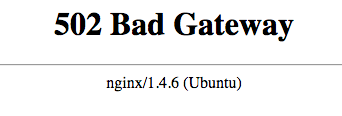
解决此问题的第一步是检查Kibana是否正在使用此命令运行:
sudo service kibana status
如果Kibana不运行或不被认可,遵循的指示安装Kibana部分麋鹿教程。
如果这不解决问题,您可能有与您的Nginx配置的问题。 你应该检讨的配置部分安装Nginx的部分麋鹿教程。 您可以检查Nginx错误日志的线索:
sudo tail /var/log/nginx/error.log
这应该告诉你为什么Nginx不能连接到Kibana。
原因:无法验证用户
如果您启用了基本身份验证,并且您无法通过身份验证步骤,则应查看Nginx错误日志以确定问题的具体情况。
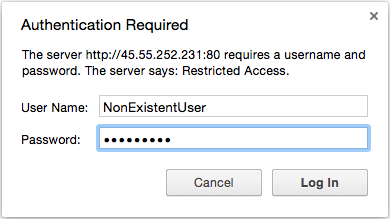
要查看最近的Nginx错误,请使用此命令:
sudo tail /var/log/nginx/error.log
如果你看到一个user was not found错误,用户不会在存在htpasswd文件。 此类型的错误由以下日志条目指示:
Nginx error logs (user was not found):2015/10/26 12:11:57 [error] 3933#0: *242 user "NonExistentUser" was not found in "/etc/nginx/htpasswd.users", client: 108.60.145.130, server: example.com, request: "GET / HTTP/1.1", host: "45.55.252.231"
如果你看到一个password mismatch错误,用户存在,但您提供的密码不正确。 此类型的错误由以下日志条目指示:
Nginx error logs (user password mismatch):2015/10/26 12:12:56 [error] 3933#0: *242 user "kibanaadmin": password mismatch, client: 108.60.145.130, server: example.com, request: "GET / HTTP/1.1", host: "45.55.252.231"
该决议,这两种错误是,要么提供适当的登录信息,或者修改现有htpasswd所预期存在用户登录文件。 例如,创建或覆盖被叫用户kibanaadmin在htpasswd.users文件,请使用以下命令:
sudo htpasswd /etc/nginx/htpasswd.users kibanaadmin
然后提供所需的密码,并确认。
如果你看到一个No such file or directory错误, htpasswd在Nginx的配置中指定的文件不存在。 此类型的错误由以下日志条目指示:
Nginx error logs (htpasswd file does not exist):2015/10/26 12:17:38 [error] 3933#0: *266 open() "/etc/nginx/htpasswd.users" failed (2: No such file or directory), client: 108.60.145.130, server: example.com, request: "GET / HTTP/1.1", host: "45.55.252.231"
在这里,你应该创建一个新/etc/nginx/htpasswd.users文件,添加一个用户( kibanaadmin在这个例子中)它,用这个命令:
sudo htpasswd -c /etc/nginx/htpasswd.users kibanaadmin
输入新密码,并进行确认。
现在,尝试以刚刚创建的用户身份验证。
Logstash:如何检查它是否正在运行
如果Logstash未运行,您将无法从日志发运器(如Logstash转发器)接收和解析日志,并将处理的日志存储在Elasticsearch中。 本节将告诉你如何检查Logstash是否正常工作。
验证服务正在运行
要检查的最基本的事情是Logstash状态的状态:
sudo service logstash status
如果Logstash正在运行,您将看到以下输出:
Logstash status (OK):logstash is running
否则,如果服务未运行,您将看到此消息:
Logstash status (Bad):logstash is not running
如果Logstash没有运行,请尝试使用以下命令启动它:
sudo service logstash start
然后在几秒钟后再次检查其状态。 Logstash是一个Java应用程序,它会在每次启动尝试后报告为“运行”几秒钟,因此在检查“未运行”状态之前等待几秒钟是很重要的。 如果它报告为“未运行”,它可能是配置错误。 接下来的两部分包括故障排除常见的Logstash问题。
问题:Logstash未运行
如果Logstash没有运行,则有几个潜在原因。 本节将讨论Logstash无法运行的各种常见情况,并提出潜在的解决方案。
原因:配置包含语法错误
如果Logstash在其配置文件,这位于错误/etc/logstash/conf.d目录,服务将不能正常启动。 最好的办法是检查Logstash日志,获取有关它为什么失败的线索。
打开到服务器的两个终端会话,以便在尝试启动服务时查看Logstash日志。
在第一个终端会话中,我们将查看日志:
tail -f /var/log/logstash/logstash.log
这将显示最近几个日志条目,以及任何未来的日志条目。
在第二个终端会话中,尝试启动Logstash服务:
sudo service logstash start
切换回第一个终端会话以查看在Logstash启动时生成的日志。
如果您看到包含错误消息的日志条目,请尝试阅读消息以找出出错的原因。 下面是一个错误日志示例,如果Logstash配置有语法错误(大括号不匹配),您可能会看到:
Logstash logs (Syntax error):...
{:timestamp=>"2015-10-28T11:51:09.205000-0400", :message=>"Error: Expected one of #, => at line 12, column 6 (byte 209) after input {\n lumberjack {\n port => 5043\n type => \"logs\"\n ssl_certificate => \"/etc/pki/tls/certs/logstash-forwarder.crt\"\n ssl_key => \"/etc/pki/tls/private/logstash-forwarder.key\"\n \n}\n\n\nfilter {\n if "}
{:timestamp=>"2015-10-28T11:51:09.228000-0400", :message=>"You may be interested in the '--configtest' flag which you can\nuse to validate logstash's configuration before you choose\nto restart a running system."}
最后一条消息说,我们可能有兴趣验证配置,表明配置包含语法错误。 以前的消息提供一个更具体的错误消息,在这种情况下,有一个在一个缺少右大括号input的结构的部分。 要解决此问题,请编辑Logstash配置的令人讨厌的部分:
sudo vi /etc/logstash/conf.d/01-lumberjack-input.conf
找到具有错误条目的行,并修复它,然后保存并退出。
现在,在第二个终端上,启动Logstash服务:
sudo service logstash start
如果问题已解决,应该没有新的日志条目(Logstash不记录成功的启动)。 几秒钟后,检查Logstash服务的状态:
sudo service logstash status
如果它正在运行,您已解决问题。
您可能有不同于我们的示例的配置问题。 我们将介绍一些其他常见的Logstash配置问题。 和往常一样,如果你能够弄清楚错误的含义,请尝试并自己修复。
原因:SSL文件不存在
Logstash未运行的另一个常见原因是SSL证书和密钥文件存在问题。 例如,如果它们不存在于Logstash配置指定的地方,您的日志将显示如下错误:
Logstash logs (SSL key file does not exist):{:timestamp=>"2015-10-28T14:29:07.311000-0400", :message=>"Invalid setting for lumberjack input plugin:\n\n input {\n lumberjack {\n # This setting must be a path\n # File does not exist or cannot be opened /etc/pki/tls/private/logstash-forwarder.key\n ssl_key => \"/etc/pki/tls/private/logstash-forwarder.key\"\n ...\n }\n }", :level=>:error}
{:timestamp=>"2015-10-28T14:29:07.339000-0400", :message=>"Error: Something is wrong with your configuration."}
{:timestamp=>"2015-10-28T14:29:07.340000-0400", :message=>"You may be interested in the '--configtest' flag which you can\nuse to validate logstash's configuration before you choose\nto restart a running system."}
要解决这个特定的问题,你需要确保你有一个SSL密钥文件( 生成一个 ,如果你忘了),并且它被放置在适当的位置( /etc/pki/tls/private/logstash-forwarder.key ,在该示例)。 如果您已经有一个密钥文件,请确保将其移动到正确的位置,并确保Logstash配置指向它。
现在,启动Logstash服务:
sudo service logstash start
如果问题已解决,则不应有新的日志条目。 几秒钟后,检查Logstash服务的状态:
sudo service logstash status
如果它正在运行,您已解决问题。
问题:Logstash正在运行,但不在Elasticsearch中存储日志
如果Logstash正在运行,但没有在Elasticsearch中存储日志,那是因为它无法到达Elasticsearch。 通常,这是Elasticsearch未运行的结果。 如果是这种情况,Logstash日志将显示如下所示的错误消息:
Logstash logs (Elasticsearch isn't running):{:timestamp=>"2015-10-28T14:46:35.355000-0400", :message=>"CircuitBreaker::rescuing exceptions", :name=>"Lumberjack input", :exception=>LogStash::SizedQueueTimeout::TimeoutError, :level=>:warn}
{:timestamp=>"2015-10-28T14:46:35.399000-0400", :message=>"Lumberjack input: The circuit breaker has detected a slowdown or stall in the pipeline, the input is closing the current connection and rejecting new connection until the pipeline recover.", :exception=>LogStash::CircuitBreaker::HalfOpenBreaker, :level=>:warn}
...
{:timestamp=>"2015-10-28T14:47:49.987000-0400", :message=>"Lumberjack input: the pipeline is blocked, temporary refusing new connection.", :level=>:warn}
...
在这种情况下,请确保Elasticsearch按照Elasticsearch故障排除步骤运行。
您可能还会看到如下错误:
Logstash logs (Logstash is configured to send its output to the wrong host):{:timestamp=>"2015-10-28T14:53:56.528000-0400", :message=>"Got error to send bulk of actions: blocked by: [SERVICE_UNAVAILABLE/1/state not recovered / initialized];[SERVICE_UNAVAILABLE/2/no master];", :level=>:error}
{:timestamp=>"2015-10-28T14:53:56.531000-0400", :message=>"Failed to flush outgoing items", :outgoing_count=>25, :exception=>"Java::OrgElasticsearchClusterBlock::ClusterBlockException", :backtrace=>["org.elasticsearch.cluster.block.ClusterBlocks.globalBlockedException(org/elasticsearch/cluster/block/ClusterBlocks.java:151)", "org.elasticsearch.cluster.block.ClusterBlocks.globalBlockedRaiseException(org/elasticsearch/cluster/block/ClusterBlocks.java:141)", "org.elasticsearch.action.bulk.TransportBulkAction.executeBulk(org/elasticsearch/action/bulk/TransportBulkAction.java:215)", "org.elasticsearch.action.bulk.TransportBulkAction.access$000(org/elasticsearch/action/bulk/TransportBulkAction.java:67)", "org.elasticsearch.action.bulk.TransportBulkAction$1.onFailure(org/elasticsearch/action/bulk/TransportBulkAction.java:153)", "org.elasticsearch.action.support.TransportAction$ThreadedActionListener$2.run(org/elasticsearch/action/support/TransportAction.java:137)", "java.util.concurrent.ThreadPoolExecutor.runWorker(java/util/concurrent/ThreadPoolExecutor.java:1142)", "java.util.concurrent.ThreadPoolExecutor$Worker.run(java/util/concurrent/ThreadPoolExecutor.java:617)", "java.lang.Thread.run(java/lang/Thread.java:745)"], :level=>:warn}
{:timestamp=>"2015-10-28T14:54:57.543000-0400", :message=>"Got error to send bulk of actions: blocked by: [SERVICE_UNAVAILABLE/1/state not recovered / initialized];[SERVICE_UNAVAILABLE/2/no master];", :level=>:error}
这表明output的Logstash配置的部分可以指向错误的主机。 要解决此问题,请确保Elasticsearch正在运行,并检查Logstash配置:
sudo vi /etc/logstash/conf.d/30-lumberjack-output.conf
验证elasticsearch { host => localhost }线指向运行Elasticsearch主机:
Logstash output configuration:output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
}
保存并退出。 此示例假设Elasticsearch上运行localhost 。
重新启动Logstash服务。
sudo service logstash restart
然后检查Logstash日志中是否有任何错误。
Logstash转发器:如何检查如果它正在运行
Logstash代理运行在客户端计算机,船舶记录到您的ELK服务器。 如果Logstash转发器未运行,您将无法将各种日志发送到Logstash。 因此,日志将不会存储在Elasticsearch中,并且它们不会显示在Kibana中。 本节将告诉您如何检查Logstash Forwarder是否正常工作。
验证日志已成功发货
告诉logstash转发器是否正确发送日志到Logstash的最简单的方法是检查其错误日志。 你可以看一下实时与该Logstash转发日志tail命令:
tail -f /var/log/logstash-forwarder/logstash-forwarder.err
如果一切设置正确,您应该看到如下日志条目:
Logstash Forwarder logs (Logs are successfully being shipped):2015/10/22 12:40:05.022748 Connecting to [10.132.102.48]:5043 (10.132.102.48)
2015/10/22 12:40:05.435781 Connected to 10.132.102.48
2015/10/22 12:40:10.990751 Setting trusted CA from file: /etc/pki/tls/certs/logstash-forwarder.crt
2015/10/22 12:40:10.991384 Connecting to [10.132.102.48]:5043 (10.132.102.48)
2015/10/22 12:40:11.132721 Connected to 10.132.102.48
2015/10/22 12:40:21.699062 Registrar: processing 1024 events
2015/10/22 12:40:25.003609 Registrar: processing 713 events
...
如果您看到Logstash转发器注册器正在处理事件,这意味着它将日志发送到Logstash。
如果没有看到任何日志条目,则应验证Logstash Forwarder是否正在运行。
验证服务正在运行
最基本的事情是检查Logstash转发器的状态:
sudo service logstash-forwarder status
如果Logstash Forwarder正在运行,您将看到以下输出:
Logstash-forwarder status (OK):logstash-forwarder is running
否则,如果服务未运行,您将看到此消息:
Logstash-forwarder status (Bad):logstash-forwarder is not running
如果Logstash转发器没有运行,请尝试使用以下命令启动它:
sudo service logstash-forwarder start
然后再次检查状态。 如果这不解决问题,以下部分将帮助您解决您的Logstash转发器问题。
在接下来的几节中,我们将讨论常见的Logstash Forwarder问题以及如何解决这些问题。
问题:Logstash转发器未运行
如果Logstash转发是不是你的客户端机器上运行,有几个可能的原因。 本节将讨论Logstash转发器无法运行的各种常见情况,并提出潜在的解决方案。
原因:配置包含语法错误
如果Logstash代理在其配置文件,它位于错误/etc/logstash-forwarder.conf ,该服务将不能正常启动。 最好的事情是检查Logstash转发器错误日志有关它为什么失败的线索:
tail /etc/logstash-forwarder.conf
如果看到如下所示的日志条目,则您的配置文件有语法错误:
Logstash-forwarder logs (Invalid):2015/10/28 17:20:25.047062 Failed unmarshalling json: invalid character '{' looking for beginning of object key string
2015/10/28 17:20:25.047084 Could not load config file /etc/logstash-forwarder.conf: invalid character '{' looking for beginning of object key string
在这种情况下,配置文件中有错字。 要解决此问题,请编辑Logstash配置的违规部分。 作为指导,遵循的配置Logstash货代款设立Logstash转发(添加客户端服务器)的ELK教程。
在编辑Logstash转发器配置后,尝试再次启动服务:
sudo service logstash-forwarder start
再次检查Logstash转发器日志,以确保问题已解决。
原因:SSL证书丢失或无效
Logstash转发器和Logstash之间的通信需要SSL证书,以进行身份验证和加密。 如果Logstash转发器没有正确启动,您应该检查Logstash转发器日志:
tail /var/log/logstash-forwarder/logstash-forwarder.err
如果运行Logstash代理客户机不具备Logstash SSL证书,你会看到日志如下条目:
Logstash-forwarder logs (logstash-forwarder.crt is missing):2015/10/28 16:48:27.388971 Setting trusted CA from file: /etc/pki/tls/certs/logstash-forwarder.crt
2015/10/28 16:48:27.389126 Failure reading CA certificate: open /etc/pki/tls/certs/logstash-forwarder.crt: no such file or directory
这表明logstash-forwarder.crt文件是不是在适当的位置。 要解决此问题,通过遵循适当的小节从ELK服务器的SSL证书复制到客户机设置Logstash转发(添加客户端服务器)部分的ELK教程。
将适当的SSL证书文件放置在正确的位置后,请再次尝试启动Logstash Forwarder。
如果SSL证书无效,日志应如下所示:
Logstash-forwarder logs (Certificate is invalid):2015/10/22 12:39:52.989385 Connecting to [10.132.102.48]:5043 (10.132.102.48)
2015/10/22 12:39:53.010214 Failed to tls handshake with 10.132.102.48 x509: certificate is valid for 10.17.0.52, not 10.132.102.48
请注意,错误消息指示证书存在,但是它使用错误的IP地址创建(证书是针对与ELK服务器不匹配的IP地址)。 在这种情况下,你需要按照生成SSL证书部分麋鹿教程,然后复制SSL证书的客户机( 建立Logstash转发(添加客户端服务器) )。
确保证书有效并且位于正确的位置后,您需要重新启动Logstash(在ELK服务器上)以强制使用新的SSL密钥:
sudo service logstash restart
然后启动Logstash Forwarder(在客户端计算机上):
sudo service logstash-forwarder start
再次检查Logstash转发器日志,以确保问题已解决。
问题:Logstash转发器无法连接到Logstash
如果Logstash转发器(您的客户端服务器)无法访问Logstash(在ELK服务器上),您将看到如下所示的错误日志条目:
Logstash-forwarder logs (Connection refused):2015/10/22 12:39:54.010719 Connecting to [10.132.102.48]:5043 (10.132.102.48)
2015/10/22 12:39:54.011269 Failure connecting to 10.132.102.48: dial tcp 10.132.102.48:5043: connection refused
Logstash不可达的常见原因包括:
- Logstash未运行(在ELK服务器上)
- 无论是服务器上的防火墙阻塞端口的连接
5043 - Logstash转发器未配置正确的IP地址,主机名或端口
要解决此问题,请首先按照本指南的Logstash故障排除部分验证Logstash是否正在ELK服务器上运行。 第二,验证防火墙是否阻止网络流量。 第三,验证Logstash转发器配置了正确的ELK服务器的IP地址(或主机名)和端口。
可以使用此命令编辑Logstash转发器配置:
sudo vi /etc/logstash-forwarder.conf
验证Logstash连接信息正确后,尝试重新启动Logstash转发器:
sudo service logstash-forwarder restart
再次检查Logstash转发器日志,以确保问题已解决。
对于一般Logstash代理的指导,遵循的配置Logstash货代款设立Logstash转发(添加客户端服务器)的ELK教程。
Elasticsearch:如何检查它是否正在运行
如果Elasticsearch没有运行,您的ELK都不会运行。 Logstash将无法向Elasticsearch添加新日志,Kibana将无法从Elasticsearch检索用于报告的日志。 本节将告诉您如何检查Elasticsearch是否正常工作。
验证服务正在运行
要检查的最基本的事情是Elasticsearch状态的状态:
sudo service elasticsearch status
如果Elasticsearch正在运行,您将看到以下输出:
Elasticsearch status (OK): * elasticsearch is running
否则,如果服务未运行,您将看到此消息:
Elasticsearch status (Bad): * elasticsearch is not running
在这种情况下,您应该按照接下来的几个部分,其中包括对Elasticsearch进行故障排除。
验证它响应HTTP请求
默认情况下,Elasticsearch响应HTTP端口请求9200 (这可以定制,在它的配置文件,通过指定新http.port值)。 我们可以使用curl发送请求,并从那里Elasticsearch获取有用的信息。
使用curl使用此命令(假设你的Elasticsearch可在到达发送一个HTTP GET请求localhost ):
curl localhost:9200
如果Elasticsearch正在运行,您应该看到如下所示的响应:
curl localhost:9200 output:{
"status" : 200,
"name" : "Fan Boy",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.7.3",
"build_hash" : "05d4530971ef0ea46d0f4fa6ee64dbc8df659682",
"build_timestamp" : "2015-10-15T09:14:17Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}
您还可以使用此命令检查Elasticsearch集群的运行状况:
curl localhost:9200/_cluster/health?pretty
你的输出应该是这样:
curl localhost:9200/_cluster/health?pretty output:{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 56,
"active_shards" : 56,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 56,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0
}
请注意,如果您Elasticsearch群集由单个节点,群集将可能有一个yellow状态。 这对于单节点集群是正常的; 你可以升级到一个green加入至少一个多节点的集群Elasticsearch状态。
问题:Elasticsearch未运行
如果Elasticsearch没有运行,则有很多潜在原因。 本节将介绍Elasticsearch无法运行的各种常见情况,并提出潜在的解决方案。
原因:它从未启动
如果Elasticsearch没有运行,它可能没有在第一个地方启动; Elasticsearch在安装后不会自动启动。 解决方案是手动启动它第一次:
sudo service elasticsearch start
这应该报告Elasticsearch正在开始。 等待大约10秒钟,然后再次检查Elasticsearch状态。
原因:未启用Elasticsearch服务,并且服务器已重新启动
如果Elasticsearch工作正常,但不工作了,这可能是你的问题。 默认情况下,Elasticsearch服务未启用在启动时启动。 解决方案意味着您必须启用Elasticsearch在启动时自动启动:
sudo update-rc.d elasticsearch defaults 95 10
Elasticsearch现在应该在引导时自动启动。 通过重新启动服务器来测试它是否工作。
原因:Elasticsearch配置错误
如果Elasticsearch在它的配置文件,该文件位于错误/etc/elasticsearch/elasticsearch.yml ,该服务将不能正常启动。 最好的办法是检查Elasticsearch错误日志,以了解它为什么失败的线索。
打开服务器的两个终端会话,以便在尝试启动服务时查看Elasticsearch日志。
在第一个终端会话中,我们将查看日志:
tail -f /var/log/elasticsearch/elasticsearch.log
这将显示最近几个日志条目,以及任何未来的日志条目。
在第二个终端会话中,尝试启动Elasticsearch服务:
sudo service elasticsearch start
切换回第一个终端会话以查看在Elasticsearch启动时生成的日志。
如果您看到日志显示错误或异常(如输入ERROR , Exception或error ),试图找到一条线,表明是什么原因造成的错误。 以下是错误日志如果Elasticsearch你会看到的一个例子network.host设置为无法解析主机名或IP地址:
Elasticsearch logs (Bad):...
[2015-10-27 15:24:43,495][INFO ][node ] [Shadrac] starting ...
[2015-10-27 15:24:43,626][ERROR][bootstrap ] [Shadrac] Exception
org.elasticsearch.transport.BindTransportException: Failed to resolve host [null]
at org.elasticsearch.transport.netty.NettyTransport.bindServerBootstrap(NettyTransport.java:402)
at org.elasticsearch.transport.netty.NettyTransport.doStart(NettyTransport.java:283)
at org.elasticsearch.common.component.AbstractLifecycleComponent.start(AbstractLifecycleComponent.java:85)
at org.elasticsearch.transport.TransportService.doStart(TransportService.java:153)
at org.elasticsearch.common.component.AbstractLifecycleComponent.start(AbstractLifecycleComponent.java:85)
at org.elasticsearch.node.internal.InternalNode.start(InternalNode.java:257)
at org.elasticsearch.bootstrap.Bootstrap.start(Bootstrap.java:160)
at org.elasticsearch.bootstrap.Bootstrap.main(Bootstrap.java:248)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:32)
Caused by: java.net.UnknownHostException: incorrect_hostname: unknown error
...
注意,该实施例的日志的最后一行表示一个UnknownHostException: incorrect_hostname错误发生。 这个特殊的例子表明network.host设为incorrect_hostname ,这不能解决任何东西。 在单节点Elasticsearch设置,这应设置为localhost或127.0.0.1 。
要解决此问题,请编辑Elasticsearch配置文件:
sudo vi /etc/elasticsearch/elasticsearch.yml
找到具有错误条目的行,并修复它。 在这个例子中的情况下,我们应该寻找指定行network.host: incorrect_hostname并改变它,所以它看起来是这样的:
...
network.host: localhost
...
保存并退出。
现在,在第二个终端上,启动Elasticsearch服务:
sudo service elasticsearch start
如果问题已解决,您应该看到无错误的日志,指示Elasticsearch已经启动。 它可能看起来像这样:
Elasticsearch logs (Good):...
[2015-10-27 15:29:21,980][INFO ][node ] [Garrison Kane] initializing ...
[2015-10-27 15:29:22,084][INFO ][plugins ] [Garrison Kane] loaded [], sites []
[2015-10-27 15:29:22,124][INFO ][env ] [Garrison Kane] using [1] data paths, mounts [[/ (/dev/vda1)]], net usable_space [52.1gb], net total_space [58.9gb], types [ext4]
[2015-10-27 15:29:24,532][INFO ][node ] [Garrison Kane] initialized
[2015-10-27 15:29:24,533][INFO ][node ] [Garrison Kane] starting ...
[2015-10-27 15:29:24,646][INFO ][transport ] [Garrison Kane] bound_address {inet[/127.0.0.1:9300]}, publish_address {inet[localhost/127.0.0.1:9300]}
[2015-10-27 15:29:24,682][INFO ][discovery ] [Garrison Kane] elasticsearch/WJvkRFnbQ5mLTgOatk0afQ
[2015-10-27 15:29:28,460][INFO ][cluster.service ] [Garrison Kane] new_master [Garrison Kane][WJvkRFnbQ5mLTgOatk0afQ][elk-run][inet[localhost/127.0.0.1:9300]], reason: zen-disco-join (elected_as_master)
[2015-10-27 15:29:28,561][INFO ][http ] [Garrison Kane] bound_address {inet[/127.0.0.1:9200]}, publish_address {inet[localhost/127.0.0.1:9200]}
[2015-10-27 15:29:28,562][INFO ][node ] [Garrison Kane] started
...
现在如果你检查Elasticsearch状态,你应该看到它运行良好。
您可能有不同于我们的示例的配置问题。 如果你能够弄清楚错误的含义,请尝试自己修复。 If that fails, try and search the Internet for individual error lines that do not contain information that is specific to your server (eg the IP address, or the automatically generated Elasticsearch node name).
结论
Hopefully this troubleshooting guide has helped you resolve any issues you were having with your ELK stack setup. If you have any questions or suggestions, leave them in the comments below!







