合作编写与MemSQL
介绍
MemSQL是一种内存数据库,可以比传统数据库提供更快的读取和写入速度。 即使它是一种新技术,它说MySQL协议,所以它感觉非常熟悉的工作。
MemSQL已经拥有MySQL的最新功能,具有现代功能,例如JSON支持和上升数据的能力。 之一的MemSQL对MySQL的最大优点是它能够在多个节点拆分单个查询能力,被称为大规模并行处理 ,这导致更快的读查询。
在本教程中,我们将在单个Ubuntu 14.04服务器上安装MemSQL,运行性能基准测试,并通过命令行MySQL客户端插入JSON数据。
先决条件
要遵循本教程,您需要:
一个Ubuntu 14.04 x64 Droplet至少有8 GB RAM
使用sudo的特权,非root用户,您可以通过下面的设置与Ubuntu 14.04初始服务器设置教程
第1步 - 安装MemSQL
在本节中,我们将为MemSQL安装准备我们的工作环境。
MemSQL的最新版本已被列入他们的下载页面 。 我们将下载并安装MemSQL Ops,这是一个管理下载和准备服务器以正确运行MemSQL的程序。 在撰写本文时,MemSQL Ops的最新版本是4.0.35。
首先,从他们的网站下载MemSQL的安装包文件。
wget http://download.memsql.com/memsql-ops-4.0.35/memsql-ops-4.0.35.tar.gz
接下来,解压缩包。
tar -xzf memsql-ops-4.0.35.tar.gz
提取包创建了一个文件夹,名为memsql-ops-4.0.35 。 请注意,文件夹名称具有版本号,因此如果您下载的版本高于本教程指定的版本号,您将有一个包含您下载的版本的文件夹。
将目录更改为此文件夹。
cd memsql-ops-4.0.35
然后,运行安装脚本,这是我们刚刚提取的安装包的一部分。
sudo ./install.sh
您将看到脚本的一些输出。 过一会儿,它会问你是否只在这个主机上安装MemSQL。 我们将在未来的教程中考虑在多个机器上安装MemSQL。 因此,对于本教程的目的,我们说的是输入y。
. . .
Do you want to install MemSQL on this host only? [y/N] y
2015-09-04 14:30:38: Jd0af3b [INFO] Deploying MemSQL to 45.55.146.81:3306
2015-09-04 14:30:38: J4e047f [INFO] Deploying MemSQL to 45.55.146.81:3307
2015-09-04 14:30:48: J4e047f [INFO] Downloading MemSQL: 100.00%
2015-09-04 14:30:48: J4e047f [INFO] Installing MemSQL
2015-09-04 14:30:49: Jd0af3b [INFO] Downloading MemSQL: 100.00%
2015-09-04 14:30:49: Jd0af3b [INFO] Installing MemSQL
2015-09-04 14:31:01: J4e047f [INFO] Finishing MemSQL Install
2015-09-04 14:31:03: Jd0af3b [INFO] Finishing MemSQL Install
Waiting for MemSQL to start...
现在你有一个MemSQL集群部署到你的Ubuntu服务器! 但是,从上面的日志,你会注意到MemSQL安装了两次。
MemSQL可以作为两个不同的角色运行:聚合器节点和叶节点。 MemSQL安装两次的原因是它需要至少一个聚合节点和至少一个叶节点来运行集群。
汇聚节点的接口MemSQL。 对外部世界来说,它看起来很像MySQL:它监听同一个端口,你可以连接希望谈论MySQL和标准MySQL库的工具。 聚合器的工作是了解所有MemSQL叶节点,处理MySQL客户端,并将其查询转换为MemSQL。
叶节点实际存储的数据。 当叶节点从聚合器节点接收到读取或写入数据的请求时,其执行该查询并将结果返回到聚合器节点。 MemSQL允许您跨多个主机共享数据,每个叶节点具有该数据的一部分。 (即使使用单个叶节点,您的数据也会在该叶节点中分割。)
当有多个叶节点时,聚合器负责将MySQL查询翻译成应该参与该查询的所有叶节点。 然后它接收来自所有叶节点的响应,并将结果聚合到一个返回到MySQL客户端的查询中。 这是如何管理并行查询。
我们的单主机设置使聚合器和叶节点运行在同一台机器上,但您可以在许多其他机器上添加更多叶节点。
第2步 - 运行基准
让我们看看MemSQL可以通过使用MemSQL Ops工具来操作的速度,MemSQL Ops工具是作为MemSQL安装脚本的一部分安装的。
在Web浏览器,去http:// your_server_ip :9000
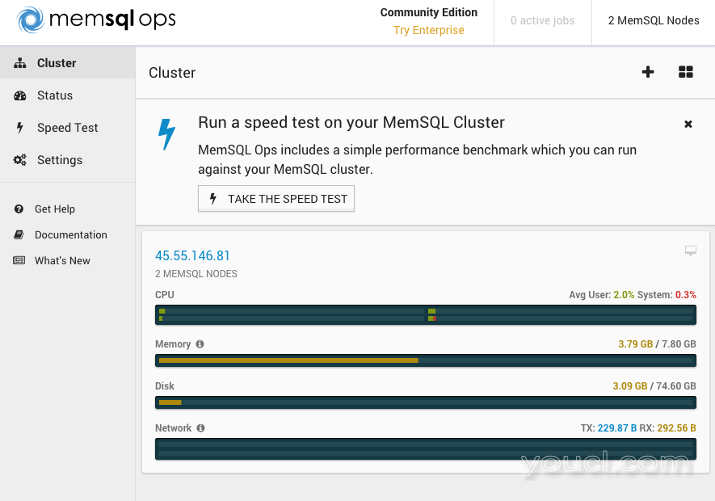
MemSQL Ops工具提供了集群的概述。 我们有2个MemSQL节点:主聚合器和叶节点。
让我们在我们的单机MemSQL节点上进行速度测试。 从左侧的菜单中点击速度测试 ,然后单击开始测试 。 以下是您可能会看到的结果示例:
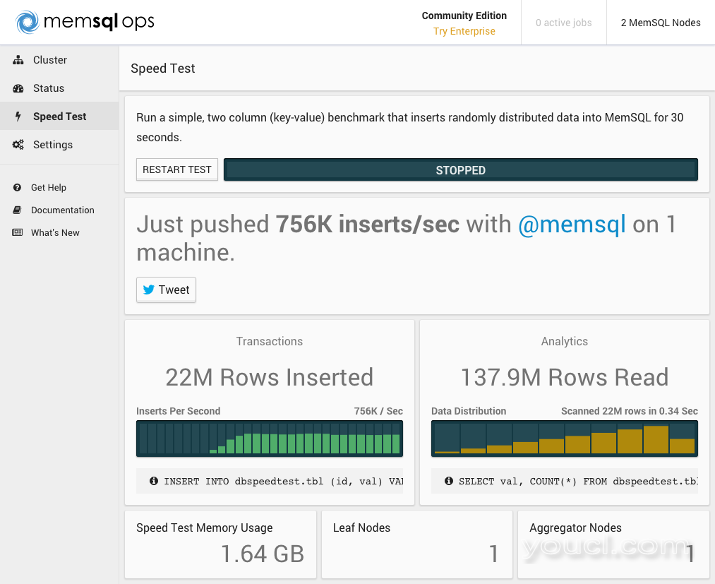
我们不会在本教程中介绍如何在多个服务器上安装MemSQL,但是为了比较,这里是一个MemSQL集群的基准测试,它有三个8GB的Ubuntu 14.04节点(一个聚合节点和两个叶节点):
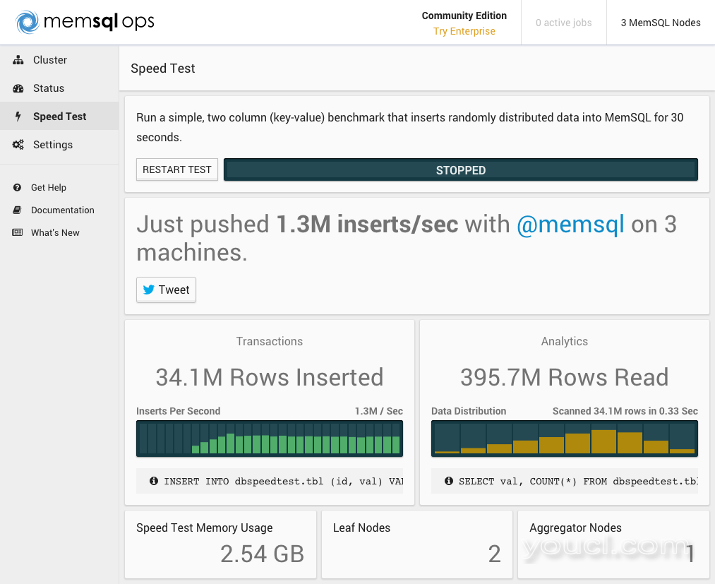
通过使叶节点的数目加倍,我们能够将我们的插入速率几乎加倍。 通过查看读取的行数的部分,我们可以看到,我们的三个节点集群能够比在同样的时间内单节点集群同时读取12M多行。
第3步 - 通过mysql-client与MemSQL交互
对于客户端,MemSQL看起来像MySQL; 他们都说同样的协议。 要开始与我们的MemSQL集群交谈,让我们安装一个mysql-client。
首先,更新apt,以便我们在下一步安装最新的客户端。
sudo apt-get update
现在,安装一个MySQL客户端。 这将为我们提供一个mysql命令来执行。
sudo apt-get install mysql-client-core-5.6
我们现在准备使用MySQL客户端连接到MemSQL。 我们要以root用户主机连接127.0.0.1端口3306(这是我们本地主机的IP地址),我们还将自定义提示消息, memsql>
mysql -u root -h 127.0.0.1 -P 3306 --prompt="memsql> "
你会看到输出的几行随后memsql>提示符。
让我们列出数据库。
show databases;
你会看到这个输出。
+--------------------+
| Database |
+--------------------+
| information_schema |
| memsql |
| sharding |
+--------------------+
3 rows in set (0.01 sec)
创建一个名为教程新的数据库。
create database tutorial;
然后切换到使用新的数据库与use命令。
use tutorial;
接下来,我们将创建一个users表,将有id的一个email领域。 我们必须为这两个字段指定一个类型。 让我们ID的BIGINT并通过电子邮件发送一个varchar与255的长度我们还将告诉大家,数据库id字段是主键和email字段不能为空。
create table users (id bigint auto_increment primary key, email varchar(255) not null);
您可能会注意到最后一个命令的执行时间很差(15 - 20秒)。 有一个主要原因为什么MemSQL缓慢创建这个新表:代码生成。
引擎盖下,MemSQL使用代码生成执行查询。 这意味着任何时候遇到一种新的查询类型,MemSQL需要生成和编译代表查询的代码。 然后将此代码发送到群集以供执行。 这加快了处理实际数据的速度,但是有准备的成本。 MemSQL可以重用预生成的查询,但是结构从未见过的新查询将会减慢。
回到我们的users表,看看表定义。
describe users;
+-------+--------------+------+------+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+------+---------+----------------+
| id | bigint(20) | NO | PRI | NULL | auto_increment |
| email | varchar(255) | NO | | NULL | |
+-------+--------------+------+------+---------+----------------+
2 rows in set (0.00 sec)
现在,让我们在users表中插入一些例子电子邮件。 此语法与我们可能用于MySQL数据库的语法相同。
insert into users (email) values ('one@example.com'), ('two@example.com'), ('three@example.com');
Query OK, 3 rows affected (1.57 sec)
Records: 3 Duplicates: 0 Warnings: 0
现在查询users表。
select * from users;
您可以查看我们刚刚输入的数据:
+----+-------------------+
| id | email |
+----+-------------------+
| 2 | two@example.com |
| 1 | one@example.com |
| 3 | three@example.com |
+----+-------------------+
3 rows in set (0.07 sec)
第4步 - 插入和查询JSON
MemSQL提供了一个JSON类型,因此在这一步中,我们将创建一个事件表以利用传入的事件。 该表将有一个id字段(像我们一样为用户)和一个event场,这将是一个JSON类型。
create table events (id bigint auto_increment primary key, event json not null);
让我们插入几个事件。 内JSON,我们将引用email领域,反过来,引用回我们在第3步中插入的用户的ID。
insert into events (event) values ('{"name": "sent email", "email": "one@example.com"}'), ('{"name": "received email", "email": "two@example.com"}');
现在我们可以看看我们刚刚插入的事件。
select * from events;
+----+-----------------------------------------------------+
| id | event |
+----+-----------------------------------------------------+
| 2 | {"email":"two@example.com","name":"received email"} |
| 1 | {"email":"one@example.com","name":"sent email"} |
+----+-----------------------------------------------------+
2 rows in set (3.46 sec)
接下来,我们可以查询其JSON的所有事件name属性是文本“接收的电子邮件”。
select * from events where event::$name = 'received email';
+----+-----------------------------------------------------+
| id | event |
+----+-----------------------------------------------------+
| 2 | {"email":"two@example.com","name":"received email"} |
+----+-----------------------------------------------------+
1 row in set (5.84 sec)
尝试改变该查询寻找那些name属性为“发送的电子邮件”的文字。
select * from events where event::$name = 'sent email';
+----+-------------------------------------------------+
| id | event |
+----+-------------------------------------------------+
| 1 | {"email":"one@example.com","name":"sent email"} |
+----+-------------------------------------------------+
1 row in set (0.00 sec)
这个最新的查询运行得比上一个快得多。 这是因为我们只改变了查询中的一个参数,所以MemSQL能够跳过代码生成。
让我们为分布式SQL数据库做一些高级操作:让我们在非主键上连接两个表,其中连接的一个值嵌套在一个JSON值中,但是对不同的JSON值进行过滤。
首先,我们将通过匹配电子邮件(其中事件名称为“收到电子邮件”)请求用户表中包含事件表的所有字段。
select * from users left join events on users.email = events.event::$email where events.event::$name = 'received email';
+----+-----------------+------+-----------------------------------------------------+
| id | email | id | event |
+----+-----------------+------+-----------------------------------------------------+
| 2 | two@example.com | 2 | {"email":"two@example.com","name":"received email"} |
+----+-----------------+------+-----------------------------------------------------+
1 row in set (14.19 sec)
接下来,尝试同样的查询,但过滤只有“发送电子邮件”事件。
select * from users left join events on users.email = events.event::$email where events.event::$name = 'sent email';
+----+-----------------+------+-------------------------------------------------+
| id | email | id | event |
+----+-----------------+------+-------------------------------------------------+
| 1 | one@example.com | 1 | {"email":"one@example.com","name":"sent email"} |
+----+-----------------+------+-------------------------------------------------+
1 row in set (0.01 sec)
像之前一样,第二个查询比第一个查询快得多。 代码生成的好处在执行超过数百万行时有效,正如我们在基准测试中看到的。 使用横向扩展SQL数据库的灵活性是理解JSON和如何任意连接表的一个强大的用户功能。
结论
您已安装MemSQL,运行节点性能的基准,通过标准MySQL客户端与您的节点交互,并使用MySQL中未找到的一些高级功能。 这应该是一个内存中的SQL数据库可以为你做的好味道。
还有很多余地要了解MemSQL如何实际分配数据,如何构建表以实现最佳性能,如何在多个节点上扩展MemSQL,如何为高可用性复制数据以及如何保护MemSQL。







