Hadoop是被Apache处理大数据开发的开源编程框架。 它使用HDFS(Hadoop分布式文件系统 ),以在所有数据节点的数据存储在集群中的分布方式和MapReduce模型来处理数据。

安装Hadoop多节点集群
的NameNode(NN)是一个主守护进程控制HDFS和的JobTracker(JT)是MapReduce的发动机主守护进程。
要求
在本教程中,我用两个CentOS的6.3虚拟机“ 主 ”和“ 节点 ”即。 (主节点和节点是我的主机名)。 “主”IP为172.21.17.175和节点IP为“172.21.17.188”。 以下说明也适用于RHEL / CentOS的6.x的版本。
在主
[root@master ~]# hostname master
[root@master ~]# ifconfig|grep 'inet addr'|head -1 inet addr:172.21.17.175 Bcast:172.21.19.255 Mask:255.255.252.0
节点上
[root@node ~]# hostname node
[root@node ~]# ifconfig|grep 'inet addr'|head -1 inet addr:172.21.17.188 Bcast:172.21.19.255 Mask:255.255.252.0
首先确保所有群集主机是否有“/ etc / hosts中 ”文件(每个节点上),如果你没有DNS的设置都做。
在主
[root@master ~]# cat /etc/hosts 172.21.17.175 master 172.21.17.188 node
节点上
[root@node ~]# cat /etc/hosts 172.21.17.197 qabox 172.21.17.176 ansible-ground
在CentOS中安装Hadoop Multinode集群
我们使用官方CDH库在集群中的所有主机(主和节点)安装CDH4。
第1步:下载安装CDH存储库
去官方CDH下载页面,抢CDH4(即4.6)版本,也可以使用下面的wget命令下载库并安装它。
在RHEL / CentOS 32位上
# wget http://archive.cloudera.com/cdh4/one-click-install/redhat/6/i386/cloudera-cdh-4-0.i386.rpm # yum --nogpgcheck localinstall cloudera-cdh-4-0.i386.rpm
在RHEL / CentOS 64位上
# wget http://archive.cloudera.com/cdh4/one-click-install/redhat/6/x86_64/cloudera-cdh-4-0.x86_64.rpm # yum --nogpgcheck localinstall cloudera-cdh-4-0.x86_64.rpm
在安装Hadoop Multinode集群之前,请根据系统架构,通过运行以下命令之一将Cloudera公用GPG密钥添加到存储库。
## on 32-bit System ## # rpm --import http://archive.cloudera.com/cdh4/redhat/6/i386/cdh/RPM-GPG-KEY-cloudera
## on 64-bit System ## # rpm --import http://archive.cloudera.com/cdh4/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera
第2步:设置JobTracker和NameNode
接下来,运行以下命令在主服务器上安装和设置JobTracker和NameNode。
[root@master ~]# yum clean all [root@master ~]# yum install hadoop-0.20-mapreduce-jobtracker
[root@master ~]# yum clean all [root@master ~]# yum install hadoop-hdfs-namenode
第3步:设置辅助名称节点
再次,在主服务器上运行以下命令以设置辅助名称节点。
[root@master ~]# yum clean all [root@master ~]# yum install hadoop-hdfs-secondarynam
第4步:设置Tasktracker和Datanode
接下来,在除JobTracker,NameNode和辅助节点(或备用节点)NameNode主机(在本例中为节点)之外的所有群集主机(节点)上设置tasktracker和datanode。
[root@node ~]# yum clean all [root@node ~]# yum install hadoop-0.20-mapreduce-tasktracker hadoop-hdfs-datanode
第5步:设置Hadoop客户端
您可以在单独的机器上安装Hadoop客户端(在这种情况下,我已将其安装在datanode上,您可以将其安装在任何机器上)。
[root@node ~]# yum install hadoop-client
第6步:在节点上部署HDFS
现在,如果我们完成了上面的步骤,我们继续部署hdfs(要在所有节点上完成)。
复制默认配置到/ etc / Hadoop的目录(在集群的每个节点上)。
[root@master ~]# cp -r /etc/hadoop/conf.dist /etc/hadoop/conf.my_cluster
[root@node ~]# cp -r /etc/hadoop/conf.dist /etc/hadoop/conf.my_cluster
使用替代命令来设置自定义的目录,(在群集中的每个节点上),如下所示。
[root@master ~]# alternatives --verbose --install /etc/hadoop/conf hadoop-conf /etc/hadoop/conf.my_cluster 50 reading /var/lib/alternatives/hadoop-conf [root@master ~]# alternatives --set hadoop-conf /etc/hadoop/conf.my_cluster
[root@node ~]# alternatives --verbose --install /etc/hadoop/conf hadoop-conf /etc/hadoop/conf.my_cluster 50 reading /var/lib/alternatives/hadoop-conf [root@node ~]# alternatives --set hadoop-conf /etc/hadoop/conf.my_cluster
第7步:自定义配置文件
现在,在集群中的每个节点上打开“ 核心-site.xml中 ”文件和更新“fs.defaultFS”。
[root@master conf]# cat /etc/hadoop/conf/core-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master/</value> </property> </configuration>
[root@node conf]# cat /etc/hadoop/conf/core-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master/</value> </property> </configuration>
集群中的每个节点在下次更新“dfs.permissions.superusergroup”在HDFS-site.xml中 。
[root@master conf]# cat /etc/hadoop/conf/hdfs-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.name.dir</name> <value>/var/lib/hadoop-hdfs/cache/hdfs/dfs/name</value> </property> <property> <name>dfs.permissions.superusergroup</name> <value>hadoop</value> </property> </configuration>
[root@node conf]# cat /etc/hadoop/conf/hdfs-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.name.dir</name> <value>/var/lib/hadoop-hdfs/cache/hdfs/dfs/name</value> </property> <property> <name>dfs.permissions.superusergroup</name> <value>hadoop</value> </property> </configuration>
注意 :请确认,上述配置是目前所有节点(做一个节点,运行SCP上的其余节点复制)上。
第8步:配置本地存储目录
在NameNode(在主节点和节点上)的“hdfs-site.xml”中更新“dfs.name.dir或dfs.namenode.name.dir”。 请更改突出显示的值。
[root@master conf]# cat /etc/hadoop/conf/hdfs-site.xml
<property> <name>dfs.namenode.name.dir</name> <value>file:///data/1/dfs/nn,/nfsmount/dfs/nn</value> </property>
[root@node conf]# cat /etc/hadoop/conf/hdfs-site.xml
<property> <name>dfs.datanode.data.dir</name> <value>file:///data/1/dfs/dn,/data/2/dfs/dn,/data/3/dfs/dn</value> </property>
第9步:创建目录和管理权限
执行以下命令创建目录结构并管理Namenode(主)和Datanode(Node)机器上的用户权限。
[root@master]# mkdir -p /data/1/dfs/nn /nfsmount/dfs/nn [root@master]# chmod 700 /data/1/dfs/nn /nfsmount/dfs/nn
[root@node]# mkdir -p /data/1/dfs/dn /data/2/dfs/dn /data/3/dfs/dn /data/4/dfs/dn [root@node]# chown -R hdfs:hdfs /data/1/dfs/nn /nfsmount/dfs/nn /data/1/dfs/dn /data/2/dfs/dn /data/3/dfs/dn /data/4/dfs/dn
通过发出以下命令格式化Namenode(在主机上)。
[root@master conf]# sudo -u hdfs hdfs namenode -format
第10步:配置Secondary NameNode
下面的属性添加到HDFS-site.xml文件和主如图所示取代的价值。
<property> <name>dfs.namenode.http-address</name> <value>172.21.17.175:50070</value> <description> The address and port on which the NameNode UI will listen. </description> </property>
注 :在我们的例子值应该是主虚拟机的IP地址。
现在让我们部署MRv1(Map-reduce版本1)。 打开“mapred-site.xml中 '文件,如下面的值。
[root@master conf]# cp hdfs-site.xml mapred-site.xml [root@master conf]# vi mapred-site.xml [root@master conf]# cat mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapred.job.tracker</name> <value>master:8021</value> </property> </configuration>
接着,使用以下scp命令'mapred-site.xml中 '文件复制到节点机。
[root@master conf]# scp /etc/hadoop/conf/mapred-site.xml node:/etc/hadoop/conf/ mapred-site.xml 100% 200 0.2KB/s 00:00
现在配置由MRv1 Daemon使用的本地存储目录。 如下图所示每个TaskTracker共同再次打开“mapred-site.xml中 '文件并进行更改。
<property> Â <name>mapred.local.dir</name> Â <value>/data/1/mapred/local,/data/2/mapred/local,/data/3/mapred/local</value> </property>
在“mapred-site.xml中 ”文件中指定这些目录后,必须创建目录并分配集群中的每个节点上正确的文件权限给他们。
mkdir -p /data/1/mapred/local /data/2/mapred/local /data/3/mapred/local /data/4/mapred/local chown -R mapred:hadoop /data/1/mapred/local /data/2/mapred/local /data/3/mapred/local /data/4/mapred/local
第10步:启动HDFS
现在运行以下命令在集群中的每个节点上启动HDFS。
[root@master conf]# for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done
[root@node conf]# for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done
第1步1:创建HDFS / tmp和MapReduce / var目录
这需要创建下面正是因为提到适当的权限/ tmp中 。
[root@master conf]# sudo -u hdfs hadoop fs -mkdir /tmp [root@master conf]# sudo -u hdfs hadoop fs -chmod -R 1777 /tmp
[root@master conf]# sudo -u hdfs hadoop fs -mkdir -p /var/lib/hadoop-hdfs/cache/mapred/mapred/staging [root@master conf]# sudo -u hdfs hadoop fs -chmod 1777 /var/lib/hadoop-hdfs/cache/mapred/mapred/staging [root@master conf]# sudo -u hdfs hadoop fs -chown -R mapred /var/lib/hadoop-hdfs/cache/mapred
现在验证HDFS文件结构。
[root@node conf]# sudo -u hdfs hadoop fs -ls -R / drwxrwxrwt - hdfs hadoop 0 2014-05-29 09:58 /tmp drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 /var drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 /var/lib drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs drwxr-xr-x - hdfs hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache drwxr-xr-x - mapred hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred drwxr-xr-x - mapred hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred/mapred drwxrwxrwt - mapred hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred/mapred/staging
你启动后HDFS和创建“/ tmp目录 ”,但在启动前的JobTracker请建立由“mapred.system.dir”参数中指定的HDFS目录(默认为$ {} hadoop.tmp.dir / mapred /系统及变化所有者映射。
[root@master conf]# sudo -u hdfs hadoop fs -mkdir /tmp/mapred/system [root@master conf]# sudo -u hdfs hadoop fs -chown mapred:hadoop /tmp/mapred/system
第1步2:启动MapReduce
要启动MapReduce:请启动TT和JT服务。
在每个TaskTracker系统上
[root@node conf]# service hadoop-0.20-mapreduce-tasktracker start Starting Tasktracker: [ OK ] starting tasktracker, logging to /var/log/hadoop-0.20-mapreduce/hadoop-hadoop-tasktracker-node.out
在JobTracker系统上
[root@master conf]# service hadoop-0.20-mapreduce-jobtracker start Starting Jobtracker: [ OK ] starting jobtracker, logging to /var/log/hadoop-0.20-mapreduce/hadoop-hadoop-jobtracker-master.out
接下来,为每个hadoop用户创建一个主目录。 建议您在NameNode上执行此操作; 例如。
[root@master conf]# sudo -u hdfs hadoop fs -mkdir /user/<user> [root@master conf]# sudo -u hdfs hadoop fs -chown <user> /user/<user>
注 :其中 是每个用户的Linux用户名。
或者,您可以如下创建主目录。
[root@master conf]# sudo -u hdfs hadoop fs -mkdir /user/$USER [root@master conf]# sudo -u hdfs hadoop fs -chown $USER /user/$USER
第1步3:从浏览器中打开JT,NN UI
打开浏览器,键入URL作为HTTP:// ip_address_of_namenode:50070访问的Namenode。
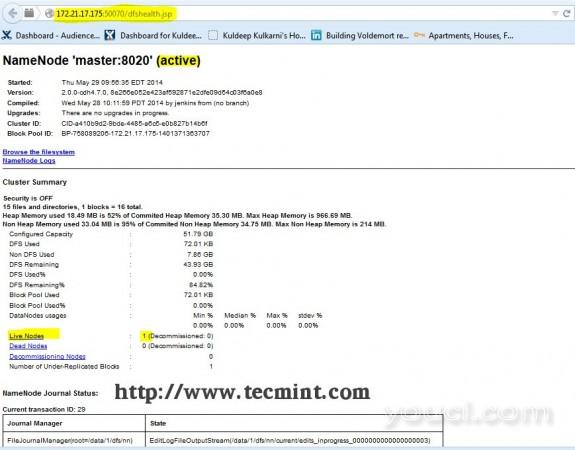
Hadoop NameNode接口
在浏览器中打开另一个选项卡,然后键入URL作为HTTP:// ip_address_of_jobtracker:50030访问JobTracker的。
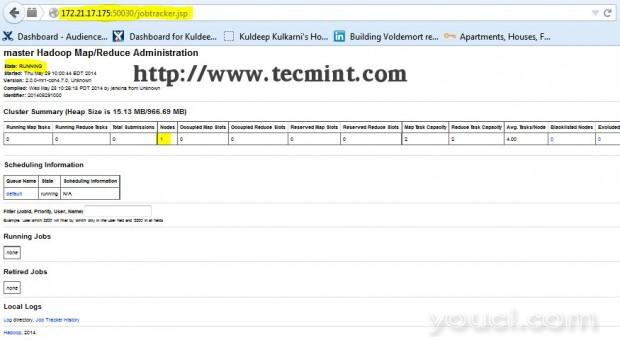
Hadoop映射/减少管理
这个程序在RHEL / CentOS的5.X / 6.X试验成功。 请在下面评论如果你面临任何安装问题,我会帮助你解决方案。







