Apache的Hadoop 2.6 稳定版本在2.XY版本中有显著的改善。这个版本在HDFS和MapReduce中有许多改进。本文将帮助你在CentOS/RHEL 7/6/5和Ubuntu系统中安装Hadoop 2.6。本文不包括的Hadoop的整体配置,我们要开始使用Hadoop的工作只需要基本的配置。

第1步:安装Java
Java是任何系统上运行Hadoop的主要的要求,因此,请确保您有使用下面的命令在系统上安装了Java。
# java -version
java version "1.8.0_66"
Java(TM) SE Runtime Environment (build 1.8.0_66-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.66-b17, mixed mode)
如果在您的系统上没有安装Java,使用下面的一个环节先安装它。
在CentOS / RHEL 7/6/5安装Java 8
在Ubuntu上安装Java 8
第2步:创建Hadoop用户
我们建议创建工作的Hadoop正常(nor root)账户。因此,使用以下命令创建一个系统帐号。
# adduser hadoop
# passwd hadoop
创建帐户后,还需要基于密钥的ssh设置为自己的账户。要做到这一点使用执行下面的命令。
# su - hadoop
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
让我们验证基于密钥登录。下面的命令不应该索要密码,但第一次会提示添加RSA已知主机列表。
$ ssh localhost
$ exit
第3步:下载的Hadoop 2.6.0
现在,使用下面的命令下载的Hadoop 2.6.0源存档文件。您也可以选择另外的
下载镜像提高下载速度。
$ cd ~
$ wget http://apache.claz.org/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
$ tar xzf hadoop-2.6.0.tar.gz
$ mv hadoop-2.6.0 hadoop
第4步:配置Hadoop的伪分布式模式
4.1。设置环境变量
首先,我们需要通过Hadoop的设置环境变量的用途。编辑
~/.bashrc 文件,并在文件末尾追加下面的值。
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
现在适用于当前运行环境的变化
$ source ~/.bashrc
现在编辑
$HADOOP_HOME/etc/Hadoop/hadoop-env.sh 文件,并设置
JAVA_HOME环境变量。更改Java路径,按您的系统上安装。
export JAVA_HOME=/opt/jdk1.8.0_66/
4.2。编辑配置文件
Hadoop的有很多的配置文件,这需要配置按你的Hadoop基础架构的需求。让我们开始基本的hadoop单节点集群安装的配置。首先导航到以下位置
$ cd $HADOOP_HOME/etc/hadoop
编辑核心的site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
编辑HDFS-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
编辑mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
编辑 yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.3。格式化 Namenode
现在,使用以下命令格式名称节点,确保存储目录
$ hdfs namenode -format
输出示例:
15/02/04 09:58:43 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = svr1.youcl.com/192.168.1.133
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.0
...
...
15/02/04 09:58:57 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
15/02/04 09:58:57 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
15/02/04 09:58:57 INFO util.ExitUtil: Exiting with status 0
15/02/04 09:58:57 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at svr1.youcl.com/192.168.1.133
************************************************************/
第5步:启动Hadoop集群
Hadoop集群提供了Hadoop启动脚本,让我们开始使用这些脚本。只要浏览到您的Hadoop sbin目录和一个执行脚本之一。
$ cd $HADOOP_HOME/sbin/
现在运行
start-dfs.sh脚本。
$ start-dfs.sh
输出示例:
15/02/04 10:00:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-namenode-svr1.youcl.com.out
localhost: starting datanode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-datanode-svr1.youcl.com.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
RSA key fingerprint is 3c:c4:f6:f1:72:d9:84:f9:71:73:4a:0d:55:2c:f9:43.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (RSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop/logs/hadoop-hadoop-secondarynamenode-svr1.youcl.com.out
15/02/04 10:01:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
现在运行
start-yarn.sh脚本。
$ start-yarn.sh
输出示例:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop/logs/yarn-hadoop-resourcemanager-svr1.youcl.com.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop/logs/yarn-hadoop-nodemanager-svr1.youcl.com.out
第6步:在浏览器中访问Hadoop服务
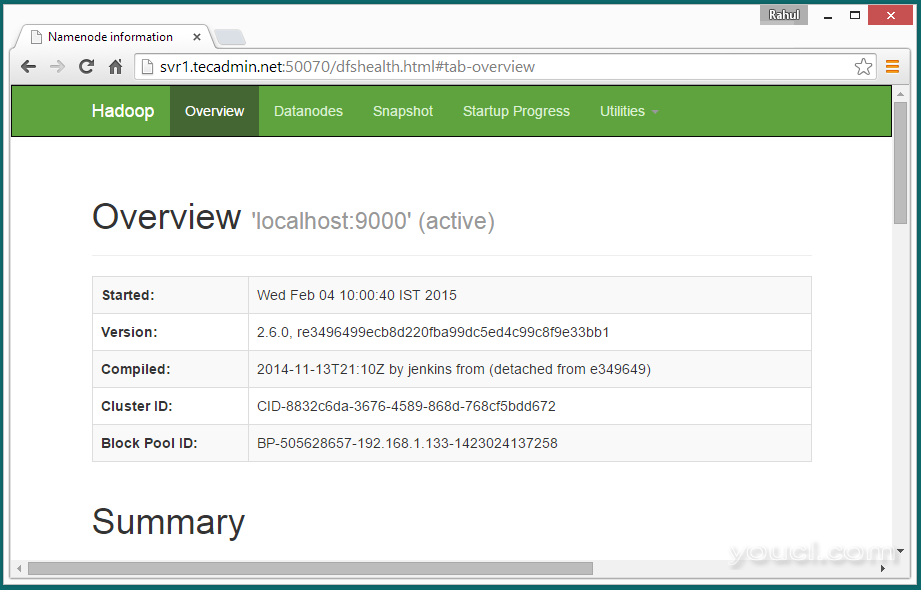
Hadoop的NameNode的开始端口50070默认值。访问端口50070的服务器在你喜欢的网页浏览器。
http://svr1.youcl.com:50070/
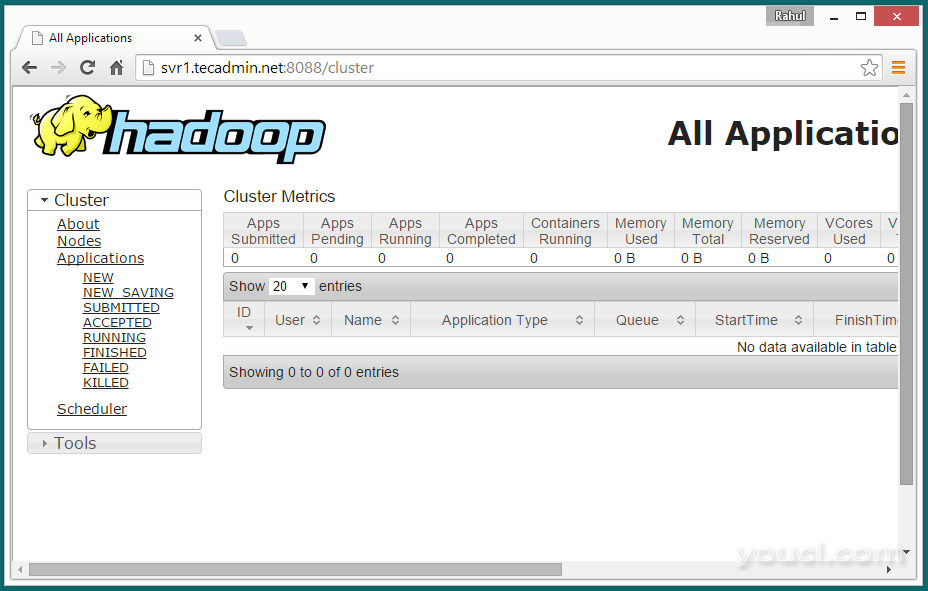
 现在访问端口8088用于获取有关群集和所有应用程序的信息
现在访问端口8088用于获取有关群集和所有应用程序的信息
http://svr1.youcl.com:8088/
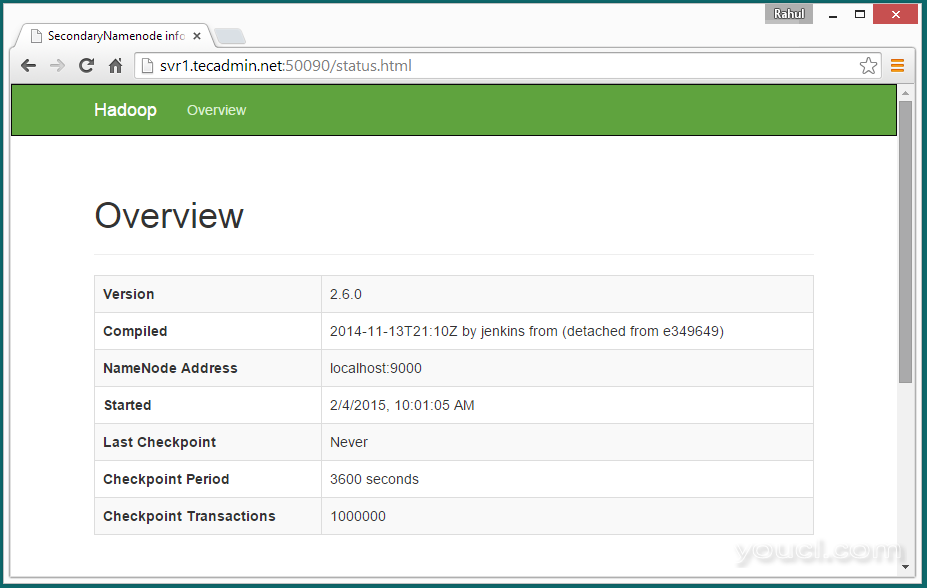
 访问端口50090用于获取有关二次NameNode的细节。
访问端口50090用于获取有关二次NameNode的细节。
http://svr1.youcl.com:50090/
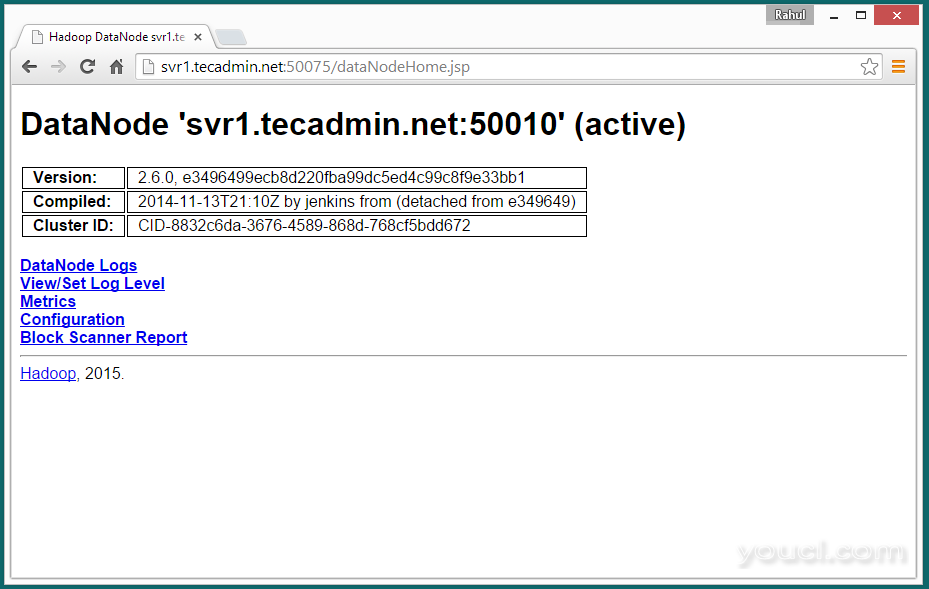
 访问端口50075,以获取有关的DataNode细节
访问端口50075,以获取有关的DataNode细节
http://svr1.youcl.com:50075/
第7步:测试Hadoop的单个节点设置
7.1 -请使用以下命令所需的HDFS目录。
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/hadoop
7.2 -现在所有的文件从本地文件系统中的 /var/log/httpd ,使用下面的命令来Hadoop分布式文件系统
$ bin/hdfs dfs -put /var/log/httpd logs
7.3 -现在通过在浏览器中打开下面的网址浏览Hadoop分布式文件系统。
http://svr1.youcl.com:50070/explorer.html#/user/hadoop/logs
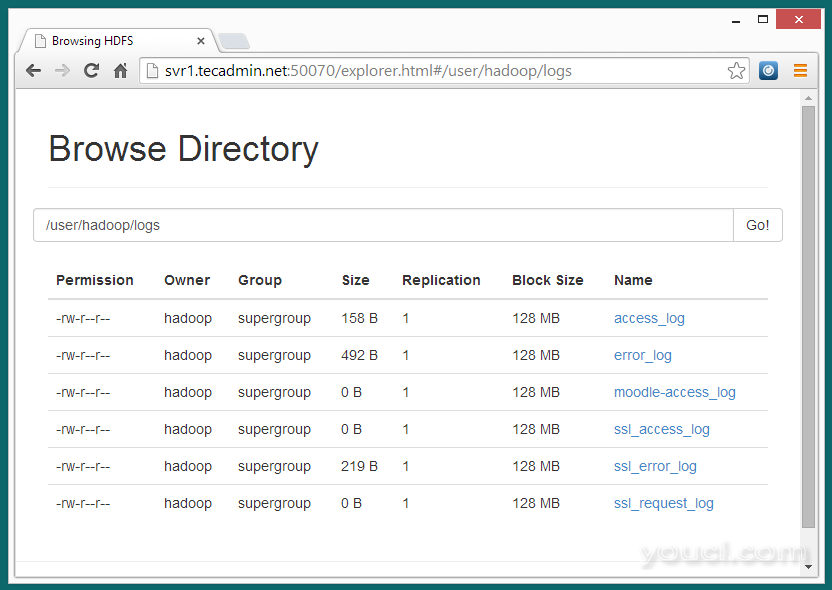 7.4 -现在复制日志目录Hadoop分布式文件系统到本地文件系统。
7.4 -现在复制日志目录Hadoop分布式文件系统到本地文件系统。
$ bin/hdfs dfs -get logs /tmp/logs
$ ls -l /tmp/logs/







