介绍
RethinkDB是的NoSQL数据库。 它有一个易于使用的API与数据库交互。 RethinkDB还使得设置数据库集群变得简单; 即服务于相同数据库和表的服务器组。 集群是一种轻松扩展数据库而无需停机的方法。
本教程将介绍如何设置集群,导入数据和确保安全。 如果你是新来RethinkDB,看基本在本教程中潜水前到更复杂的集群配置过程。
先决条件
本教程需要至少2Droplet运行Ubuntu LTS 14.04名为rethink1&rethink2(这些名称将在本教程中使用)。 你应该设置一个非根Sudo用户对每个Droplet设立RethinkDB之前-这样做是一个良好的安全习惯。
本教程还引用了Python客户端驱动程序,这是在解释本教程 。
设置节点
RethinkDB中的簇没有特殊的节点; 它是一个纯对等网络。 在我们可以配置集群之前,我们需要安装RethinkDB。 在每个服务器上,从您的主目录,将RethinkDB密钥和存储库添加到apt-get:
source /etc/lsb-release && echo "deb http://download.rethinkdb.com/apt $DISTRIB_CODENAME main" | sudo tee /etc/apt/sources.list.d/rethinkdb.list
wget -qO- http://download.rethinkdb.com/apt/pubkey.gpg | sudo apt-key add -
然后更新apt-get并安装RethinkDB:
sudo apt-get update
sudo apt-get install rethinkdb
接下来,我们需要设置RethinkDB在启动时运行。 RethinkDB附带一个脚本在启动时运行,但该脚本需要启用:
sudo cp /etc/rethinkdb/default.conf.sample /etc/rethinkdb/instances.d/cluster_instance.conf
启动脚本还用作配置文件。 让我们打开这个文件:
sudo nano /etc/rethinkdb/instances.d/cluster_instance.conf
机器的名称(在Web管理控制台和日志文件中的名称)在此文件中设置。 让我们通过找到行(在最底部)使它与机器的主机名相同:
# machine-name=server1
并将其更改为:
machine-name=rethink1
(注意:如果您在第一次启动RethinkDB之前未设置名称,它将自动设置一个以DOTA为主题的名称。)
设置RethinkDB所以它可以从所有网络接口通过查找以下行:
# bind=127.0.0.1
并将其更改为:
bind=all
保存配置并关闭纳米(按Ctrl-X ,然后Y ,然后Enter )。 我们现在可以使用新的配置文件启动RethinkDB:
sudo service rethinkdb start
您应该看到这个输出:
rethinkdb: cluster_instance: Starting instance. (logging to `/var/lib/rethinkdb/cluster_instance/data/log_file')
RethinkDB现在已启动并正在运行。
保护RethinkDB
我们已经打开了bind=all选项,使得从服务器外部RethinkDB访问。 这是不安全的。 所以,我们将需要阻止RethinkDB从互联网。 但我们需要允许从授权的计算机访问其服务。
对于集群端口,我们将使用防火墙封装我们的集群。 对于Web管理控制台和驱动程序端口,我们将使用SSH隧道从服务器外部访问它们。 SSH隧道通过SSH将客户端计算机上的请求重定向到远程计算机,使客户端能够访问仅在远程服务器的本地主机名称空间上可用的所有服务。
在所有RethinkDB服务器上重复这些步骤。
首先,阻止所有外部连接:
# The Web Management Console
sudo iptables -A INPUT -i eth0 -p tcp --dport 8080 -j DROP
sudo iptables -I INPUT -i eth0 -s 127.0.0.1 -p tcp --dport 8080 -j ACCEPT
# The Driver Port
sudo iptables -A INPUT -i eth0 -p tcp --dport 28015 -j DROP
sudo iptables -I INPUT -i eth0 -s 127.0.0.1 -p tcp --dport 28015 -j ACCEPT
# The Cluster Port
sudo iptables -A INPUT -i eth0 -p tcp --dport 29015 -j DROP
sudo iptables -I INPUT -i eth0 -s 127.0.0.1 -p tcp --dport 29015 -j ACCEPT
有关配置获取更多相关信息,请查看本教程 。
让我们安装“iptables-persistent”来保存我们的规则:
sudo apt-get update
sudo apt-get install iptables-persistent
您将看到如下所示的菜单:
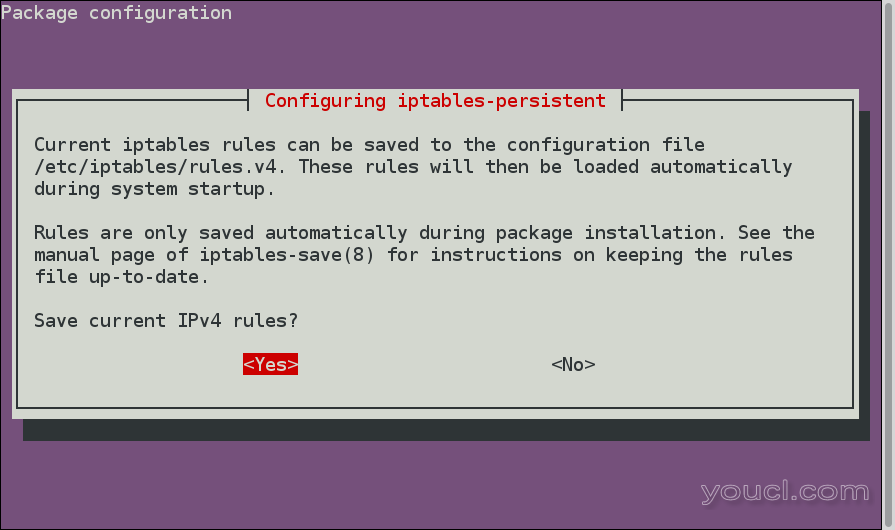
选择Yes选项(按Enter )来保存防火墙规则。 您还将看到有关IPv6规则的类似菜单,您也可以保存它。
设置管理用户
要访问RethinkDB的Web管理控制台和驱动程序界面,我们需要设置SSH隧道。 让我们创建对rethink1 SSH通道新用户:
sudo adduser ssh-to-me
然后为我们的新用户设置授权密钥文件:
sudo mkdir /home/ssh-to-me/.ssh
sudo touch /home/ssh-to-me/.ssh/authorized_keys
如果您在使用SSH连接到云服务器上,打开本地计算机上的终端。 如果你不是,你可能想 。 获取您的公钥并将其复制到剪贴板:
cat ~/.ssh/id_rsa.pub
然后,通过在服务器上打开authorized_keys文件添加关键新帐户:
sudo nano /home/ssh-to-me/.ssh/authorized_keys
将您的密钥粘贴到文件中。 然后保存并关闭纳米( Ctrl-X那么Y ,然后Enter )。
您需要为其他集群节点重复所有这些步骤。
导入或创建数据库
您可能希望将预先存在的数据库导入到集群中。 仅当您在另一个服务器上或此服务器上具有预先存在的数据库时,才需要这样做; 否则,RethinkDB会自动创建一个空数据库。
如果需要导入外部数据库:
如果你想导入数据库不存储在rethink1 ,你需要跨复制。 首先,找到当前RethinkDB数据库的路径。 这将是自动创建rethinkdb_data目录,如果你使用了rethinkdb命令来启动你的旧数据库。 然后,复制使用它scp上rethink1:
sudo scp -rpC From Server User@From Server IP:/RethinkDB Data Folder/* /var/lib/rethinkdb/cluster_instance/data
例如:
sudo scp -rpC root@111.222.111.222:/home/user/rethinkdb_data/* /var/lib/rethinkdb/cluster_instance/data
然后重新启动RethinkDB:
sudo service rethinkdb restart
如果您在rethink1上有现有数据库:
如果您有rethink1现有RethinkDB数据库,这个过程是不同的。 首先打开rethink1配置文件:
sudo nano /etc/rethinkdb/instances.d/cluster_instance.conf
然后,找到要导入的RethinkDB数据库的路径。 这将是自动创建rethinkdb_data目录,如果你使用了rethinkdb命令来启动你的旧数据库。 通过添加以下行将该路径插入配置文件:
directory=/home/user/rethink/rethinkdb_data/
关闭文件保存修改(使用Ctrl-X然后Y ,然后Enter )。 现在重启RethinkDB:
sudo service rethinkdb restart
需要注意的是导入一个已经存在的数据库将意味着rethink1将继承数据库的旧机器的名字是很重要的。 在以后管理数据库的分片时,您需要知道这一点。
创建集群
为了创建集群,您需要允许所有集群机器通过彼此的防火墙。 在您的rethink1机,添加一个iptables规则允许通过防火墙的其他节点。 在这个例子中,应更换rethink2 IP与服务器的IP地址:
sudo iptables -I INPUT -i eth0 -s rethink2 IP -p tcp --dport 29015 -j ACCEPT
对要添加的任何其他节点重复此命令。
然后保存防火墙规则:
sudo sh -c "iptables-save > /etc/iptables/rules.v4"
然后对其他节点重复这些步骤。 对于双服务器设置,您现在应该连接到rethink2和解锁rethink1的IP。
现在,您需要连接所有节点以创建集群。 使用SSH连接到rethink2并打开配置文件:
sudo nano /etc/rethinkdb/instances.d/cluster_instance.conf
在join选项指定要加入群集的地址。 发现join配置文件中的行:
# join=example.com:29015
并将其替换为:
join=rethink1 IP
保存并关闭配置文件(使用Ctrl-X然后Y ,然后Enter )。 然后重新启动RethinkDB:
sudo service rethinkdb restart
第一点,rethink1,不需要join更新。 重复上所有其它节点的配置文件编辑,除了rethink1。
你现在有一个完全运行的RethinkDB集群!
连接到Web管理控制台
Web管理控制台是一个易于使用的在线界面,允许访问RethinkDB的基本管理功能。 当需要查看集群的状态,运行单个RethinkDB命令和更改基本表设置时,此控制台很有用。
集群中的每个RethinkDB实例都在提供一个管理控制台,但这只能从服务器的本地主机名称空间获得,因为我们使用防火墙规则阻止它从世界其他地方。 我们可以使用SSH隧道来我们的请求重定向localhost:8080至rethink1,这将发送到请求的localhost:8080它的名字空间内。 这将允许您访问Web管理控制台。 为此,您可以使用SSH在本地计算机上:
ssh -L 8080:localhost:8080 ssh-to-me@rethink1 IP
如果你去到本地主机:8080在浏览器中,你将看到你的RethinkDB Web管理控制台。
如果您收到一个bind: Address already in use错误,您正在使用您的计算机上的8080端口。 您可以将Web管理控制台转发到不同的端口,在您的计算机上可用。 例如,你可以转发到端口8081,然后转到本地主机:8081 :
ssh -L 8081:localhost:8080 ssh-to-me@rethink1 IP
如果您看到有关有两个测试数据库的冲突,可以重命名其中一个。
使用Python驱动程序连接到群集
在此设置中,所有RethinkDB服务器(Web管理控制台,驱动程序端口和群集端口)都与外部世界隔离。 我们可以使用SSH隧道连接到驱动程序端口,就像使用Web管理控制台一样。 驱动程序端口是RethinkDB API驱动程序(您构建应用程序的连接)如何连接到您的群集。
首先,选择要连接的节点。 如果您有多个客户端(例如,Web应用程序服务器)连接到群集,您将需要在群集之间进行平衡。 最好写一个客户端列表,然后为每个客户端分配一个服务器。 尝试对客户端进行分组,因此需要类似表的客户端连接到同一个云服务器或一组服务器,因此没有服务器因许多客户端而过载。
在这个例子中,我们将使用rethink2作为我们的连接服务器。 但是,在一个更大的系统中,数据库和Web应用程序服务器是分开的,您需要从实际进行数据库调用的Web应用程序服务器执行此操作。
然后, 连接服务器上生成SSH密钥:
ssh-keygen -t rsa
并将其复制到剪贴板:
cat ~/.ssh/id_rsa.pub
然后通过打开授权群集节点上的新的密钥(在这个例子中,rethink1) authorized_keys文件并粘贴在新的一行的关键是:
sudo nano /home/ssh-to-me/.ssh/authorized_keys
关闭nano和保存文件( Ctrl-X然后Y ,然后Enter )。
接下来,使用SSH隧道来访问驱动器端口,从连接SEVER:
ssh -L 28015:localhost:28015 ssh-to-me@Cluster Node IP -f -N
驱动程序现在可以从本地主机访问:28015。 如果你得到一个bind: Address already in use错误,您可以更改端口。 例如,使用端口28016:
ssh -L 28016:localhost:28015 ssh-to-me@Cluster Node IP -f -N
安装连接服务器上的Python驱动程序。 还有的命令的快速运行经过这里,您可以更详细地了解他们的这个教程 。
安装Python虚拟环境:
sudo apt-get install python-virtualenv
让~/rethink目录:
cd ~
mkdir rethink
移动到目录并创建新的虚拟环境结构:
cd rethink
virtualenv venv
激活环境(您必须在启动Python界面之前每次激活环境,否则您将收到有关缺少模块的错误):
source venv/bin/activate
安装RethinkDB模块:
pip install rethinkdb
现在从连接的服务器启动的Python:
python
连接到数据库,确保更换28015与你所使用的端口,如果需要的话:
import rethinkdb as r
r.connect("localhost", 28015).repl()
创建表test :
r.db("test").table_create("test").run()
将数据插入表中test :
r.db("test").table("test").insert({"hello":"world"}).run()
r.db("test").table("test").insert({"hello":"world number 2"}).run()
并打印出数据:
list(r.db("test").table("test").run())
您应该看到类似以下的输出:
[{u'hello': u'world number 2', u'id': u'0203ba8b-390d-4483-901d-83988e6befa1'},
{u'hello': u'world', u'id': u'7d17cd96-0b03-4033-bf1a-75a59d405e63'}]
设置分片
在RethinkDB中,您可以配置要在多个云服务器之间进行分片(拆分)的表。 分片是一种容易的方式,使数据集大于适合单个机器的RAM的数据集的性能良好,因为更多的RAM可用于缓存。 由于分片还将数据集分割在多台计算机上,因此可以使用更大,性能更低的表,因为表可用的磁盘空间更多。 这可以通过Web管理控制台完成。
要做到这一点,请在Web管理控制台中的表选项卡。
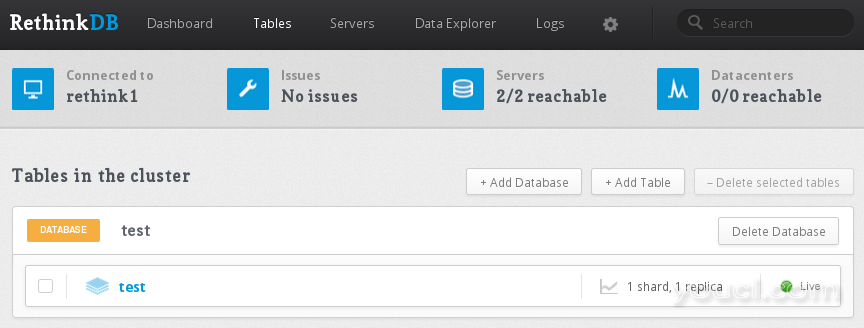
点击测试表(我们在上一节中创建的)进入其设置。 向下滚动到分片设置卡。
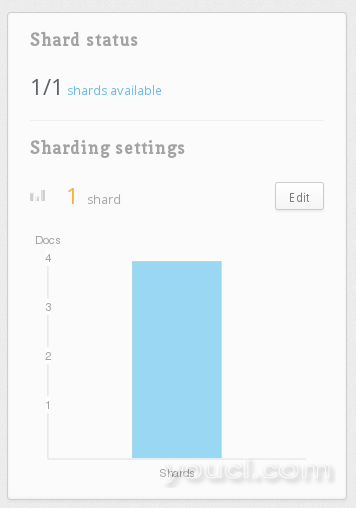
单击编辑按钮。 在那里,您可以输入拆分表的服务器数量。 在这个例子中输入2。 点击再平衡按钮保存设置。
您可能会注意到,您可以拥有的碎片数量最多。 这等于数据库中的文档数。 如果您试图为新表设置分片,则需要等待更多数据或添加虚拟数据,以允许您添加更多分片。
高级拆分
在内部,RethinkDB具有基于范围的碎片,基于文档ID。 这意味着如果我们有一个ID为A,B,C和D的数据集,RethinkDB可能会将其拆分为2个分片:A,B(无穷大到C)和C,D(C到+无穷大)。 如果要插入ID为A1的文档,它将在第一个碎片的范围(-infinity到C)内,因此它将进入该碎片。 我们可以设置碎片的边界,这可以优化您的数据库配置。
在我们可以做到这一点之前,我们将添加一个数据集来玩。 在Web管理控制台的数据浏览器选项卡中,我们可以运行以下命令创建一个表(点击运行键入后):
r.db('test').tableCreate('testShards')
然后插入我们的测试数据:
r.db("test").table("testShards").insert([
{id:"A"},
{id:"B"},
{id:"C"},
{id:"D"},
{id:"E"}])
现在我们可以详细配置碎片。 为此,我们需要输入管理外壳。 管理外壳是更高级的控制集群的方法,允许您微调设置。 在rethink1机,打开管理外壳:
rethinkdb admin
然后我们可以查看有关我们的表的一些信息:
ls test.testShards
预期输出:
table 'testShards' b91fda27-a9f1-4aeb-bf6c-a7a4211fb674
...
1 replica for 1 shard
shard machine uuid name primary
-inf-+inf 91d89c12-01c7-487f-b5c7-b2460d2da22e rethink1 yes
在RethinkDB中有很多方法来命名表。 您可以使用database.name ( test.testShards ),姓名( testShards )或表UUID( e780f2d2-1baf-4667-b725-b228c7869aab )。 这些都可以互换使用。
让我们分割这个碎片。 我们将做2个碎片: - 无穷到C和C到+无穷:
split shard test.testShards C
命令的通用形式是:
split shard TABLE SPLIT-POINT
运行ls testShards再次显示碎片被拆分。 您可能需要将新的分片从一台机器移动到另一台机器。 在这个例子中,我们可以固定(移动)碎片-inf-C (-infinty至C)的机器rethink2:
pin shard test.testShards -inf-C --master rethink2
命令的通用形式是:
pin shard TABLE SHARD-RANGE --master MACHINE-NAME
如果ls testShards再次,你应该看到碎片已经移动到另一台服务器。
如果我们知道公共边界,我们也可以合并2个碎片。 让我们合并我们刚刚做的碎片(-infinity到C和C到+ infinity):
merge shard test.testShards C
命令的通用形式是:
merge shard TABLE COMMON-BOUNDARY
要退出外壳,类型exit
安全拆卸机器
当文档在多台计算机上分割时,一台计算机将始终保持其主索引。 如果具有特定文档的主索引的云服务器脱机,则文档将丢失。 因此,在删除计算机之前,应该将所有主分片迁移到远离它的位置。
在这个例子中,我们会尽量将数据迁移关闭节点rethink2离开rethink1作为唯一节点。
上输入rethink1的RethinkDB管理外壳:
rethinkdb admin
首先,让我们列出碎片(文件组)rethink2负责:
ls rethink2
你的输出应该是这样:
machine 'rethink2' bc2113fc-efbb-4afc-a2ed-cbccb0c55897
in datacenter 00000000-0000-0000-0000-000000000000
hosting 1 replicas from 1 tables
table name shard primary
b91fda27-a9f1-4aeb-bf6c-a7a4211fb674 testShards -inf-+inf yes
这表明rethink2负责表的id为“bdfceefb-5ebe-4ca6-b946-869178c51f93”初级碎片。 接下来,我们将移动这个碎片到rethink1。 这被称为钉扎:
pin shard test.testShards -inf-+inf --master rethink1
命令的通用形式是:
pin shard TABLE SHARD-RANGE --master MACHINE-NAME
如果你现在运行ls rethink1您将看到碎片已被转移到该机器。 每隔碎片已经从rethink2搬到rethink1,你应该退出管理外壳:
exit
现在可以安全地在不需要的服务器上停止RethinkDB。 重要提示:您要删除的计算机上运行此。 在这个例子中,我们将在rethink2运行如下命令:
sudo service rethinkdb stop
下次访问Web管理控制台时,RethinkDB将显示明亮的红色警告。 单击解决问题 。
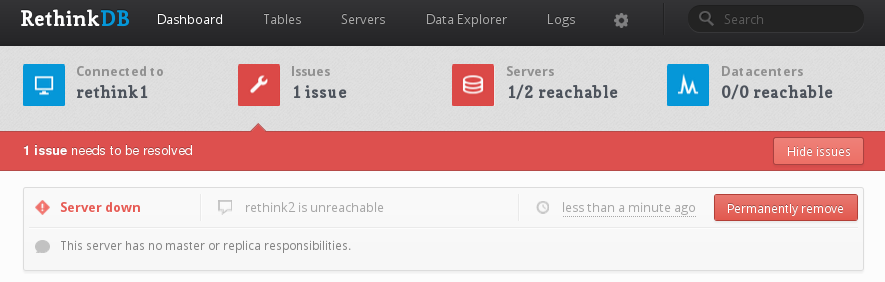
如果显示的问题看起来像上面的,并没有主职责列,点击永久删除 。 这将从群集中删除计算机。 如果列出任何主的责任,转RethinkDB回( sudo service rethinkdb start ),并确保你每一次的碎片迁移关闭该服务器。
注意:如果尝试将计算机重新添加到群集,您将看到有关僵尸计算机的消息。 您可以删除数据目录以纠正此问题:
sudo rm -r /var/lib/rethinkdb/cluster_instance/
sudo service rethinkdb restart







