介绍
本教程将介绍在DigitalOcean上设置Hadoop集群。 Hadoop软件库是一个Apache框架,通过利用基本的编程模型,您可以跨服务器群集以分布式方式处理大型数据集。 Hadoop提供的可扩展性允许您从单台服务器扩展到数千台机器。 它还在应用层提供故障检测功能,因此它可以将故障作为高可用性服务进行检测和处理。
我们将在本教程中使用4个重要模块:
- Hadoop Common是支持其他Hadoop模块所需的常用实用程序和库的集合。
- 如Apache组织所述, Hadoop分布式文件系统(HDFS)是一种高度容错的分布式文件系统,专门设计用于在商品硬件上运行以处理大型数据集。
- Hadoop YARN是用于作业调度和群集资源管理的框架。
- Hadoop MapReduce是一个用于并行处理大型数据集的基于YARN的系统。
在本教程中,我们将在四个DigitalOcean Droplet上设置并运行Hadoop集群。
先决条件
本教程将需要以下内容:
四个非root sudo用户设置的Ubuntu 16.04 Droplet。 如果您没有安装此设置,请遵循Ubuntu 16.04初始服务器设置的第1步-4。 本教程将假定您正在使用本地机器上的SSH密钥。 按照Hadoop的语言,我们将通过以下名称来引用这些Droplet:
hadoop-master-
hadoop-worker-01 -
hadoop-worker-02 -
hadoop-worker-03
此外,您可能希望在初始服务器设置完成并完成第一个Droplet的第1步和2 (如下)后使用DigitalOcean快照 。
有了这些先决条件,您就可以开始设置Hadoop集群了。
第1步 - 每个Droplet的安装设置
我们将在我们的四个 Droplet上安装Java和Hadoop。 如果您不想在每个Droplet上重复每个步骤,则可以在第2步结束时使用DigitalOcean快照 ,以复制初始安装和配置。
首先,我们将使用最新的软件补丁程序更新Ubuntu:
sudo apt-get update && sudo apt-get -y dist-upgrade
接下来,让我们在每个Droplet上安装Ubuntu的Java无头版本。 “无头”是指能够在没有图形用户界面的情况下在设备上运行的软件。
sudo apt-get -y install openjdk-8-jdk-headless
要在每个Droplet上安装Hadoop,让我们创建安装Hadoop的目录。 我们可以称之为my-hadoop-install ,然后进入该目录。
mkdir my-hadoop-install && cd my-hadoop-install
一旦我们创建了目录,让我们从Hadoop版本列表中安装最新的二进制文件。 在本教程发布时,最新的是Hadoop 3.0.1 。
注意 :请记住,这些下载是通过镜像站点分发的,建议首先检查是否使用GPG或SHA-256进行篡改。
当您对所选的下载感到满意时,可以使用带有所选二进制链接的wget命令,例如:
wget http://mirror.cc.columbia.edu/pub/software/apache/hadoop/common/hadoop-3.0.1/hadoop-3.0.1.tar.gz
下载完成后,使用tar文件解压缩文件内容,这是Ubuntu的文件归档工具:
tar xvzf hadoop-3.0.1.tar.gz
我们现在准备开始我们的初始配置。
第2步 - 更新Hadoop环境配置
对于每个Droplet节点,我们需要设置JAVA_HOME 。 使用您选择的nano或其他文本编辑器打开以下文件,以便我们可以更新它:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hadoop-env.sh
更新JAVA_HOME所在的以下部分:
...
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
# export JAVA_HOME=
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
# export HADOOP_HOME=
...
看起来像这样:
...
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
# export HADOOP_HOME=
...
我们还需要添加一些环境变量来运行Hadoop及其模块。 应该将它们添加到文件的底部,使其看起来像以下内容,其中sammy将是您的sudo非root用户的用户名。
注意 :如果您在群集Droplet中使用不同的用户名,则需要编辑此文件以反映每个特定Droplet的正确用户名。
...
#
# To prevent accidents, shell commands be (superficially) locked
# to only allow certain users to execute certain subcommands.
# It uses the format of (command)_(subcommand)_USER.
#
# For example, to limit who can execute the namenode command,
export HDFS_NAMENODE_USER="sammy"
export HDFS_DATANODE_USER="sammy"
export HDFS_SECONDARYNAMENODE_USER="sammy"
export YARN_RESOURCEMANAGER_USER="sammy"
export YARN_NODEMANAGER_USER="sammy"
此时,您可以保存并退出文件。 接下来,运行以下命令来应用我们的输出:
source ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hadoop-env.sh
通过更新hadoop-env.sh脚本,我们需要为Hadoop分布式文件系统(HDFS)创建一个数据目录来存储所有相关的HDFS文件。
sudo mkdir -p /usr/local/hadoop/hdfs/data
与各自的用户设置此文件的权限。 请记住,如果您在每个Droplet上有不同的用户名,请确保允许您各自的sudo用户拥有这些权限:
sudo chown -R sammy:sammy /usr/local/hadoop/hdfs/data
如果您想使用DigitalOcean快照在Droplet节点上复制这些命令,则可以立即创建快照并从该图像创建新的Droplet。 有关这方面的指导,您可以阅读DigitalOcean快照简介 。
当您在所有四个 Ubuntu Droplet中完成上述步骤时,您可以继续跨节点完成此配置。
第3步 - 完成每个节点的初始配置
此时,我们需要更新所有4个Droplet节点的core_site.xml文件。 在每个Droplet中,打开以下文件:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/core-site.xml
你应该看到以下几行:
...
<configuration>
</configuration>
将文件更改为如下所示的XML,以便我们将每个Droplet的IP分别包含在属性值内,我们在其中编写了server-ip 。 如果您使用防火墙,则需要打开端口9000。
...
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://server-ip:9000</value>
</property>
</configuration>
在所有四台服务器的相关Droplet IP中重复上述写作。
现在,应该为每个服务器节点更新所有常规Hadoop设置,并且我们可以继续通过SSH密钥连接我们的节点。
第4步 - 为每个节点设置SSH
为了使Hadoop正常工作,我们需要在主节点和工作节点之间设置无密码SSH( master服务器和secondary服务器的语言是Hadoop的语言,用于引用primary服务器和secondary服务器)。
在本教程中,主节点将是hadoop-master ,工作节点将统称为hadoop-worker ,但总共有三个(分别称为-01 , -02和-03 ) 。 我们首先需要在主节点上创建一个公钥 - 私钥对,该节点将成为IP地址属于hadoop-master的节点。
在hadoop-master Droplet上运行以下命令。 您将按Enter键使用关键位置的默认值,然后按两次Enter键以使用空的密码短语:
ssh-keygen
对于每个工作节点,我们需要获取主节点的公钥并将其复制到每个工作节点的authorized_keys文件中。
通过在位于.ssh文件夹中的id_rsa.pub文件上运行cat来从主节点获取.ssh ,以打印到控制台:
cat ~/.ssh/id_rsa.pub
现在登录到每个工作节点Droplet,然后打开authorized_keys文件:
nano ~/.ssh/authorized_keys
您将复制主节点的公钥(这是您从主节点上的cat ~/.ssh/id_rsa.pub命令生成的输出)到每个Droplet各自的~/.ssh/authorized_keys文件中。 确保在关闭前保存每个文件。
完成3个工作节点的更新后,还可以通过发出相同的命令将主节点的公钥复制到其自己的authorized_keys文件中:
nano ~/.ssh/authorized_keys
在hadoop-master ,您应该设置ssh配置以包含相关节点的每个主机名。 使用nano打开配置文件进行编辑:
nano ~/.ssh/config
您应该修改该文件,使其类似于以下内容,并添加了相关的IP和用户名。
Host hadoop-master-server-ip
HostName hadoop-example-node-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-01-server-ip
HostName hadoop-worker-01-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-02-server-ip
HostName hadoop-worker-02-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-03-server-ip
HostName hadoop-worker-03-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
保存并关闭文件。
从hadoop-master ,SSH到每个节点:
ssh sammy@hadoop-worker-01-server-ip
由于这是您第一次在设置了当前系统的情况下登录到每个节点,它会向您询问以下内容:
Outputare you sure you want to continue connecting (yes/no)?
回答是的提示。 这将是唯一需要完成的时间,但每个工作节点都需要进行初始SSH连接。 最后,注销每个工作节点以返回到hadoop-master :
logout
请务必为其余两个工作节点重复这些步骤 。
现在我们已经为每个工作节点成功设置了无密码SSH,现在我们可以继续配置主节点。
第5步 - 配置主节点
对于我们的Hadoop集群,我们需要在主节点Droplet上配置HDFS属性。
在主节点上时,编辑以下文件:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hdfs-site.xml
编辑configuration部分,使其看起来像下面的XML:
...
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/hdfs/data</value>
</property>
</configuration>
保存并关闭文件。
接下来我们将在主节点上配置MapReduce属性。 用nano或其他文本编辑器打开mapred.site.xml :
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/mapred-site.xml
然后更新文件,使其看起来像这样,其中当前服务器的IP地址如下所示:
...
<configuration>
<property>
<name>mapreduce.jobtracker.address</name>
<value>hadoop-master-server-ip:54311</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
保存并关闭文件。 如果您使用的是防火墙,请确保打开端口54311。
接下来,在主节点上设置YARN。 同样,我们正在更新另一个XML文件的配置部分,因此我们打开该文件:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/yarn-site.xml
现在更新文件,确保输入您当前服务器的IP地址:
...
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master-server-ip</value>
</property>
</configuration>
最后,让我们配置Hadoop的参考点,以确定主节点和工作节点应该是什么。 首先,打开masters文件:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/masters
在此文件中,您将添加当前服务器的IP地址:
hadoop-master-server-ip
现在,打开并编辑workers文件:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/workers
在这里,您将添加每个工作节点的IP地址,它位于localhost下方。
localhost
hadoop-worker-01-server-ip
hadoop-worker-02-server-ip
hadoop-worker-03-server-ip
完成MapReduce和YARN属性的配置后,我们现在可以完成对工作节点的配置。
第6步 - 配置工作节点
现在我们将配置工作节点,以便它们每个都有对HDFS数据目录的正确引用。
在每个工作节点上 ,编辑这个XML文件:
nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hdfs-site.xml
将配置部分替换为以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/hdfs/data</value>
</property>
</configuration>
保存并关闭文件。 请务必在所有三个工作节点上复制此步骤。
此时,我们的工作节点Droplets正在指向HDFS的数据目录,这将允许我们运行我们的Hadoop集群。
第7步 - 运行Hadoop集群
我们已经达到了可以启动Hadoop集群的程度。 在我们启动之前,我们需要在主节点上格式化HDFS。 在主节点Droplet上,将目录切换到Hadoop的安装位置:
cd ~/my-hadoop-install/hadoop-3.0.1/
然后运行以下命令格式化HDFS:
sudo ./bin/hdfs namenode -format
一个成功的namenode格式化将产生大量的输出,主要由INFO语句组成。 在底部,您将看到以下内容,确认您已成功格式化存储目录。
Output...
2018-01-28 17:58:08,323 INFO common.Storage: Storage directory /usr/local/hadoop/hdfs/data has been successfully formatted.
2018-01-28 17:58:08,346 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/hdfs/data/current/fsimage.ckpt_0000000000000000000 using no compression
2018-01-28 17:58:08,490 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/hdfs/data/current/fsimage.ckpt_0000000000000000000 of size 389 bytes saved in 0 seconds.
2018-01-28 17:58:08,505 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2018-01-28 17:58:08,519 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-example-node/127.0.1.1
************************************************************/
现在,通过运行以下脚本启动Hadoop集群(请确保在运行之前使用less命令检查脚本):
sudo ./sbin/start-dfs.sh
您将看到包含以下内容的输出:
OutputStarting namenodes on [hadoop-master-server-ip]
Starting datanodes
Starting secondary namenodes [hadoop-master]
然后使用以下脚本运行YARN:
./sbin/start-yarn.sh
将显示以下输出:
OutputStarting resourcemanager
Starting nodemanagers
一旦你运行这些命令,你应该在主节点上运行守护进程,并在每个工作节点上运行守护进程。
我们可以通过运行jps命令来检查守护进程以检查Java进程:
jps
运行jps命令后,您将看到NodeManager , SecondaryNameNode , Jps , NameNode , ResourceManager和DataNode正在运行。 会出现类似于以下输出的内容:
Output9810 NodeManager
9252 SecondaryNameNode
10164 Jps
8920 NameNode
9674 ResourceManager
9051 DataNode
这验证我们已经成功创建了一个集群并验证了Hadoop守护进程正在运行。
在您选择的网络浏览器中,您可以浏览至以下网址,以了解群集的健康状况:
http://hadoop-master-server-ip:9870
如果您有防火墙,请确保打开端口9870.您将看到类似于以下内容的内容:
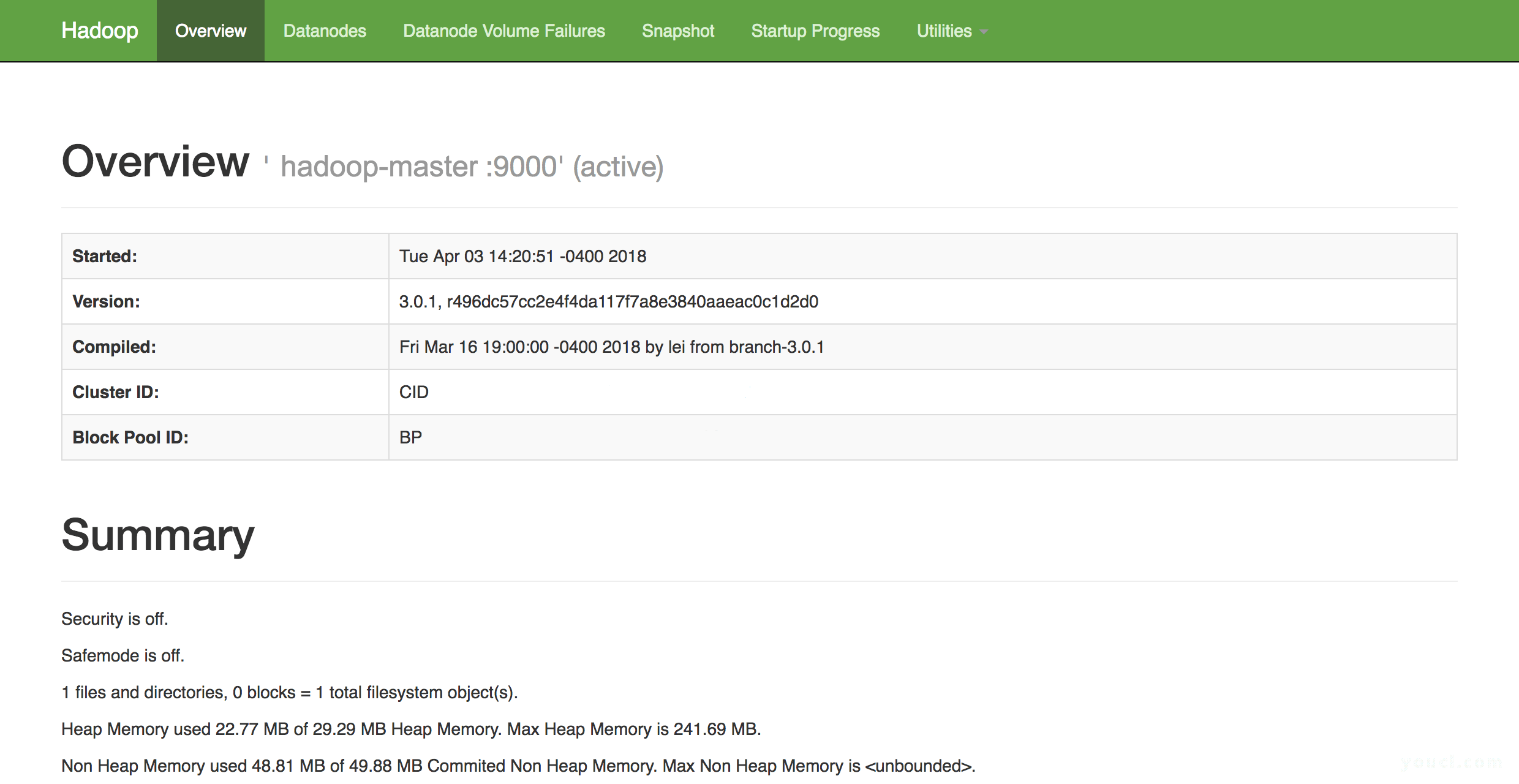
从这里,您可以导航到菜单栏中的Datanodes项目以查看节点活动。
结论
在本教程中,我们回顾了如何使用DigitalOcean Ubuntu 16.04 Droplets设置和配置Hadoop多节点群集。 您现在还可以使用Hadoop的DFS健康Web界面来监视和检查群集的健康状况。
要了解可以使用新配置集群的项目,请查看Apache的Hadoop强大项目列表。







