本教程将帮助您在Hadoop中使用命令行运行一个单词计数MapReduce的例子。这可能也为你的Hadoop设置测试的初步测试。
1. 先决条件
你必须在你的系统上运行Hadoop设置。如果您没有安装Hadoop访问
Linux上Hadoop的安装教程。
2. 将文件复制到Namenode文件系统
成功格式化名称节点之后,您必须有正确启动所有的Hadoop服务。现在创建Hadoop中文件系统的目录。
$ hdfs dfs -mkdir -p /user/hadoop/input
复制拷贝一些文本文件的Hadoop文件系统输入目录内。在这里,我复制LICENSE.txt。您可以复制一个以上的文件。
$ hdfs dfs -put LICENSE.txt /user/hadoop/input/
3. 运行Wordcount命令
现在运行使用以下命令单词计数mapreduce的例子。下面命令将读取输入文件夹和进程MapReduce的jar文件中的所有文件。后任务结果的成功完成将被放置在输出目录。
$ cd $HADOOP_HOME
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount input output
4. 显示结果
首先检查使用下面的命令下,dfs@/user/hadoop/output 文件系统的结果文件的名称。
$ hdfs dfs -ls /user/hadoop/output
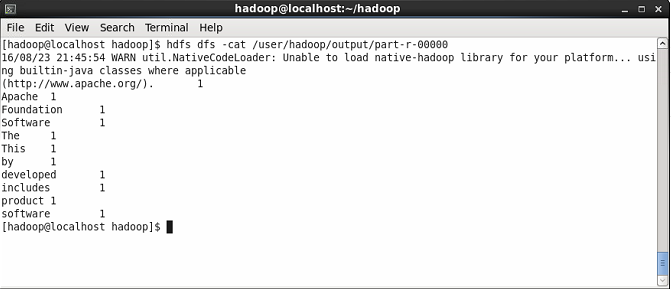
现在显示结果文件的内容,在那里你会看到单词计数的结果。你会看到每个单词的计数。
$ hdfs dfs -cat /user/hadoop/output/part-r-00000